Chapter: Embedded Systems Design : Writing software for embedded systems
The compilation process
The compilation process
When using a high level language compiler with an IBM PC or UNIX system,
it is all too easy to forget all the stages that are encountered when source
code is compiled into an execut-able file. Not only is a suitable compiler
needed, but the appropriate run-time libraries and linking loader to combine
all the modules are also required. The problem is that these may be well
integrated for the native system, PC or work-station, but this may not be the
case for a VMEbus system, where the hardware configuration may well be unique.
Such cross-compilation methods, where software for another proc-essor or target
is generated on a different machine, are attrac-tive if a suitable PC or
workstation is available, but can require work to create the correct software environment.
However, the popularity of this method, as opposed to the more traditional use
of a dedicated development system, has increased dra-matically. It is now
common for operating systems to support cross-compilation directly, rather than
leaving the user to piece it all together.
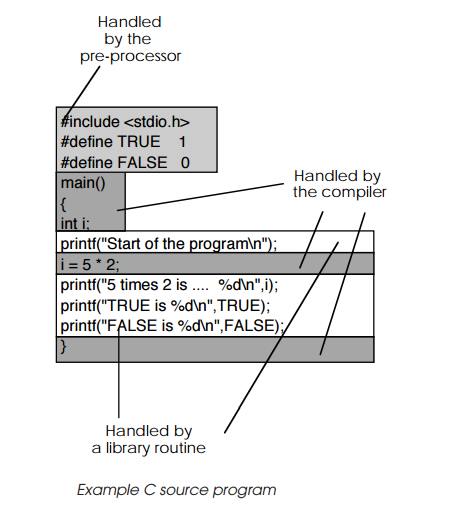
Compiling code
Like many compilers, such as PASCAL or C, the high level language only
generates a subset of its facilities and commands from built-in routines and
relies on libraries to provide the full range of functions. These libraries use
the simple commands to create well-known functions, such as printf
and scanf from the
C language, which print and interpret data. As a result, even
a simple high level language program involves several stages and requires
access to many special files.
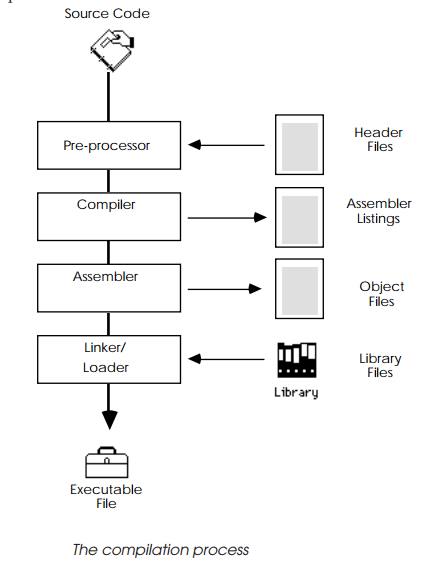
The first stage involves pre-processing the source, where include files
are added to it. These files define constants, standard functions and so on.
The output of the pre-processor is fed into the compiler, where it produces an
assembler file using the native instruction codes for the processor. This file
may have references to other software files, called libraries. The assembler
file is next assembled and converted into an object file.
This contains the hexadecimal coding for the instruc-tions, except that
memory addresses and file references are not completed; these are resolved by
the loader (sometimes known as a linker) that finally creates an executable
file. The loader calculates all the memory addresses and takes software
rou-tines from library files to supply the standard functions called by the
program.
The pre-processor
The pre-processor, as its name suggests, processes the source code
before it goes through the compiler. It allows the programmer to define
constants, variable types and other information. It also includes other files (include files) and combines them into
the program source. These tasks can be conditionally performed, depending on
the value of constants, and so on. The pre-processor is programmed using one of
five basic commands which are inserted into the C source.
#define
#define identifier string
This statement replaces all occurrences of identifier with string. The
normal convention is to put the identifier in capital letters so it can easily
be recognised as a pre-processor state-ment. In this example it has been used
to define the values of TRUE and FALSE. The main advantage of this is usually
the ability to make C code more readable by defining names to be certain values.
Statements like if i == 1 can be
replaced in the code by i == TRUE which
makes their meaning far easier to understand. This technique is also used to
define constants, which also make the code easier to understand.
One important point to remember is that the substitu-tion is literal,
i.e. the identifier is replaced by the string, irre-spective of whether the
substitution makes sense. While this is not usually a problem with constants,
some programs use #define to replace
part or complete program lines. If the wrong
substitution or definition is made, the resulting program line may cause
errors which are not immediately apparent from looking at the program lines.
This can also cause problems with different compiler syntax where the
definition is valid and accepted by one compiler but rejected by another. This
prob-lem can be solved by using the #define
to define different versions. This is usually done with using the #if def variation of the #define statement.
It is possible to supply definitions from the C compiler command line
direct to the pre-processor, without having to edit the file to change the
definitions, and so on. This often allows features for debugging to be switched
on or off, as required. Another use for this command is with macros.
#define MACRO() statement
#define MACRO() statement
It is possible to define a macro which is used to condense code either
for space reasons or to improve its legibility. The format is #define, followed by the macro name and
the argu-ments, within brackets, that it will use in the statement. There
should be no space between the name and the brackets. The statement follows the
bracket. It is good practice to put each argument within the statement in
brackets, to ensure that no problems are encountered with strange arguments.
#define
SQ(a) ((a)*(a))
#define
MAX(i,j) ((i) > ( j) ? (i) : (j))
...
..
x = SQ(56);
z = MAX(x,y);
#include
#include “filename” #include <filename>
This statement takes the contents of a file name and includes it as part
of the program code. This is frequently used to define standard constants,
variable types, and so on, which may be used either directly in the program
source or are expected by any library routines that are used. The difference
between the two forms is in the file location. If the file name is in quotation
marks, the current directory is searched, followed by the standard directory —
usually /usr/include. If angle
brackets are used instead, only the standard directory is searched.
Included files are usually called header files and can themselves have
further #include statements. The
examples show what happens if a header file is not included.
#ifdef
#ifdef identifier code
#else
code
#endif
This statement conditionally includes code, depending on whether the
identifier has been previously defined using a #define statement. This is extremely useful for conditionally altering the program, depending on
definitions. It is often used to insert machine dependent software into
programs. In the example, the source was edited to comment out the CPU_68000
definition so that cache control information was included and a congratulations
message printed. If the CPU_68040 defini-tion had been commented out and the
CPU_68000 enabled, the reverse would have happened — no cache control software
is generated and an update message is printed. Note that #ifndef is true when the identifier does not exist and is the
opposite of #ifdef. The #else and its associated code routine
can be removed if not needed.
#define
CPU_68040 /*define CPU_68000 */ #ifdef CPU_68040
/*
insert code to switch on caches */ else
/*
Do nothing ! */ #endif
#ifndef
CPU_68040
printf(“Considered
upgrading to an MC68040\n”); #else
printf(“Congratulations
!\n”); #endif
#if
#if expression code
#else
code
#endif
This statement is similar to the previous #ifdef, except that an expression is evaluated to determine whether
code is included. The expression can be any valid C expression but should be
restricted to constants only. Variables cannot be used because the pre-processor
does not know what values they have. This is used to assign values for memory
locations and for other uses which require constants to be changed. The total
memory for a program can be defined as a constant and, through a series of #if statements, other constants can be
defined, e.g. the size of data arrays, buffers and so on. This allows the
pre-processor to define resources based on a single constant and using
different algorithms — without the need to edit all the constants.
Compilation
This is where the processed source code is turned into assembler modules
ready for the linker to combine them with the run-time libraries. There are
several ways this can be done. The first may be to generate object files
directly without going through a separate assembler stage. The usual approach
is to create an assembler source listing which is then run through an assembler
to create an object file. During this process, it is sometimes possible to
switch on automatic code optimisers which examine the code and modify it to
produce higher performance.
The standard C compiler for UNIX systems is called cc and from its command line, C programs can be pre-processed,
compiled, assembled and linked to create an executable file. Its basic options
shown below have been used by most compiler writers and therefore are common to
most compilers, irrespec-tive of the platform. This procedure can be stopped at
any point and options given to each stage, as needed. The options for the
compiler are:
-c Compiles as far as the linking
stage and leaves the object file (suffix .o). This is used to compile programs
to form part of a library.
-p Instructs the compiler to produce
code which counts the number of times each routine is called. This is the
profiling option which is used with the prof utility to give statistics on how
many subroutines are called. This information is extremely useful for finding
out which parts of a program are consuming most of the processing time.
-f Links the object program with the
floating point software rather than using a hardware processor. This option is
largely historic as many processors now have floating point co-processors. If
the system does not, this option performs the calculations in software — but
more slowly.
-g Generates symbolic debug information
for debuggers like sdb. Without this information, the debugger can only work at
assembler level and not print variable values and so on. The symbolic
information is passed through the compilation process and is stored in the
executable file it produces.
-O Switch on the code optimiser to
optimise the program and improve its performance. An environment variable OPTIM
controls which of two levels is used. If OPTIM=HL (high level), only the higher
level code is optimised. If OPTIM=BOTH,
the high level and object code optimisers are both invoked. If OPTIM is not
set, only the object code optimiser is used. This option cannot be used with
the -g flag.
-Wc,args Passes the arguments args to the
compiler process indicated by c, where c is one of p012al and stands for
pre-processor, compiler first pass, compiler second pass, optimiser, assembler
and linker, respectively.
-S Compiles the named C programs and
generates an assembler language output file only. This file is suffixed .s.
This is used to generate source listings and allows the programmer to relate
the assembler code generated by the compiler back to the original C source. The
standard compiler does not insert the C source into assembler output, it only
adds line references.
-E Only runs the pre-processor on
the named C programs and sends the result to the standard output.
-P Only runs the pre-processor on
the named C programs and puts the result in the corresponding files suffixed
.i.
-Dsymbol Defines a symbol to the
pre-processor. This mechanism is useful in defining a constant which is then
evaluated by the pre-processor, without having to edit the original source.
-Usymbol Undefine symbol to the
pre-processor. This is useful in disabling pre-processor statements.
-ldir Provides an alternative directory
for the pre-processor to find #include files. If the file name is in quotes,
the pre-processor searches the current directory first, followed by dir and
finally the standard directories.
Here is an example C program and the assembler listing it produced on an
MC68010-based UNIX system. The assem-bler code uses M68000 UNIX mnemonics.
$cat
math.c main()
{
int a,b,c; a=2;
b=4;
c=b-a;
b=a-c;
exit();
}
$cat math.s
file “math.c”
data 1
text
def main; val main; scl 2; type 044; endef
global main
main:
ln 1
def ~bf; val ~; scl 101; line 2; endef
link.l %fp,&F%1
#movm.l &M%1,(4,%sp)
#fmovm &FPM%1,(FPO%1,%sp)
def a; val -4+S%1; scl 1; type 04;
endef
def b; val -8+S%1; scl 1; type 04;
endef
def c; val -12+S%1; scl 1; type 04;
endef
ln 4
mov.l &2,((S%1-4).w,%fp)
ln 5
mov.l &4,((S%1-8).w,%fp)
ln 6
mov.l ((S%1-8).w,%fp),%d1
sub.l ((S%1-4).w,%fp),%d1
mov.l %d1,((S%1-12).w,%fp)
ln 7
mov.l ((S%1-4).w,%fp),%d1
sub.l ((S%1-12).w,%fp),%d1
mov.l %d1,((S%1-8).w,%fp)
ln 8
jsr exit
L%12:
def ~ef; val ~; scl 101; line 9; endef
ln 9
#fmovm (FPO%1,%sp),&FPM%1
#movm.l (4,%sp),&M%1
unlk %fp
rts
def main; val ~; scl -1; endef
set S%1,0
set T%1,0
set F%1,-16
set FPO%1,4
set FPM%1,0x0000
set M%1,0x0000
data 1
$
as assembler
After the compiler and pre-processor have finished their passes and have
generated an assembler source file, the assem-bler is used to convert this to
hexadecimal. The UNIX assem-bler differs from many other assemblers in that it
is not as powerful and does not have a large range of built-in macros and other
facilities. It also frequently uses a different op code syntax from that
normally used or specified by a processor manufacturer. For example, the
Motorola MC68000 MOVE instruction
becomes mov for the UNIX assembler.
In some cases, even source and destination operand positions are swapped and
some instructions are not supported. The assem-bler has several options:
-o objfile Puts the assembler output into
file objfile instead of replacing the input file’s .s suffix with .o.
-n Turns off long/short address
optimisation. The default is to optimise and this causes the assembler to use
short addressing modes whenever possible. The use of this option is very
machine dependent.
-m Runs the m4 macro pre-processor
on the source file.
-V Writes the assembler’s version
number on standard error output.
Linking and loading
On their own, object files cannot be executed as the object file
generated by the assembler contains the basic pro-gram code but is not
complete. The linker, or loader as it is also called, takes the object file and
searches library files to find the routines it calls. It then calculates all
the address references and incorporates any symbolic information. Its final
task is to create a file which can be executed. This stage is often referred to
as linking or loading. The linker gives the final control to the programmer
concerning where sections are located in memory, which routines are used (and
from which libraries) and how unresolved references are reconciled.
Symbols, references and relocation
When the compiler encounters a printf() or similar statement in a program, it creates an external reference
which the linker interprets as a request for a routine from a library. When the
linker links the program to the library file, it looks for all the external
references and satisfies them by searching either default or user defined
libraries. If any of these refer-ences cannot be found, an error message
appears and the process aborts. This also happens with symbols where data types
and variables have been used but not specified. As with references, the use of
undefined symbols is not detected until the linker stage, when any unresolved
or multiply defined symbols cause an error message. This situation is similar
to a partially complete jigsaw, where there are pieces missing which represent
the object file produced by the assembler. The linker supplies the missing
pieces, fits them and makes sure that the jigsaw is complete.
The linker does not stop there. It also calculates all the addresses
which the program needs to jump or branch to. Again, until the linker stage,
these addresses are not calculated because the sizes of the library routines
are not known and any calculations performed prior to this stage would be
incorrect. What is done is to allocate enough storage space to allow the
addresses to be inserted. Although the linker normally locates the program at
$00000000 in memory, it can be instructed to relocate either the whole or part
of the code to a different memory location. It also generates symbol tables and
maps which can be used for debugging.
As can be seen, the linker stage is not only complicated but can also be
extremely complex. For most compilations, the defaults used by the compiler are
more than adequate.
ld linker/loader
As explained earlier, an object file generated by the assembler contains
the basic program code but is not complete and cannot be executed. The command ld takes the object file and searches
library files to find the routines it calls. It calcu-lates all the address
references and incorporates any symbolic information. Its final task is to
create a COFF (common object format file) file which can be executed. This
stage is often referred to as linking or loading and ld is often called the linker or loader. ld gives the final control to the programmer concern-ing where
sections are located in memory, which routines are used (and from which
libraries) and how unresolved refer-ences are reconciled. Normally, three
sections are used — .text for the
actual code, and .data and .bss for data. Again, there are several
options:
-a Produces an absolute file
and gives warnings for undefined references. Relocation information is stripped
from the output object file unless the option is given. This is the default if
no option is specified.
-e epsym Sets the start address
for the output file to epsym.
-f fill Sets the default fill
pattern for holes within an output section. This is space that has not been
used within blocks or between blocks of memory. The argument fill is a 2 byte
constant.
-lx Searches library libx.a,
where x contains up to seven characters. By default, libraries are located in
/lib and /usr/lib. The placement of this option is important because the
libraries are searched in the same order as they are encountered on the command
line. To ensure that an object file can extract routines from a library, the
library must be searched after the file is given to the linker. Common values
for x are c, which searches the standard C library and m, which accesses the
maths library.
-m Produces a map or listing of the
input/output sections on the standard output. This is useful when debug- ging.
-o outfile Produces an output object file
called outfile. The name of default object file is a.out.
-r Retains relocation entries in the
output object file. Relocation entries must be saved if the output file is to
become an input file in a subsequent ld session.
-s Strips line number entries and
symbol table informa- tion from the output file — normally to save space.
-t Turns off the warning about
multiply-defined symbols that are not of the same size.
-usymname Enters symname as an
undefined symbol in the symbol table.
-x Does not preserve local symbols
in the output symbol table. This option reduces the output file size.
-Ldir Changes the library search order
so libx.a looks in dir before /lib and /usr/lib. This option needs to be in
front of the -l option to work!
-N Puts the data section immediately
after the text in the output file.
-V Outputs a message detailing the
version of ld used.
-VS num Uses num as a decimal version
stamp to identify the output file produced.
Related Topics