Chapter: Fundamentals of Database Systems : Additional Database Topics: Security and Distribution : Distributed Databases
Distributed Database Architectures
Distributed
Database Architectures
In this section, we first briefly point out the
distinction between parallel and distributed database architectures. While
both are prevalent in industry today, there are various manifestations of the
distributed architectures that are continuously evolving among large
enterprises. The parallel architecture is more common in high-performance
computing, where there is a need for multiprocessor architectures to cope with
the volume of data undergoing transaction processing and warehousing applications.
We then introduce a generic architecture of a distributed database. This is
followed by discussions on the architecture of three-tier client-server and
federated database systems.
1. Parallel versus Distributed
Architectures
There are two main types of multiprocessor
system architectures that are common-place:
Shared memory (tightly coupled) architecture. Multiple processors share secondary (disk) storage and also share primary memory.
Shared disk (loosely coupled) architecture. Multiple processors share secondary (disk)
storage but each has their own primary memory.
These architectures enable processors to
communicate without the overhead of exchanging messages over a network.4
Database management systems developed using the above types of architectures
are termed parallel database management
systems rather than DDBMSs, since
they utilize parallel processor technology.
Another type of multiprocessor architecture is called shared nothing architecture. In this architecture, every processor
has its own primary and secondary (disk) memory, no common memory exists, and
the processors communicate over a high-speed interconnection network (bus or
switch). Although the shared nothing architecture resembles a distributed
database computing environment, major differences exist in the mode of
operation. In shared nothing multiprocessor systems, there is symmetry and
homogeneity of nodes; this is not true of the distributed database environment
where heterogeneity of hardware and operating system at each node is very
common. Shared nothing architecture is also considered as an environment for parallel
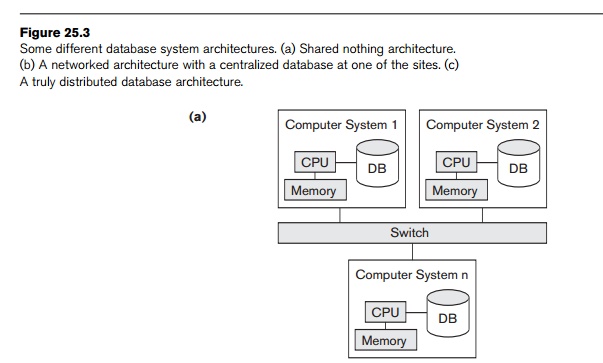
databases. Figure 25.3a illustrates a parallel database (shared nothing),
whereas Figure 25.3b illustrates a centralized database with distributed access
and Figure 25.3c shows a pure distributed database. We will not expand on
parallel architectures and related data management issues here.
2. General Architecture of Pure Distributed
Databases
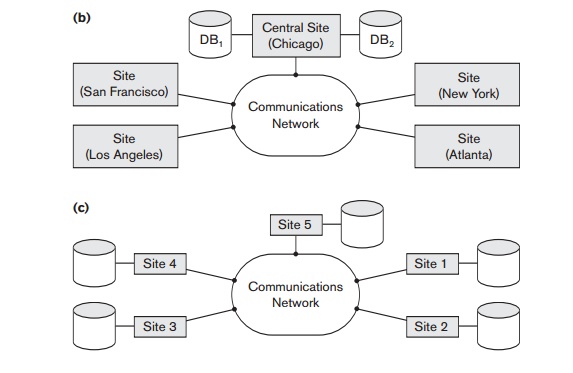
In this section we discuss both the logical and
component architectural models of a DDB. In Figure 25.4, which describes the
generic schema architecture of a DDB, the enterprise is presented with a
consistent, unified view showing the logical structure of underlying data
across all nodes. This view is represented by the global conceptual schema
(GCS), which provides network transparency (see Section 25.1.2). To accommodate
potential heterogeneity in the DDB, each node is shown as having its own local
internal schema (LIS) based on physical organization details at that
particular site. The logical organization of data at each site is specified by
the local conceptual schema (LCS). The GCS, LCS, and their underlying mappings
provide the fragmentation and replication transparency discussed in Section
25.1.2. Figure 25.5 shows the component architecture of a DDB. It is an
extension of its centralized counterpart (Figure 2.3) in Chapter 2. For the
sake of simplicity, common elements are not shown here. The global query
compiler references the global conceptual schema from the global system catalog
to verify and impose defined constraints. The global query optimizer references
both global and local conceptual schemas and generates optimized local queries
from global queries. It evaluates all candidate strategies using a cost
function that estimates cost based on response time (CPU,
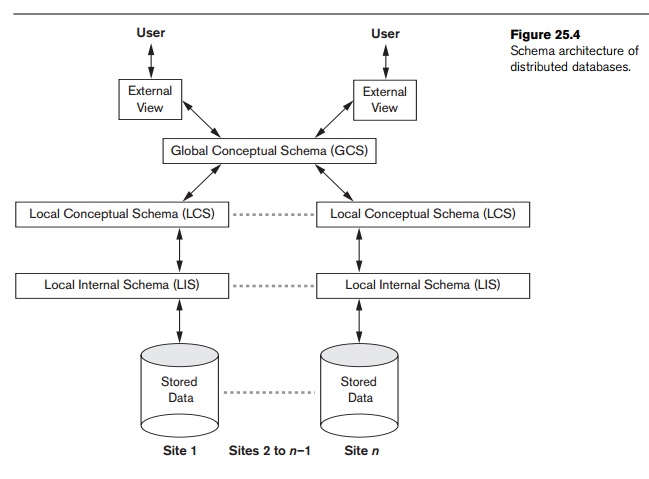
I/O, and network latencies) and estimated sizes
of intermediate results. The latter is particularly important in queries
involving joins. Having computed the cost for each candidate, the optimizer
selects the candidate with the minimum cost for execution. Each local DBMS
would have their local query optimizer, transaction man-ager, and execution
engines as well as the local system catalog, which houses the local schemas.
The global transaction manager is responsible for coordinating the execution
across multiple sites in conjunction with the local transaction manager at
those sites.
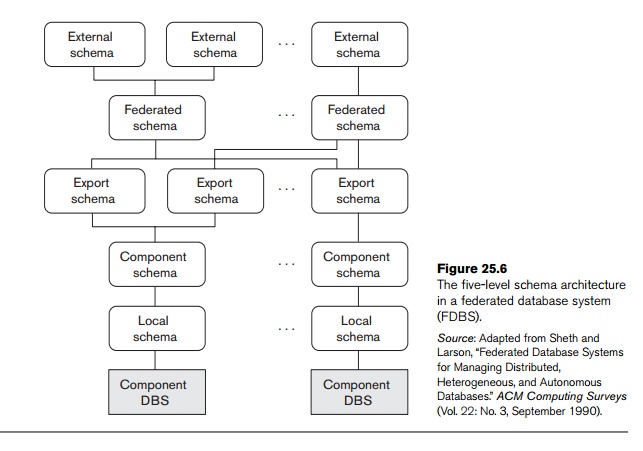
3. Federated Database Schema Architecture
Typical five-level schema architecture to
support global applications in the FDBS environment is shown in Figure 25.6. In
this architecture, the local schema
is the conceptual schema (full database definition) of a component database,
and the component schema is derived
by translating the local schema into a canonical data model or common data model (CDM) for the FDBS. Schema translation
from the local schema to the component schema is accompanied by generating
mappings to transform commands on a component schema into commands on the corres-ponding
local schema. The export schema
represents the subset of a component schema that is available to the FDBS. The federated schema is the global schema
or view, which is the result of integrating all the shareable export schemas.
The external schemas define the
schema for a user group or an application, as in the three-level schema architecture.
All the problems related to query processing,
transaction processing, and directory and metadata management and recovery
apply to FDBSs with additional considerations. It is not within our scope to
discuss them in detail here.
4. An Overview of Three-Tier
Client-Server Architecture
As we pointed out in the chapter introduction,
full-scale DDBMSs have not been developed to support all the types of
functionalities that we have discussed so far. Instead, distributed database
applications are being developed in the context of the client-server
architectures. We introduced the two-tier client-server architecture in Section
2.5. It is now more common to use a three-tier architecture, particularly in
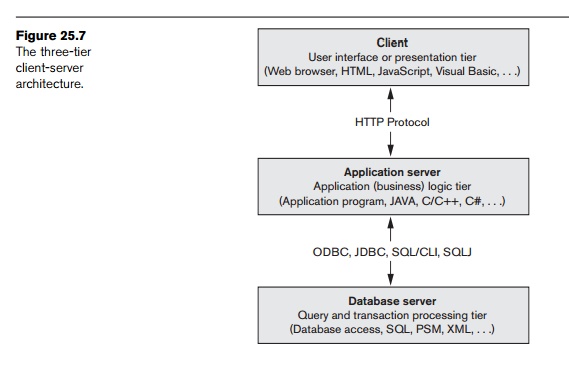
Web applications. This architecture is illustrated in Figure 25.7.
In the three-tier client-server architecture,
the following three layers exist:
1. Presentation layer (client). This provides the user interface and interacts with the user. The programs at this layer present Web interfaces or forms to the client in order to interface with the application. Web browsers are often utilized, and the languages and specifications used include HTML, XHTML, CSS, Flash, MathML, Scalable Vector Graphics (SVG), Java, JavaScript, Adobe Flex, and others. This layer handles user input, output, and naviga-tion by accepting user commands and displaying the needed information, usually in the form of static or dynamic Web pages. The latter are employed when the interaction involves database access. When a Web interface is used, this layer typically communicates with the application layer via the HTTP protocol.
2. Application
layer (business logic). This
layer programs the application logic.
For example, queries can be formulated based on user input from the client, or
query results can be formatted and sent to the client for presentation.
Additional application functionality can be handled at this layer, such
as security checks, identity verification, and
other functions. The application layer can interact with one or more databases
or data sources as needed by connecting to the database using ODBC, JDBC,
SQL/CLI, or other database access techniques.
3. Database server. This layer handles query and update requests from the application layer, processes the requests, and sends the results. Usually SQL is used to access the database if it is relational or object-relational and stored database procedures may also be invoked. Query results (and queries) may be formatted into XML (see Chapter 12) when transmitted between the application server and the database server.
Exactly how to divide the DBMS functionality
between the client, application server, and database server may vary. The
common approach is to include the functionality of a centralized DBMS at the
database server level. A number of relational DBMS products have taken this
approach, where an SQL server is
provided. The application server must then formulate the appropriate SQL
queries and connect to the database server when needed. The client provides the
processing for user inter-face interactions. Since SQL is a relational
standard, various SQL servers, possibly provided by different vendors, can
accept SQL commands through standards such as ODBC, JDBC, and SQL/CLI (see
Chapter 13).
In this architecture, the application server
may also refer to a data dictionary that includes information on the
distribution of data among the various SQL servers, as well as modules for
decomposing a global query into a number of local queries that can be executed
at the various sites. Interaction between an application server and database
server might proceed as follows during the processing of an SQL query:
1. The application server formulates a user query based on input from the client layer and decomposes it into a number of independent site queries. Each site query is sent to the appropriate database server site.
2. Each database server processes the local query and sends the results to the application server site. Increasingly, XML is being touted as the standard for data exchange (see Chapter 12), so the database server may format the query result into XML before sending it to the application server.
3. The application server combines the results of the subqueries to produce the result of the originally required query, formats it into HTML or some other form accepted by the client, and sends it to the client site for display.
The application server is responsible for
generating a distributed execution plan for a multisite query or transaction
and for supervising distributed execution by sending commands to servers.
These commands include local queries and transactions to be executed, as well
as commands to transmit data to other clients or servers. Another function
controlled by the application server (or coordinator) is that of ensuring
consistency of replicated copies of a data item by employing distributed (or
global) concurrency control techniques. The application server must also ensure
the atomicity of global transactions by performing global recovery when certain
sites fail.
If the DDBMS has the capability to hide the details of data distribution
from the application server, then it enables the application server to execute
global queries and transactions as though the database were centralized,
without having to specify the sites at which the data referenced in the query
or transaction resides. This property is called distribution transparency. Some DDBMSs do not provide distribution
transparency, instead requiring that applications are aware of the details of
data distribution.
Related Topics