Chapter: Fundamentals of Database Systems : Additional Database Topics: Security and Distribution : Distributed Databases
Types of Distributed Database Systems
Types
of Distributed Database Systems
The term distributed
database management system can describe various systems that differ from
one another in many respects. The main thing that all such systems have in
common is the fact that data and software are distributed over multiple sites
con-nected by some form of communication network. In this section we discuss a
number of types of DDBMSs and the criteria and factors that make some of these
systems different.
The first factor we consider is the degree of homogeneity of the DDBMS
software. If all servers (or individual local DBMSs) use identical software and
all users (clients) use identical software, the DDBMS is called homogeneous; otherwise, it is called heterogeneous. Another factor related
to the degree of homogeneity is the degree
of local autonomy. If there is no provision for the local site to function
as a standalone DBMS, then the
system has no local autonomy. On the
other hand, if direct access by local
transactions to a server is permitted, the system has some degree of local autonomy.
Figure 25.2 shows classification of DDBMS
alternatives along orthogonal axes of distribution, autonomy, and
heterogeneity. For a centralized database, there is complete autonomy, but a
total lack of distribution and heterogeneity (Point A in the figure). We see
that the degree of local autonomy provides further ground for classification
into federated and multidatabase systems. At one extreme of the autonomy
spectrum, we have a DDBMS that looks like
a centralized DBMS to the user, with zero autonomy (Point B). A single
conceptual schema exists, and all access to the system is obtained through a
site that is part of the DDBMS—which means that no local autonomy exists. Along
the autonomy axis we encounter two types of DDBMSs called federated database system (Point C) and multidatabase system
(Point D).
In such systems, each server is an independent and autonomous centralized DBMS
that has its own local users, local transactions, and DBA, and hence has
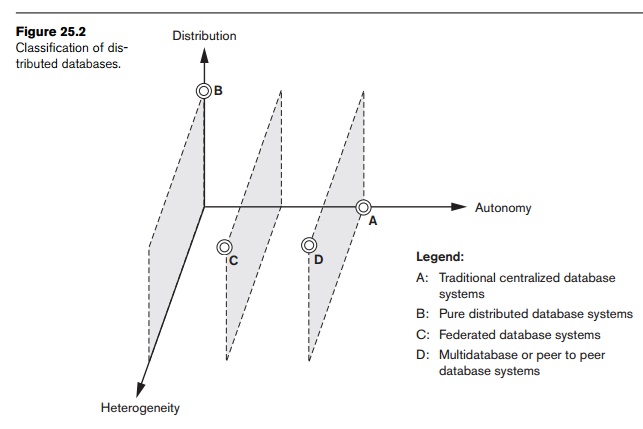
a very high degree of local autonomy. The term federated
database system (FDBS) is used when there is some global view or schema of
the federation of databases that is shared by the applications (Point C). On
the other hand, a multidatabase system
has full local autonomy in that it does not have a global schema but
interactively constructs one as needed by the application (Point D).3
Both systems are hybrids between distributed and centralized systems, and the
distinction we made between them is not strictly followed. We will refer to
them as FDBSs in a generic sense. Point D in the diagram may also stand for a
system with full local autonomy and full heterogeneity—this could be a
peer-to-peer database system (see Section 25.9.2). In a heterogeneous FDBS, one
server may be a relational DBMS, another a network DBMS (such as Computer
Associates’ IDMS or HP’S IMAGE/3000), and a third an object DBMS (such as
Object Design’s ObjectStore) or hierarchical DBMS (such as IBM’s IMS); in such
a case, it is necessary to have a canonical system language and to include
language translators to translate subqueries from the canonical language to the
language of each server.
We briefly discuss the issues affecting the
design of FDBSs next.
Federated Database Management Systems
Issues
The type of heterogeneity present in FDBSs may
arise from several sources. We dis-cuss these sources first and then point out
how the different types of autonomies contribute to a semantic heterogeneity
that must be resolved in a heterogeneous FDBS.
Differences in data models. Databases in an organization come from a
vari-ety of data models, including the so-called legacy models (hierarchical
and network, see Web Appendixes D and E), the relational data model, the object
data model, and even files. The modeling capabilities of the models vary.
Hence, to deal with them uniformly via a single global schema or to process
them in a single language is challenging. Even if two databases are both from
the RDBMS environment, the same information may be represented as an attribute
name, as a relation name, or as a value in different databases. This calls for
an intelligent query-processing mechanism that can relate informa-tion based on
metadata.
Differences in constraints. Constraint facilities for specification and
implementation vary from system to system. There are comparable features that
must be reconciled in the construction of a global schema. For example, the
relationships from ER models are represented as referential integrity
constraints in the relational model. Triggers may have to be used to implement
certain constraints in the relational model. The global schema must also deal
with potential conflicts among constraints.
Differences in query languages. Even with the same data model, the languages
and their versions vary. For example, SQL has multiple versions like SQL-89,
SQL-92, SQL-99, and SQL:2008, and each system has its own set of data types,
comparison operators, string manipulation features, and so on.
Semantic Heterogeneity. Semantic heterogeneity occurs when there are
differences in the meaning, interpretation, and intended use of the same or
related data. Semantic heterogeneity among component database systems (DBSs)
creates the biggest hurdle in designing global schemas of heterogeneous
databases. The design autonomy of component DBSs refers to
their freedom of choosing the following design
parameters, which in turn affect the eventual complexity of the FDBS:
The universe of discourse from which the data
is drawn. For example, for two customer accounts, databases in
the federation may be from the United States and Japan and have entirely
different sets of attributes about customer accounts required by the accounting
practices. Currency rate fluctuations would also present a problem. Hence,
relations in these two databases that have identical names—CUSTOMER or ACCOUNT—may have some common and some entirely
distinct information.
Representation and naming. The representation and naming of data elements
and the structure of the data model may be prespecified for each local
database.
The understanding, meaning, and subjective
interpretation of data. This is a chief contributor to semantic
heterogeneity.
Transaction and policy constraints. These deal with serializability criteria, compensating transactions, and other
transaction policies.
Derivation of summaries. Aggregation, summarization, and other
data-processing features and operations supported by the system.
The above problems related to semantic
heterogeneity are being faced by all major multinational and governmental
organizations in all application areas. In today’s commercial environment, most
enterprises are resorting to heterogeneous FDBSs, having heavily invested in
the development of individual database systems using diverse data models on
different platforms over the last 20 to 30 years. Enterprises are using various
forms of software—typically called the middleware,
or Web-based packages called application
servers (for example, WebLogic or WebSphere) and even generic systems,
called Enterprise Resource Planning
(ERP) systems (for example, SAP, J. D. Edwards ERP)—to manage the transport
of queries and transactions from the global application to individual
databases (with possible additional processing for business rules) and the data
from the heterogeneous database servers to the global application. Detailed
discussion of these types of software systems is outside the scope of this
book.
Just as providing the ultimate transparency is
the goal of any distributed database architecture, local component databases
strive to preserve autonomy. Communication
autonomy of a component DBS refers to its ability to decide whether to communicate with another
component DBS. Execution autonomy refers
to the ability of a component DBS to execute local operations without
interference from external operations by other component DBSs and its ability
to decide the order in which to execute them. The association autonomy of a component DBS implies that it has the
ability to decide whether and how much to share its functionality (operations
it supports) and resources (data it manages) with other component DBSs. The
major challenge of designing FDBSs is to let component DBSs interoperate while
still providing the above types of autonomies to them.
Related Topics