Chapter: Fundamentals of Database Systems : Additional Database Topics: Security and Distribution : Distributed Databases
Distributed Database Concepts
Distributed
Database Concepts
We can define a distributed database (DDB) as a collection of multiple logically
interrelated databases distributed over a computer network, and a distributed data-base management system
(DDBMS) as a software system that manages a distributed database while
making the distribution transparent to the user.
Distributed databases are different from
Internet Web files. Web pages are basically a very large collection of files
stored on different nodes in a network—the Internet—with interrelationships
among the files represented via hyperlinks. The common functions of database
management, including uniform query processing and transaction processing, do not apply to this scenario yet. The
technology is, however, moving in a direction such that distributed World Wide
Web (WWW) databases will become a reality in the future. We have discussed some
of the issues of accessing databases on the Web in Chapters 12 and 14. The
proliferation of data at millions of Websites in various forms does not qualify as a DDB by the definition
given earlier.
1. Differences between DDB and
Multiprocessor Systems
We need to distinguish distributed databases
from multiprocessor systems that use shared storage (primary memory or disk).
For a database to be called distributed, the following minimum conditions
should be satisfied:
Connection of database nodes over a computer
network. There are multi-ple
computers, called sites or nodes. These sites must be connected by
an underlying communication network
to transmit data and commands among sites, as shown later in Figure 25.3(c).
Logical interrelation of the connected
databases. It is
essential that the information in
the databases be logically related.
Absence of homogeneity constraint among
connected nodes. It is
not nec-essary that all nodes be identical in terms of data, hardware, and
software.
The sites may all be located in physical
proximity—say, within the same building or a group of adjacent buildings—and
connected via a local area network,
or they may be geographically distributed over large distances and connected
via a long-haul or wide area network. Local area networks
typically use wireless hubs or cables, whereas
long-haul networks use telephone lines or satellites. It is also possible to
use a combination of networks.
Networks may have different topologies that define the direct
communication paths among sites. The type and topology of the network used may
have a significant impact on the performance and hence on the strategies for
distributed query processing and distributed database design. For high-level
architectural issues, how-ever, it does not matter what type of network is
used; what matters is that each site be able to communicate, directly or
indirectly, with every other site. For the remainder of this chapter, we
assume that some type of communication network exists among sites, regardless
of any particular topology. We will not address any network-specific issues,
although it is important to understand that for an efficient operation of a
distributed database system (DDBS), network design and performance issues are
critical and are an integral part of the overall solution. The details of the
under-lying communication network are invisible to the end user.
2. Transparency
The concept of transparency extends the general
idea of hiding implementation details from end users. A highly transparent
system offers a lot of flexibility to the end user/application developer since
it requires little or no awareness of underlying details on their part. In the
case of a traditional centralized database, transparency simply pertains to
logical and physical data independence for application developers. However, in
a DDB scenario, the data and software are distributed over multiple sites
connected by a computer network, so additional types of transparencies are
introduced.
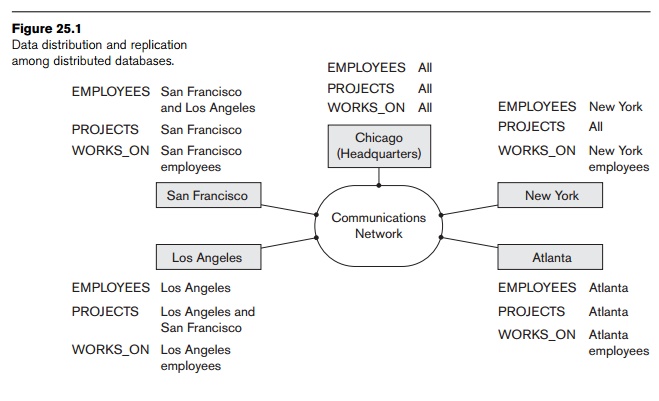
Consider the company database in Figure 3.5
that we have been discussing through-out the book. The EMPLOYEE, PROJECT, and WORKS_ON tables may be fragmented horizontally (that
is, into sets of rows, as we will discuss in Section 25.4) and stored with
possible replication as shown in Figure 25.1. The following types of
transparencies are possible:
Data organization transparency (also known as distribution or network transparency). This refers to freedom for the user from the operational details
of the network and the placement of the data in the distributed system. It may
be divided into location transparency and naming transparency. Location transparency refers to the
fact that the command used to perform a
task is independent of the location of the data and the location of the node
where the command was issued. Naming
transparency implies that once a name is associated with an object, the
named objects can be accessed unambiguously without additional specification
as to where the data is located.
Replication transparency. As we show in Figure 25.1, copies of the same data objects may be stored at multiple
sites for better availability, performance, and reliability. Replication
transparency makes the user unaware of the existence of these copies.
Fragmentation
transparency. Two
types of fragmentation are possible.
Horizontal fragmentation distributes a relation (table) into subrelations
that are subsets of the tuples (rows) in the
original relation. Vertical
fragmentation distributes a relation into subrelations where each
subrelation is defined by a subset
of the columns of the original relation. A global query by the user must be
transformed into several fragment queries. Fragmentation transparency makes the
user unaware of the existence of fragments.
Other
transparencies include design
transparency and execution
transparency—referring to freedom from knowing how the distributed
database is designed and where a
transaction executes.
3. Autonomy
Autonomy
determines the extent to which individual nodes
or DBs in a connected DDB can
operate independently. A high degree of autonomy is desirable for increased
flexibility and customized maintenance of an individual node. Autonomy can be
applied to design, communication, and execution. Design autonomy refers to independence of data model usage and
transaction management techniques among nodes. Communication autonomy determines the extent to which each node can
decide on sharing of information with other nodes. Execution autonomy refers to independence of users to act as they
please.
4. Reliability and Availability
Reliability and availability are two of the
most common potential advantages cited for distributed databases. Reliability is broadly defined as the
probability that a system is running (not down) at a certain time point,
whereas availability is the
prob-ability that the system is continuously available during a time interval.
We can directly relate reliability and availability of the database to the
faults, errors, and failures associated with it. A failure can be described as
a deviation of a system’s behavior from that which is specified in order to
ensure correct execution of operations. Errors
constitute that subset of system states that causes the failure. Fault is the cause of an error.
To construct a system that is reliable, we can
adopt several approaches. One common approach stresses fault tolerance; it recognizes that faults will occur, and designs
mechanisms that can detect and remove faults before they can result in a system
failure. Another more stringent approach attempts to ensure that the final
system does not contain any faults. This is done through an exhaustive design
process followed by extensive quality control and testing. A reliable DDBMS
tolerates failures of underlying components and processes user requests so
long as data-base consistency is not violated. A DDBMS recovery manager has to
deal with failures arising from transactions, hardware, and communication
networks. Hardware failures can either be those that result in loss of main
memory contents or loss of secondary storage contents. Communication failures
occur due to errors associated with messages and line failures. Message errors
can include their loss, corruption, or out-of-order arrival at destination.
5. Advantages of Distributed Databases
Organizations resort to distributed database
management for various reasons. Some important advantages are listed below.
Improved ease and flexibility of application
development.
Developing and maintaining
applications at geographically distributed sites of an organization is
facilitated owing to transparency of data distribution and control.
Increased reliability and availability. This is achieved by the isolation of faults to their site of origin without
affecting the other databases connected to the network. When the data and DDBMS
software are distributed over several sites, one site may fail while other
sites continue to operate. Only the data and software that exist at the failed
site cannot be accessed. This improves both reliability and availability.
Further improvement is achieved by judiciously replicating data and software at
more than one site. In a centralized system, failure at a single site makes
the whole system unavailable to all users. In a distributed database, some of
the data may be unreachable, but users may still be able to access other parts of
the database. If the data in the failed site had been replicated at another
site prior to the failure, then the user will not be affected at all.
Improved performance. A distributed DBMS fragments the database by keeping the data closer to where it is
needed most. Data localization
reduces the contention for CPU and I/O services and simultaneously reduces
access delays involved in wide area networks. When a large database is
distributed over multiple sites, smaller databases exist at each site. As a result,
local queries and transactions accessing data at a single site have better
performance because of the smaller local databases. In addition, each site has
a smaller number of transactions executing than if all transactions are
submit-ted to a single centralized database. Moreover, interquery and
intraquery parallelism can be achieved by executing multiple queries at
different sites, or by breaking up a query into a number of subqueries that
execute in parallel. This contributes to improved performance.
Easier expansion. In a distributed environment, expansion of
the system in terms of adding more
data, increasing database sizes, or adding more processors is much easier.
The transparencies we discussed in Section
25.1.2 lead to a compromise between ease of use and the overhead cost of
providing transparency. Total transparency provides the global user with a view
of the entire DDBS as if it is a single centralized system. Transparency is
provided as a complement to autonomy,
which gives the users tighter control over local databases. Transparency
features may be implemented as a part of the user language, which may
translate the required services into appropriate operations. Additionally,
transparency impacts the features that must be provided by the operating system
and the DBMS.
6. Additional Functions of Distributed
Databases
Distribution leads to increased complexity in
the system design and implementation. To achieve the potential advantages
listed previously, the DDBMS software must be able to provide the following
functions in addition to those of a centralized DBMS:
Keeping track of data distribution. The ability to keep track of the data
distribution, fragmentation, and replication by expanding the DDBMS catalog.
Distributed query processing. The ability to access remote sites and
transmit queries and data among the various sites via a communication network.
Distributed transaction management. The ability to devise execution strategies for queries and
transactions that access data from more than one site and to synchronize the
access to distributed data and maintain the integrity of the overall database.
Replicated data management. The ability to decide which copy of a
replicated data item to access and to maintain the consistency of copies of a
replicated data item.
Distributed database recovery. The ability to recover from individual site crashes and from new types of
failures, such as the failure of communication links.
Security. Distributed transactions must be executed with the proper
management of the security of the data and the authorization/access privileges
of users.
Distributed directory (catalog) management. A directory contains information (metadata)
about data in the database. The directory may be global for the entire DDB, or
local for each site. The placement and distribution of the directory are design
and policy issues.
These functions themselves increase the
complexity of a DDBMS over a centralized DBMS. Before we can realize the full
potential advantages of distribution, we must find satisfactory solutions to
these design issues and problems. Including all this additional functionality
is hard to accomplish, and finding optimal solutions is a step beyond that.
Related Topics