Chapter: XML and Web Services : Essentials of XML : The X-Files: XPath, XPointer, and XLink
XPath: Operators, Special Characters and Syntax
XPath
The XML Path Language (XPath)
is a standard for creating expressions that can be used to find specific pieces
of information within an XML document. XPath expressions are used by both XSLT
(for which XPath provides the core functionality) and XPointer to locate a set
of nodes. To understand how XPath works, it helps to imagine an XML doc-ument
as a tree of nodes consisting of both elements and attributes. An XPath
expression can then be considered a sort of roadmap that indicates the branches
of the tree to follow and what limbs hold the information desired. The complete
documentation for the XPath recommendation can be found at http://www.w3c.org/TR/xpath.
XPath expressions have the
ability to locate nodes based on the nodes’ type, name, or value or by the
relationship of the nodes to other nodes within the XML document. In addition
to being able to find nodes based on these criteria, an XPath expression can
also return any of the following:
A node set
A Boolean value
A string value
A numeric value
XML documents are, in
essence, a hierarchical tree of nodes. Curiously, there is a simi-larity
between URLs and XPath expressions. Why? Quite simply, URLs represent a
navi-gation path of a hierarchical file system, and XPath expressions represent
a navigation path for a hierarchical tree of nodes.
Operators
and Special Characters
XPath expressions are composed
using a set of operators and special characters, each with its own meaning.
Table 5.1 lists the various operators and special characters used within the
XML Path Language.
TABLE 5.1 Operators
and Special Characters for the XML Path Language


Table 5.1 only provides a
list of operators and special characters that can be used within an XPath
expression. However, the table does not indicate what the order of precedence
is. The priority for evaluating XPath expressions is as follows:
Grouping
Filters
Path operations
XPath Syntax
The XML Path Language
provides a declarative notation, termed a pattern,
used to select the desired set of nodes from XML documents. Each pattern
describes a set of matching nodes to select from a hierarchical XML document.
Each pattern describes a “navigation” path to the desired set of nodes similar
to the Uniform Resource Identifier (URI) syntax. However, instead of navigating
a file system, the XML Path Language navigates a hierarchical tree of nodes within
an XML document.
Each “query” of an XML
document occurs from a particular starting node that defines the context for
the query. The context for the query has a very large impact on the results.
For instance, the pattern that locates a node from the root of an XML document
will most likely be a very different pattern when looking for the same node
from some-where else in the hierarchy.
As mentioned earlier in this
chapter, one possible result from performing an XPath query is a node set, or a
collection of nodes matching a specified search criteria. To receive these
results, a “location path” is needed to locate the result nodes. These location
paths select the resulting node set relative to the current context. A location
path is, itself, made up of one or more location steps. Each step is further
comprised of three pieces:
An axis
A node test
A predicate
Therefore, the basic syntax
for an XPath expression would be something like this:
axis::node test[predicate]
Using this basic syntax and
the XML document in Listing 5.1, we could locate all the <c> nodes by using the following
XPath expression:
/a/b/child::*
Alternatively, we could issue
the following abbreviated version of the preceding expression:
/a/b/c
All XPath expressions are
dependant on the current context. The context is the current location within
the tree of nodes. Therefore, if we’re currently on the second <b> element within the XML
document in Listing 5.1, we can select all the <c> elements contained within that <b> element by using the
following XPath expression:
./c
This is what’s known as a “relative” XPath
expression.
Axes
The axis portion of the
location step identifies the hierarchical relationship for the desired nodes
from the current context. An axis for a location step could be any of the items
listed within Table 5.2.
TABLE 5.2 XPath
Axes for a Location Step


All the axes in Table 5.2 depend on the context
of the current node. This raises the ques-tion, How do you know what the
current context node is? The easiest way to explain this is through example, so
let’s use the XML document shown in Listing 5.1 as the basis for the
explanation of how the current context node is defined.
LISTING 5.1 Sample1.xml Contains
a Simple XML Document
<a>
<b>
<c d=”Attrib 1”>Text
1</c> <c d=”Attrib 2”>Text 2</c> <c d=”Attrib 3”>Text
3</c>
</b>
<b>
<c d=”Attrib 4”>Text
4</c> <c d=”Attrib 5”>Text 5</c>
</b>
<b>
<c d=”Attrib 6”>Text
6</c> <c d=”Attrib 7”>Text 7</c> <c d=”Attrib 8”>Text
8</c> <c d=”Attrib 9”>Text 9</c>
</b>
<b>
<c d=”Attrib 10”>Text
10</c> <c d=”Attrib 11”>Text 11</c> <c d=”Attrib
12”>Text 12</c>
</b>
</a>
Using this sample XML
document as a reference, and the following XPath query, we can examine how the
current context node is determined:
/a/b[1]/child::*]
The preceding XPath query consists of three
location steps, the first of which is a. The second location step in the XPath query
is b[1], which selects the first <b> element within the <a> element. The final location
step is child::*, which selects all (signified by *) child elements of the first <b> element contained within the
<a> element. It is important to
understand that each location step has a different context node. For the first
location step, the current context node is the root of the XML document. It
should be noted that the node <a> is not the root of the XML document; it’s the first element within
the hierarchy, but the root of an XML document is denoted by “/” as the first character
within an XPath query. The context for the second location step is the node <a>. The third location step has
the first <b> node as its context.
Now that you have a better
understanding of how the context for an XPath query axis is defined, we can
look at the resulting node sets for the axes described in Table 5.2. Using the
XML document in Listing 5.1, Table 5.3 lists some XPath queries with the
various axes and the resulting node sets.
TABLE 5.3 XPath
Queries and the Resulting Node Sets


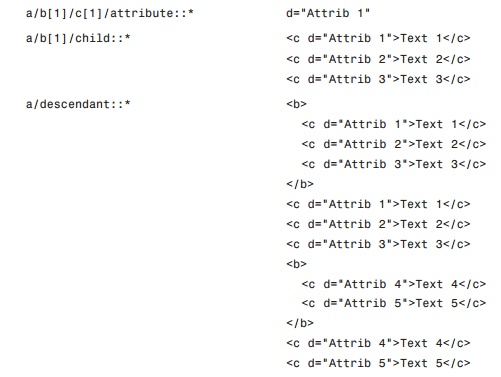



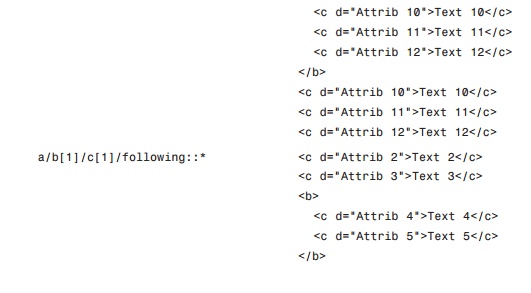

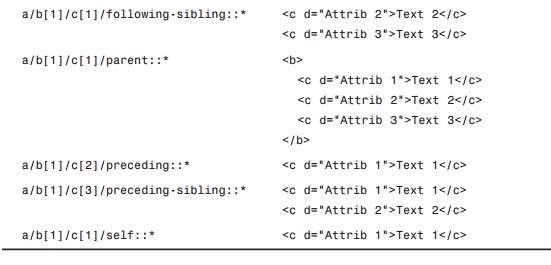
From the contents of Table
5.3, you can see what may be some strange results. However, it’s important to
remember that a resulting node set contains the entire hierarchy for the nodes
contained within the set. Keeping that in mind, the results for the XPath
queries in Table 5.3 begin to make more sense.
Node
Tests
The node test portion of a
location step indicates the type of node desired for the results. Every axis
has a principal node type: If an axis is an element, the principal node type is
element; otherwise, it is the type
of node the axis can contain. For instance, if the axis is attribute, the principal node type is attribute.
A node test may also contain
a node name, or QName. In this case, a node with the speci-fied name is sought, and if
found, it’s returned in the node set. However, the nodes selected in this
manner must be the principal node type sought and have an expanded name equal
to the QName specified. This means that if the node belongs to a namespace, the
namespace must also be included in the node test for the node to be selected.
For instance, ancestor::div and ancestor::test:div will produce two entirely different node sets. In this first case,
only nodes that have no namespace specified and have a name of div will be selected. In the
second case, only those div nodes belonging to the test namespace will be selected.
In addition to specifying an
actual node name, other node tests are available to select the desired nodes.
Here’s a list of these node tests:
comment()
node()
processing-instruction()
text()
As you can see, a small number of node tests
are available for use within a location step. The comment() node test selects comment
nodes from an XML document. The node() node test selects a node of any type, whereas
the text() node test selects those
nodes that are text nodes. Special consideration should be given to the processing-instruc-tion() node test, because this node
test will accept a literal string parameter to specify the name of a desired
processing instruction.
Predicates
The predicate portion of a location
step filters a node set on the specified axis to create a new node set. Each
node in the preliminary node set is evaluated against the predicate to see
whether it matches the filter criteria. If it does, the node ends up in the
filtered node set. Otherwise, it doesn’t.
A predicate may consist of a
filter condition that is applied to an axis that either directs the condition
in a forward or reverse direction. A forward axis predicate contains the
cur-rent context node and nodes that follow the context node. A reverse axis
predicate con-tains the current context node and nodes that precede the context
node.
A predicate within a location
step may contain an expression that, when evaluated, results in a Boolean (or logical) value that can be either True
or False. For instance, if the result of the expression is a number, such as in
the expression /a/b[position()=2], then the predicate [position()=2] is evaluated for each node in the axis to see
whether it is the second node, and if so, it returns True for the predicate. In fact,
the expressions for a predicate can get rather complex because you are not
limited to one test condition within a predicate—you may use the Boolean
operators and and or. Using these two operators, you can create very powerful filter
conditions to find the desired node set. Predicates may also consist of a
variety of functions.
XPath predicates may, and most probably will,
contain a Boolean comparison, as listed in Table 5.4.
TABLE 5.4 Boolean
Operators and Their Respective Descriptions
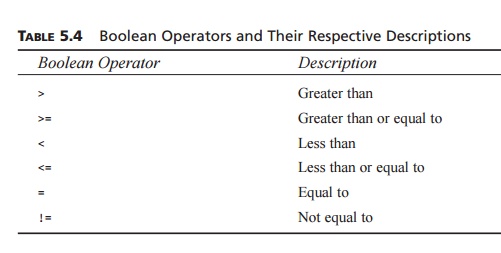
XPath
Functions
XPath functions are used to
evaluate XPath expressions and can be divided into one of four main groups:
Boolean
Node set
Number
String
Each of these main groups contains a set of
functions that deal with specific operations needed with respect to the items
covered. Table 5.5 lists each XPath function available as well as the arguments
accepted, the return type, and a brief description.
TABLE 5.5 XPath
Functions as Recommended by the W3C
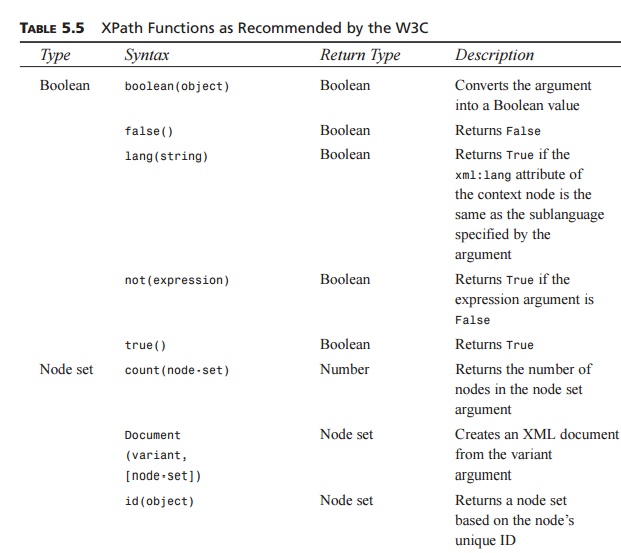




As you can see in Table 5.5,
a large number of functions are available that perform a myriad of operations.
These functions can be used within a location-step predicate to help filter out
undesired nodes. They also help in providing functionality that without which
would make the XPath language quite limiting.
XPath Examples
You have seen the basic construction of each
piece of an XPath query, but in truth, it helps to see the XPath expressions
and the results for them. Therefore, to help with this and to provide as many
examples as possible, we will use the code in Listing 5.2, which provides a
good baseline sample XML document we can use for the XPath examples
LISTING 5.2 Sample2.xml Provides
the XML Document Against Which the Sample
XPath Expressions Will Be Evaluated
<PurchaseOrder Tax=”5.76”
Total=”75.77”>
<ShippingInformation>
<Method>USPS</Method>
<DeliveryDate>08/12/2001</DeliveryDate>
<Name>Dillon Larsen</Name>
<Address>
<Street>123 Jones
Rd.</Street> <City>Houston</City> <State>TX</State>
<Zip>77381</Zip>
</Address>
</ShippingInformation>
<BillingInformation>
<PaymentMethod>Credit
Card</PaymentMethod> <BillingDate>08/09/2001</BillingDate>
<Name>Madi Larsen</Name>
<Address>
<Street>123 Jones
Rd.</Street> <City>Houston</City> <State>TX</State>
<Zip>77381</Zip>
</Address>
</BillingInformation>
<Order SubTotal=”70.01” ItemsSold=”17”>
<Product Name=”Baby
Swiss” Id=”702890” Price=”2.89”
➥ Quantity=”1”/>
<Product Name=”Hard
Salami” Id=”302340” Price=”2.34”
➥ Quantity=”1”/>
<Product Name=”Turkey”
Id=”905800” Price=”5.80”
➥ Quantity=”1”/>
<Product Name=”Caesar
Salad” Id=”991687” Price=”2.38”
➥ Quantity=”2”/>
<Product Name=”Chicken
Strips” Id=”133382” Price=”2.50”
➥ Quantity=”1”/>
<Product Name=”Bread”
Id=”298678” Price=”1.08”
➥ Quantity=”1”/>
<Product Name=”Rolls”
Id=”002399” Price=”2.24”
➥ Quantity=”1”/>
<Product Name=”Cereal”
Id=”066510” Price=”2.18”
➥ Quantity=”1”/>
<Product Name=”Jalapenos” Id=”101005”
Price=”1.97”
➥ Quantity=”1”/>
<Product Name=”Tuna”
Id=”000118” Price=”0.92”
➥ Quantity=”3”/>
<Product Name=”Mayonnaise” Id=”126860”
Price=”1.98”
➥ Quantity=”1”/>
<Product Name=”Top
Sirloin” Id=”290502” Price=”9.97”
➥ Quantity=”2”/>
<Product Name=”Soup”
Id=”001254” Price=”1.33”
➥ Quantity=”1”/>
<Product Name=”Granola
Bar” Id=”026460” Price=”2.14”
➥ Quantity=”2”/>
<Product Name=”Chocolate Milk”
Id=”024620” Price=”1.58”
➥ Quantity=”2”/>
<Product Name=”Spaghetti” Id=”000265”
Price=”1.98”
➥ Quantity=”1”/>
<Product Name=”Laundry
Detergent” Id=”148202” Price=”8.82”
➥ Quantity=”1”/> </Order>
</PurchaseOrder>
As you can see, Listing 5.2
looks very similar to Listing 4.1. This is basically the same sample XML
document we used in Chapter 4, “Creating XML Schemas,” but it has been slightly
modified to perform as a better example for XPath queries. Using this sample
XML document, Table 5.6 contains sample XPath expressions and their respective
results.
TABLE 5.6 Sample
XPath Queries and Their Results




As you can see from the examples in Table 5.6,
XPath expressions can get rather long and complex. For this reason, an
abbreviated syntax has also been introduced. Table 5.7 lists the XPath
expressions and their respective abbreviations.
TABLE 5.7 XPath
Expressions and Their Abbreviations
Expression Abbreviation
self::node() .
parent::node() ..
child::nodename nodename
attribute::nodename @nodename
descendant-or-self::node() //
Using the abbreviations in
Table 5.7, the XPath expressions in Table 5.6 can be rewritten as shown in
Table 5.8.
TABLE 5.8 Abbreviated
XPath Expressions from Table 5.6
Full Expression Abbreviated Expression
/PurchaseOrder/child::Order /PurchaseOrder/Order
/PurchaseOrder/child::* /PurchaseOrder/*
/PurchaseOrder/descendant::text() /PurchaseOrder//text()
/PurchaseOrder/Order/child::node() /PurchaseOrder/Order/node()
/PurchaseOrder/Order/Product/ /PurchaseOrder/Order/Product/@Name
➥ attribute::Name
/PurchaseOrder/Order/Product/ /PurchaseOrder/Order/Product/@*
➥ attribute::*
/PurchaseOrder/descendant::Name /PurchaseOrder//Name
//Product/ancestor::* //*[.//Product]
//Name/ancestor::BillingInformation //BillingInformation[.//Name]
//*/ancestor-or-self::Order N/A
//*/descendant-or-self::Name //Name
//*/self::Product //Product
/PurchaseOrder/child:: /PurchaseOrder/ShippingInformation//Zip
➥ ShippingInformation/
➥ descendant::Zip
/PurchaseOrder/*/child::Name PurchaseOrder/*/Name
/ /
/descendant::Product //Product
/descendant::Address/child::Zip //Address/Zi
TABLE 5.8
continued
Full Expression Abbreviated
Expression
/PurchaseOrder/Order/child:: PurchaseOrder/Order/Product[3]
➥ Product[position()=3]
/PurchaseOrder/Order/child:: PurchaseOrder/Order/Product[last()]
➥ Product[last()]
/PurchaseOrder/Order/child:: PurchaseOrder/Order/Product[last()-1]
➥ Product[last()-1]
/PurchaseOrder/Order/child:: PurchaseOrder/Order/Product[position()>3]
➥ Product[position()>3]
/PurchaseOrder/Order/Product/ N/A
➥ following-sibling::
➥ Product[position()>3]
/PurchaseOrder/Order/Product N/A
➥ [position()=4]/
➥ preceding-sibling::
➥ Product
/descendant::Product[position()=3] //Product[3]
/descendant::Product //Product[@Name=”Turkey”]
➥ [attribute::Name=”Turkey”]
/descendant::Product //Product[@Price>”2.00”][7]
➥ [attribute::Price>”2.00”]
➥ [position()=7]
/PurchaseOrder/child::* /PurchaseOrder/ShippingInformation|
➥ [self::ShippingInformation ➥ BillingInformation
➥ or
self::BillingInformation]
You can see from the examples in Table 5.8 that
not every expression has an abbreviated equivalent. For instance, the XPath
expression /PurchaseOrder/Order/Product/fol-lowing-sibling::Product[position()>3]
has no
abbreviated equivalent.
Related Topics