Chapter: Embedded Systems Design : Buffering and other data structures
What is a buffer?
What is a buffer?
A buffer is as its name suggests an area of memory that is used to store data, usually on a temporary basis prior to processing it. It is used to compensate for timing problems between software modules or subsystems that cannot always guarantee to process every piece of data as it becomes available. It is also used as a collection point for data so that all the relevant information can be collected and organised before processing.
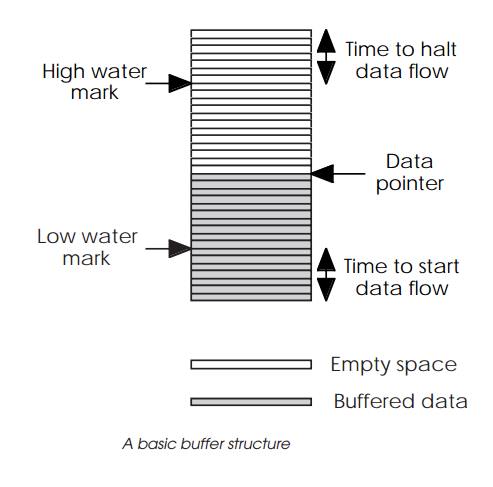
The diagram shows the basic construction of a buffer. It consists of a
block of memory and a pointer that is used to locate the next piece of data to
be accessed or removed from the buffer. There are additional pointers which are
used to control the buffer and prevent data overrun and underrun. An overrun
occurs when the buffer cannot accept any more data. An underrun is caused when
it is asked for data and cannot provide it.
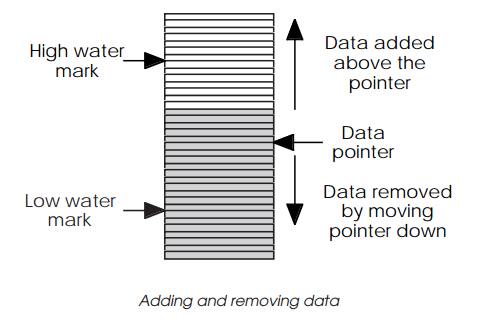
Data is removed by using the pointer to locate the next value and moving
the data from the buffer. The pointer is then moved to the next location by
incrementing its value by the number of bytes or words that have been taken.
One common programming mis-take is to confuse words and bytes. A 32 bit
processor may access a 32 bit word and therefore it would be logical to think
that the pointer is incremented by one. The addressing scheme may use bytes and
therefore the correct increment is four. Adding data is the opposite procedure.
The details on exactly how these proce-dures work determine the buffer type and
its characteristics and are explained later in this chapter.
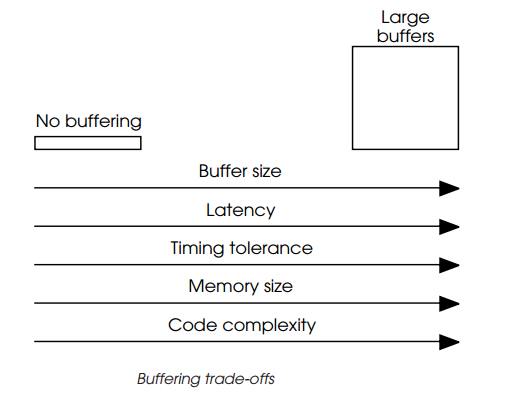
However, while buffering does undoubtedly offer benefits, they are not
all for free and their use can cause problems. The diagram shows the common
trade-offs that are normally encoun-tered with buffering.
Latency
If data is stored in a buffer, then there is normally a delay before the
first and subsequent data is received from the buffer. This delay is known as
the buffer latency and in some systems, it can be a big advantage. In others,
however, its effect is the opposite.
For a real-time system, the buffer latency defines the earliest that
information can be processed and therefore any response to that information
will be delayed by the latency irrespective of how fast or efficient the
processing software and hardware is. If data is buffered so that eight samples
must be received before the first is processed, the real-time response is now
eight times the data rate for a single sample plus the processing time. If the
first sample was a request to stop a machine or ignore the next set of data,
the processing that determines its meaning would occur after the event it was
associated with. In this case, the data that should have been ignored is now in
the buffer and has to be removed.
Latency can also be a big problem for data streams that rely on
real-time to retain their characteristics. For example, digital audio requires
a consistent and regular stream of data to ensure accurate reproduction.
Without this, the audio is distorted and can become unintelligible in the case
of speech. Buffering can help by effectively having some samples in reserve so
that the audio data is always there for decoding or processing. This is fine
except that there is now an initial delay while the buffer fills up. This delay
means an interaction with the stream is difficult as anyone who has had an
international call over a satellite link with the large amount of delay can
vouch for. In addition some systems cannot tolerate delay. Digital telephone
handsets have to demonstrate a very small delay in the audio processing path
which limits the size of any buffering for the digital audio data to less than
four samples. Any higher and the delay caused by buffer latency means that the
phone will fail its type approval.
Timing tolerance
Latency is not all bad, however, and used in the right amounts can
provide a system that is more tolerant and resilient than one that is not. The
issue is based around how time critical the system is and perhaps more
importantly how deterministic is it.
Consider a system where audio is digitally sampled, fil-tered and
stored. The sampling is performed on a regular basis and the filtering takes
less time than the interval between samples. In this case, it is possible to
build a system that does not need buffering and will have a very low latency.
As each sample is received, it is processed and stored. The latency is the time
to take a single sample.
If the system has other activities and especially if those involve
asynchronous events such as the user pressing a button on the panel, then the
guarantee that all the processing can be completed between samples may no
longer be true. If this dead-line is not made, then a sample may be lost. One
solution to this — there are others such as using a priority system as supplied
by a real-time operating system — is to use a small buffer to temporar-ily
store the data so that it is not lost. By doing this the time constraints on
the processing software are reduced and are more tolerant of other events. This
is, however, at the expense of a slightly increased latency.
Memory size
One of the concerns with buffers is the memory space that they can take.
With a large system this is not necessarily a problem but with a
microcontroller or a DSP with on-chip memory, this can be an issue when only
small amounts of RAM are available.
Code complexity
There is one other issue concerned with buffers and buffer-ing technique
and that is the complexity of the control structures needed to manage them.
There is a definite trade-off between the control structure and the efficiency
that the buffer can offer in terms of memory utilisation. This is potentially
more important in the region of control and interfacing with interrupts and
other real-time events. For example, a buffer can be created with a simple area
of memory and a single pointer. This is how the frequently used stack is
created. The control associated with the memory — or buffer which is what the
memory really represents
— is a simple register acting as an address pointer. The additional
control that is needed to remember the stacking order and the frame size and
organisation is built into the frame itself and is controlled by the
microprocessor hardware. This additional level of control must be replicated
either in the buffer control software or by the tasks that use the buffer. If a
single task is associated with a buffer, it is straightforward to allow the
task to implement the control. If several tasks use the same buffer, then the
control has to cope with multiple and, possibly, conflicting accesses and while
this can be done by the tasks, it is better to nominate a single entity to
control the buffer. However, the code complexity associated with the buffer has
now increased.
The code complexity is also dependent on how the buffer is organised. It
is common for multiple pointers to be used along with other data such as the
number of bytes stored and so on. The next section in this chapter will explain
the commonly used buffer structures.
Related Topics