Chapter: XML and Web Services : Essentials of XML : The X-Files: XPath, XPointer, and XLink
XPointer: Points, Ranges, Notation
XPointer
The XML Pointer Language
(XPointer), currently in the candidate recommendation stage of the W3C approval
process, builds on the XPath specification. An XPointer uses loca-tion steps
the same as XPath but with two major differences: Because an XPointer describes
a location within an external document, an XPointer can target a point within
that XML document or a range within the target XML document. You can find the
complete specification at http://www.w3.org/TR/xptr.
Because XPointer builds on
the XPath specification, the location steps within an XPointer are comprised of
the same elements that make up XPath location steps. The axes for XPointer are
the same as the axes for XPath, as indicated in Table 5.2.
The node tests for an
XPointer are, for the most part, the same as for an XPath node test. However,
in addition to the node tests already listed for XPath expressions, XPointer
provides two more important node tests:
point()
range()
These two additional node
tests correspond to the new functionality added by XPointer. For this new
functionality to work correctly, the XPointer specification added the concept
of a location within an XML document. Within XPointer, a location can be an
XPath node, a point, or a range. A point can represent the location immediately
before or after a specified character or the location just before or just after
a specified node. A range con-sists of a start point and an endpoint and
contains all XML information between those two points. In fact, the XPointer
specification extends the node types to include points and ranges.
XPointer expressions also
allow predicates to be specified as part of a location step in much the same
fashion XPath expressions allow for them. As with XPath expressions, XPointer
expressions have specific functions to deal with each specific predicate type.
However, the XPointer specification also adds an additional function named unique(). This new function indicates
whether an XPointer expression selects a single location rather than multiple
locations or no locations at all.
For an XPath expression, the
result from a location step is known as a node
set; for an XPointer expression, the result is known as a location set. To reduce the confusion,
the XPointer specification uses a different term for the results of an
expression:
Because an XPointer expression can yield a
result consisting of points or ranges, the idea of the node set had to be extended to include these types. Therefore, to
prevent confusion, the results of an XPointer expression are referred to location sets. Four of the functions
that return location sets, id(), root(), here(), and origin(), have the differ-ences noted in Table 5.9.
TABLE 5.9 Some
XPointer Functions That Return Location Sets

Function : Description
id()
Selects all nodes with the specified ID
root()
Selects the root element as the only location in a location set
here()
Selects the current element location in a location set
origin()
Selects the current element location for a node using an out-of-line link
The id() function works exactly the
same as the id() function for an XPath expression. The root() function works just like the
/ character—it indicates the
root element of an XML document.
The next two functions, here() and origin(), are interesting functions
in their own right. The here() function, as indicated, refers to the current element. Because an
XPointer expression can be located in a text node or in an attribute value,
this function could be used to refer to the current element rather than simply
the current node. The origin() function works much the same as the here() function, except that it refers to the originating element. The
key idea here is that the originating element does not need to be located
within the same document as the resulting location set.
Not every target for an
XPointer must be a node. Targeting nodes works great when you’re designing or
utilizing an application that handles XML documents as node trees, such as the
XML DOM, but it doesn’t lend itself well to other application types. What
happens when the user desires a location at a particular point or a range
within an XML document that may cover various nodes and child nodes? This is
where much of the power behind XPointers surfaces.
Points
Many times a link from one
XML document into another must locate a specific point within the target
document. XPointer points solve this problem for XML developers by allowing a
context node to be specified and an index position indicating how far from the
context node the desired point is. However, how do you know whether you’re
referring to the number of characters from the context node to locate the point
or the number of nodes from the context node? In truth, it all depends on which
XPointer point type you decide to use. Two different types of points can be
represented using XPointer points:
Node points
Character points
Node points are location points in an XML
document that are nodes that contain child nodes. For these node points, the
index position indicates after which child node to navi-gate to. If 0 is
specified for the index, the point is considered to be immediately before any
child nodes. A node point could be considered to be the gap between the child nodes
of a container node.
When the origin node is a text node, the index
position indicates the number of charac-ters. These location points are
referred to as character points.
Because you are indicat-ing the number of characters from the origin, the index
specified must be an integer greater than or equal to 0 and less than or equal
to the total length of the text within the text node. By specifying 0 for the
index position in a character point, the point is consid-ered to be immediately
before the first character in the text string. For a character point, the
point, conceptually, represents the space between the characters of a text
string.
Now that you have a better
understanding of the different types of points supported within the XPointer
Language, how do you indicate that you want a point within an XPointer
expression? By using a point identifier called start-point().
To understand better how
XPointer points work, we will use the sample XML document shown in Listing 5.3.
This is a simple XML document containing a list of names and addresses.
LISTING 5.3 Sample3.xml Contains
a Small List of Names and Addresses
<People>
<Person>
<Name>Dillon Larsen</Name>
<Address>
<Street>123 Jones
Rd.</Street> <City>Houston</City>
<State>TX</State> <Zip>77380</Zip>
</Address>
</Person>
<Person>
<Name>Madi
Larsen</Name> <Address>
<Street>456 Hickory
Ln.</Street> <City>Houston</City>
<State>TX</State> <Zip>77069</Zip>
</Address>
</Person>
<Person>
<Name>John
Doe</Name> <Address>
<Street>214 Papes
Way</Street> <City>Houston</City>
<State>TX</State> <Zip>77301</Zip>
</Address>
</Person>
<Person>
<Name>John
Smith</Name> <Address>
<Street>522 Springwood
Dr.</Street> <City>Houston</City>
<State>TX</State>
<Zip>77069</Zip>
</Address>
</Person>
<Person>
<Name>Jane
Smith</Name> <Address>
<Street>522 Springwood
Dr.</Street> <City>Houston</City>
<State>TX</State>
<Zip>77069</Zip>
</Address>
</Person>
LISTING 5.3 continued
<Person>
<Name>Mark
Boudreaux</Name> <Address>
<Street>623 Fell
St.</Street> <City>Houston</City>
<State>TX</State> <Zip>77380</Zip>
</Address>
</Person>
</People>
Using the sample XML document
in Listing 5.3, you can more clearly understand the ideas behind XPointer
points and how they work, as shown in Table 5.10.
TABLE 5.10 Examples
of XPointer Points and the Resulting Locations

From the examples in Table
5.10, you can see how the types of points behave and their resulting locations.
The XPointer Language specification does not
distinguish between the endpoint of one node and the start point of another.
The conceptual space between each node represents one point so that as one node
ends, another begins, but both share the same conceptual point.
Ranges
An XPointer range defines just that—a range consisting
of a start point and an endpoint. A range will contain the XML between the
start point and endpoint but does not neces-sarily have to consist of neat
subtrees of an XML document. A range can extend over multiple branches of an
XML document. The only criterion is that the start point and endpoint must be
valid.
Within the XPointer Language,
a range can be specified by using the keyword to within the XPointer expression in conjunction
with the start-point() and end-point() func-tions. For instance, the following expression specifies a
range beginning at the first char-acter in the <Name> element for Dillon Larsen and ending after the
ninth character in the <Name> element for Dillon Larsen:
/People/Person[1]/Name/text()start-point()[position()=0] to
➥
/People/Person[1]/Name/text()start-point()[position()=9]
In this example, two node
points are used as the starting and ending points for the range. The result is
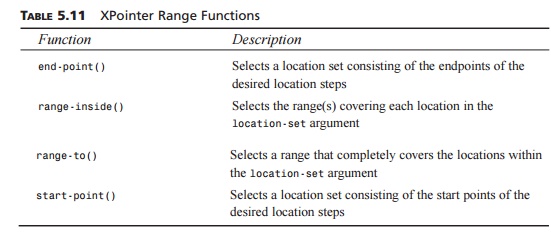
the string Dillon La. Table 5.11 lists the various range functions available.
TABLE 5.11 XPointer
Range Functions
The XML Pointer Language also
has the ability to perform basic string matching by using a function named string-range(). This function returns a
location set with one range for every nonoverlapping match to the search string
by performing a case-sensitive search. The general syntax for string-range() is as follows:
string-range(location-set, string,
[index, [length]])
The location-set argument for the string-range() function is any XPointer
expres-sion that would create a location set as its result—for instance, /, /People/Person, /People/Person[1], and so on. The string argument contains the string
searched for. It does not matter, when you’re using the string-range() function, where this string
occurs; only that is does occur. By specifying the index and length arguments, you can indicate
the range you wish returned. For instance, to return the letters Ma from the Madi Larsen <Name> element, you could pass an index value of 1 and a length value of 2.
Abbreviating
XPointer Notation
When you’re creating XPointer
expressions, generally elements will be referenced by ID or by location. For
just this reason, the XML Pointer Language added a few abbreviated forms of
reference. In addition to all the standard XPath abbreviations, XPointer goes
one step beyond that: XPointer allows you to remove the [ and ] characters from the index
position. Therefore, the expression
/People/Person[1]/Name[1]
becomes this:
1/1/1
Overall, it’s a much shorter
expression. However, speaking from experience, this does not tend to lend
itself well to actual implementation. The reasoning behind this goes back to
what XML was designed for in the first place: to give meaning and structure to
data. By specifying the XPointer expression as 1/1/1, we lose all documentation regarding what it
is we’re looking for—we have to know, off the tops of our heads, that we’re
going to be selecting the first <Name> element of the first <Person> element of the
<People> element.
Although it’s perfectly
acceptable to use the new abbreviated notation, consider this pos-sible
scenario: Your company asks you to link two documents together using XLinks and
XPointers. Two years later, you no longer work at that company and the company
did not have the foresight to document any of your work. The individual who
inherits your work must now perform some research on her own to figure out what
exactly you were select-ing using your abbreviated syntax. However, if you had
used the abbreviated XPath ver-sion, it makes that individual’s job a little
easier—she knows, by virtue of the XPath expression itself, that the first <Name> element of the first <Person> element beneath the <People> element should be selected.
Related Topics