Chapter: Medicine Study Notes : Evidence Based Medicine
Evaluation of History Taking and Clinical Examination
Evaluation of History Taking and Clinical Examination
Using an article about history taking or clinical examination
·
Is the evidence about the
accuracy of a diagnostic test valid?
o Was there an independent, blind comparison with a reference standard?
o Did the patient sample include an appropriate spectrum of patients to whom the diagnostic test will be applied in clinical practice
o Did the results of the test being evaluated influence the decision to
perform the reference standard?
o Were the methods for performing the test described in sufficient detail
to permit replication?
·
Does the evidence show the test
can accurately distinguish between those who do and don‟t have the disorder?
Are the likelihood ratios for the test results presented or data necessary for
their calculation provided?
· Can I apply this test to a specific patient?
o Will the reproducibility of the test and its interpretation be
available, affordable, accurate and precise in my setting? Is interpretation of
the test tested on people with my skill level?
o Can I generate a sensible estimate of the patient‟s pre-test
probability?
o Are the results applicable to my patient? (e.g. do they have the same
disease severity)
o Will the results change my management?
o Will the patients be better off as a result of the test? An accurate
test is very valuable if the target disorder is dangerous if undiagnosed, has
acceptable risks and effective treatment exists
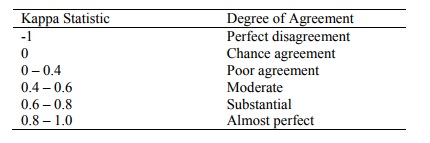
·
A measure of agreement after
chance is removed from consideration
·
= Actual agreement beyond chance
/ potential agreement beyond chance:
·
E.g.. If observed agreement = 78%
of cases, and agreement on the basis of chance is 51%, then Kappa = (78 –
51)/(100 – 51) = 0.55
·
Hard to compare between studies –
a different case-mix would yield a different k
·
A weighted k can be used to
measure agreement in ordinal data
·
For larger samples (> 100)
sampling distribution is normal, so it is possible to calculate a standard
error, confidence intervals and P values
·
Other non-parametric tests (e.g.
chi-squared, correlation coefficient) are measures of association not agreement
Related Topics