Chapter: XML and Web Services : Building XML-Based Applications : Architecting Web Services
The Service-Oriented Architecture (SOA)
The Service-Oriented Architecture (SOA)
Web Services can be thought of as components that can be described,
published, located, and invoked over the Internet (or in general, any network).
The true power of Web Services, however, comes from the fact that all these activities
can take place at runtime. In essence, Web Services can figure out how to work
with each other, without having been designed to do so specifically.
In order for Web Services to be able to work well together, they must
participate in a set of shared organizing principles we call a service-oriented architecture (SOA). The
term service-oriented means that the
architecture is described and organized to support Web Services’ dynamic, automated description, publication, discovery,
and use.
The SOA organizes Web Services into three basic roles: the service
provider, the service requester, and the service registry. The relationships
among these three roles are shown in Figure 14.2.
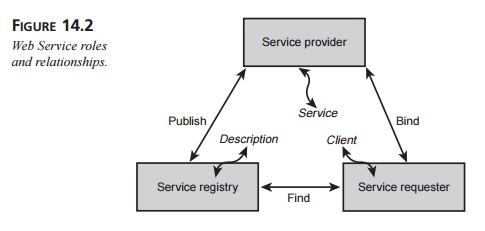
Service providers publish (and unpublish) their services to a service
registry. Then, ser-vice requesters can find the desired Web Services by
searching for their descriptions at the service registry. Once the requester
locates the desired service, its client binds with the service at the service
provider and then invokes the service.
The SOA is responsible for describing and organizing the mechanisms and
practices for each of these actions. In addition, the SOA is responsible for
describing how Web Services can be combined into larger services.
Flexibility of E-Business Services
The ability of Web Services to discover, bind to, and invoke other
services automatically at runtime—what we call Just In Time (JIT) integration—is actually a tall order for any
component in a distributed system to fill. JIT integration presupposes that the
SOA has reached critical mass across the globe, where there is a sufficient
number of Web Services exposing their interfaces available for discovery and
invocation. Furthermore, how are we ever going to get to that global SOA if we
don’t already have a mature set of Web Services protocols that everyone agrees
upon?
The fact of the matter is, there needs to be a way to bootstrap the SOA
so that we can build it piece by piece, even though the underlying protocols
are still maturing. Fortunately, this flexibility is built into the SOA,
because although it would be really nice for Web Services to support discovery,
binding, and invocation at runtime, these features are actually not required in
order to use Web Services.
In fact, the SOA provides for a hierarchy of integration options, as
shown in Figure 14.3.
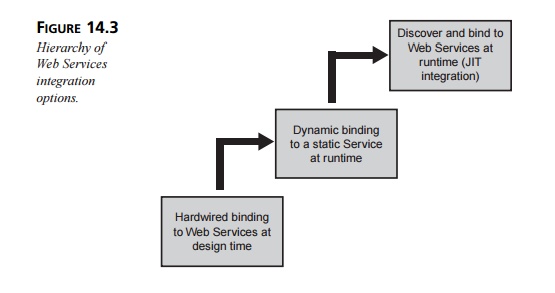
At the lowest level, Web Services are “hardwired” at design time. This
option essentially mimics a tightly coupled distributed architecture such as a
client/server or n-tier
archi-tecture. The developer handles the discovery manually and codes the
interface to the desired service into the service requester.
At the next level, the desired Web Service is also identified
beforehand, but the service requester is smart enough to bind to it dynamically
at runtime. In this way, the service requester can vary its request to the
service provider, depending on the particular situa-tion. In addition, the
service provider can change its interface from time to time (say, as part of a
functionality upgrade), and service requesters will be able to adjust to the
change on-the-fly.
The third level indicates JIT integration to the service provider: The
service requester can search a registry dynamically for a provider and then
bind to the one it selects. This is the only level that requires the
participation of a service registry.
Lessons Learned from Object Orientation
There are several features an architecture must
have to be considered object oriented
(OO). An OO architecture’s most important features are encapsulation, message
sending, and hierarchical inheritance. Of these, the organizing power of class
hierarchies has turned out to be the most useful feature of all, because class
hierarchies allow the soft-ware-development process itself to scale.
Architectures that share encapsulation and message sending, but not
inheritance, are referred to as object
based. Object-based architectures are not nearly as powerful as
object-oriented ones, for several reasons. First, encapsulation tends to make
an applica-tion brittle, because an object’s internal functionality can be
difficult to update without breaking the system. Second, sending messages by
exposing methods for remote objects to call is inefficient: If a remote object
has a number of requests for an object, it must make a number of method calls,
as opposed to one call that marshals all the requests.
The important lesson that the SOA can learn from object-oriented
architectures is that the organizing power of the SOA is the key to its
success: The way that Web Services are published, located, invoked, and
organized over the Internet is much more important than the internal structure
of the Web Services themselves, or the specifics of the mes-sage protocols that
enable the communication among services.
Architectures that focus on the details of how Web Services communicate,
rather than what they say to each other, are called service-based architectures (corresponding to the distinc-tion
between object-oriented and object-based architectures). Now, service-based
archi-tectures are still useful, but not nearly as powerful as the SOA in a
global e-business environment. Instead, service-based architectures are most
useful within a single enterprise, where a single architecture team can define
and manage the semantics behind the services.
Key Functional Components
The SOA has four key functional components: service implementation,
publication, dis-covery, and invocation. This section introduces the
architectural issues involved in each of these functional components. In
essence, we’ll provide a conceptual framework for the various protocols and
technologies detailed in Chapters 15, “Web Services Building Blocks: SOAP,” and
16, “Web Services Building Blocks: WSDL and UDDI.”
Service Implementation
There are two basic approaches to building a Web Service: Build one from
scratch, or provide a wrapper to an existing application or service so that it
exposes a Web Service interface. As Web Services become more prevalent,
developers will also have another set of options: Creating a new service
interface for an existing Web Service, or taking advan-tage of an existing
service interface to act as a skeleton for building or modifying a Web Service.
Combining the choice of service interface with the two basic approaches to
building a Web Service gives developers four methods for building Web Services:
Develop a new Web Service and a new service interface. This “green field” method gives
the developer the most leeway and is the most straightforward of the different
methods. The best approach is simply to develop the Web Service as specified by
the business requirements, define its interface, and then publish the interface
and deploy the Web Service. This approach may be the most practical today,
given the lack of existing Web Services. However, it will be the most expensive
option.
Develop a new Web Service when there is an existing service interface. The best method to use in
this situation is a “top-down” approach. First, locate the existing service interface
by searching a registry of Web Services. Next, generate a service
implementation template, or skeleton,
that contains all the methods and parameters that the Web Service must support
to be in compliance with the interface. Then, develop the Web Service as
before. This approach will become increasingly practi-cal as useful Web
Services become more prevalent in existing registries.
Develop a new service interface for an existing application. You must develop a Web
Service wrapper for your existing application in this “bottom-up” method. The
wrapper then exposes the service interface. This approach will likely be the
least expensive but also the least flexible.
Create a Web Service that wraps an existing application when you have an
existing service interface. This method is the most complex
of the four, because you must first
find the service interface and then use it to generate the service
implementa-tion template (skeleton). You must then use this template to develop
the wrapper for the existing application.
Once your Web Service is complete and has a well-defined service
interface, the next step is to publish your Web Service.
Publication
There are three steps to publishing a Web Service:
Author the Web Service
description document. Written in the Web Services Description Language (WSDL),
this document describes what the Web Service will do, where it can be found,
and how to invoke it. (See Chapter 16 for a com-plete discussion of WSDL.)
Publish the Web Service
description document on a Web server so that it is accessi-ble to your desired
audience (typically the Internet or one company’s intranet, but it might also
be published to a private e-marketplace). It is also possible to
“direct-publish” the Web Service description to the service requester via
e-mail, FTP, or even sneakernet. Direct publication is only possible when the
access to the Web Service will be hardwired.
Publish the existence of your
document in a Web Services registry using the Universal Description, Discovery,
and Integration (UDDI) specification, which describes how Web Service
registries are organized and how to work with them. A key aspect to UDDI is the
UDDI registry, which acts as a repository for informa-tion about published Web
Services (more about UDDI in Chapter 16). UDDI reg-istries can be global,
public registries, or they can be restricted to an individual enterprise (for a
single application or department or for an enterprise portal) or to a closed
group of companies (say, an e-marketplace or a partner catalog). WSDL and UDDI
will be covered in Chapter 16.
Discovery
Once your Web Service appears in a registry, any application can
discover your service and therefore locate the Web Service description document
you published. UDDI reg-istries support pattern queries for automated lookups
and return the location of the WSDL file for the desired service. Once you have
obtained the location of this file in the form of a Uniform Resource Indicator
(URI), which is a generalization of the familiar Uniform Resource Locator (URL),
you are able to download the WSDL file itself.
Invocation
There are two steps to invoking a Web Service:
Author a client using the Simple Object Access Protocol (SOAP). The WSDL
file you downloaded contains the information you need to create a client using
SOAP.
Because you are authoring clients on-the-fly based
on information you found in the Web Service description document, you are able
to invoke the Web Service dynam-ically at runtime. For more information on
SOAP, see Chapter 15.
Make a SOAP call. Your client then creates a SOAP message describing
what it wants the remote Web Service to do and then sends it to the URI
specified in the WSDL document. Typically, the Web Service returns a SOAP
message in the format detailed in the Web Service description document.
Just In Time Integration
Just as early object-oriented programming attempts
looked a lot like the structural pro-gramming that preceded it, much of the
early work with Web Services and the SOA can be expected to look like objects
in OO architectures. However, just as programmers learned the true power of OO
architectures and went beyond the capabilities of structured programming, so
too will programmers learn the power of the SOA and go beyond what was
practical with the techniques that came before.
The JIT integration capabilities of the SOA provide
new organizing principles for the world of IT. Imagine an Internet full of Web
Services: some globally available, and oth-ers available on intranets or other
closed networks. This global set of Web Services grows and changes organically;
the owner of each one determines what functionality the service will have and
what interface it exposes, as well as which registries to submit the service
to. In this global picture there is no master architect or executive committee
who is responsible for maintaining the system. Instead, there’s a set of
simple, widely accepted open protocols that everybody is welcome to share.
So, if you were wondering why Web Services are
named as they are, here is the answer. Sure, they run on HTTP, which means they
drive on the same roads as the World
Wide Web. However, that’s not why they are “Web”
Services. No, it’s the global self-organizing power of technology based on
simple, open protocols that puts the “Web” into Web Services.
Semantic Issues and Taxonomies
Semantics refers to the meaning, in human and business terms, of a Web Service’s actions and parameters. Semantics have
always been a sticking point for any distributed system. For example, EDI’s
rigid approach to its document formats led to semantic ambi-guities. Business
partners who use EDI must have an ad hoc agreement on the semantics of the
fields in each document.
Object-oriented (OO) systems address the problem of semantics when the
systems are small, but ambiguity creeps in when OO systems are scaled up. In a
small OO imple-mentation, the naming conventions of the methods as well as
their signatures (the para-meters the methods take in different situations)
often connote to the developer the meaning of the methods and arguments. In a
large-scale system, however, the semantics of a given class cannot typically be
deduced by its interface alone. The problem only gets worse when many companies
(possibly in different countries) attempt to participate in a distributed
e-business system.
The advent of XML did little to cut through the morass of semantic
issues because of XML’s inherent extensibility. Due to the fact that the
meaning of given XML tags were specified in an XML document’s DTD or schema,
developers were welcome to create their own sets of definitions, leading to a
Tower of Babel situation.
While the work on semantic issues is ongoing, some of the developments
have been incorporated into the Web Services arena in the form of taxonomies. A taxonomy is a hierarchical
representation of a set of concepts: Think of an area of interest (say, a
verti-cal market) organized like a Yahoo! directory. UDDI registries take
advantage of tax-onomies, which can either be based on standard classifications
of businesses or custom built to serve special purposes. The simplest taxonomy
used in UDDI registries is geographical: country followed by political
division—for example, United States, Massachusetts or United Kingdom, Wales.
Because XML is self-describing, a Web Services description can refer to
any available schema as the basis for the services it describes. If the
description takes advantage of the taxonomies that are available in the service
registries that the service provider wishes to use, however, then service
requesters will be able to discover such services by looking up terms that have
meaning to the requester. Today, however, the use of taxonomies in UDDI
registries is still quite rudimentary.
Security and Quality of Service Issues
Up to this point, we have covered building, publishing, finding, and
invoking Web Services. Much of the nuts and bolts of the SOA is now in place.
However, in order to conduct e-business in the real world, a few features are
missing. Most notably, there must be a security infrastructure available for
Web Services. Equally important is the need for some way to guarantee different
levels of quality of service for messages sent to and from Web Services.
Security
Because Web Services typically run over HTTP and TCP/IP, many of the
security requirements for Web Services can be satisfied with the
well-established Secure Sockets Layer (SSL) protocol as well as the newer
Internet Protocol Security (IPSec) protocol. SSL applies specifically to
point-to-point messages sent over HTTP, whereas IPSec allows for the encryption
of messages on the network layer. Are these two standards suf-ficient for
securing Web Services, or is there a need for a more sophisticated or complete
Web Services security layer?
There are four basic requirements that a Web Services security layer
must provide:
Confidentiality. The contents of the messages
must not be available to unautho-rized parties.
Authentication. The sender of a message must be
authorized to send a message, and the
recipient of the message must be able to confirm the identity of the sender of
the message.
Data integrity. The recipient of a message must
be able to guarantee that the message
hasn’t been tampered with in transit.
Nonrepudiation. The recipient of a message must
be able to guarantee the circum-stances surrounding the sending of the message
(for example, the time the message was sent and the fact that the sender sent
only one copy of the message).
SSL and IPSec guarantee data integrity and confidentiality for messages
that go from the sender directly to the recipient, but they aren’t able to
provide authentication or nonrepu-diation. They are also unable to guarantee
either data integrity or confidentiality if there is a third-party intermediary
in between the sender and the recipient. Because SOAP messages are typically
processed by intermediaries, SSL and IPSec are most useful if there is a
preexisting trust relationship among sender, recipient, and intermediary. In
the world of Web Services, however, this is unlikely to happen very often.
It is also possible to secure the messages to and from Web Services at
the application layer or via a secure network. These two approaches may work
inside single enterprises but will not work when multiple companies exchange
Web Services messages. Instead, it makes more sense to include security
information as meta-information in the SOAP header. The SOAP specification
allows for such information but doesn’t actually specify it. (More about SOAP
headers in Chapter 15.) The security information to be sent in the SOAP headers
is some kind of asymmetric key message digest, as provided for by
authentication systems such as Kerberos and the Public Key Infrastructure
(PKI).
The problem with all asymmetric key systems is that they require the
services of a trusted third party. This third party must provide the ultimate
authority to generate the keys as well as provide a list of revoked
key-generation authorities. All parties involved in secure inter-actions among
Web Services must agree upon this trusted third party beforehand.
An adequate Web Services security layer, therefore, should contain both
IPSec or SSL (in particular, HTTP over SSL, which is abbreviated HTTPS) for
network security as well as some kind of asymmetric key technology for XML
message security. Until such time as the asymmetric key technology issues have
been resolved, SSL may be the best security available, even though it does not
provide authentication or nonrepudiation and only works “point to point.”
In addition to the security concerns that apply to
the XML messages that go between Web Services, there is also the question of
how service registries should secure their sys-tems. Depending on the
situation, there are three access control models that Web Service registries
might follow:
A promiscuous registry doesn’t
authenticate the publishers or the requesters. Such registries don’t make any
claims about the correctness of the data in the registry or the integrity of
the participants. Although a promiscuous registry is the simplest form of
registry to set up, its usefulness is limited by its lack of access control.
An authenticated registry
authenticates both service requesters and service pub-lishers. Because it knows
the identities of the parties involved in the registry, it can set up
coarse-grained access control for specific categories of data within the
reg-istry. Typically, such a registry would require communication via SSL and
might also include support for XML Digital Signatures so that it can validate
the XML messages it receives.
A fully
authorized registry goes beyond the security offered by authenticated
registries by implementing a fine-grained authorization paradigm, allowing it
to secure individual data entries by storing access information for each one.
Such a registry would have to support a more complex management and
administration infrastructure in order to enforce such complex security. A
fully authorized registry might also act as a public key authority, providing
the individual authority (often called certificates)
to both Web Services publishers and requesters necessary to generate the
asymmetric keys.
Quality of Service and Reliable Messaging
Quality of service (QoS) means different things at different layers. At
the network layer, QoS refers to the ability of the network to transmit
information with the desired accuracy and promptness. On the messaging layer,
however, QoS refers to the reliability of the messaging—that is, the ability of
the infrastructure to deliver a message exactly once to its intended recipient
or to deliver a particular error message (typically to the sender) if the
message cannot be sent.
The sending of messages to and from Web Services will fall into three
basic modes:
Best effort. The service requester sends the
request message, and neither the requester
nor the message infrastructure attempts a retransmission in the case of a
failure to deliver the message.
At least once. The service requester continues
to attempt to send the request until it receives
acknowledgment from the service provider that the message was received. As a
result, the service provider might receive more than one copy of the message.
If the request is a simple query, this duplication isn’t a major problem
(although it will contribute to network overhead). However, in other cases,
each message may need to carry a unique ID so that the service provider can
recognize a duplicate message. Along with its acknowledgment, the service
provider either sends the requested response or a “cannot process message”
exception.
Exactly once. The service requester makes its request, and the service provider
guarantees in its reply that the request has been executed (or it sends an
error message, if necessary). The “exactly once” mode of messaging requires an endpoint manager at either end of the
message to relay messages and guarantee responses
(which may simply be a timeout exception should the service provider fail to
respond). Endpoint managers also frequently support the queuing of messages or
more complex behaviors such as forwarding messages to other ervice providers.
The exactly once mode is only applicable when both endpoints participate in the
appropriate messaging infrastructure—for example, within an enterprise or
between two companies who have configured their joint messaging infrastructure
beforehand.
Although sophisticated messaging infrastructures are a possibility in
such controlled situ-ations, on the open Internet we must work within the
constraints of HTTP. HTTP man-dates a simple request/response mechanism with a
set of standard error messages, but it lacks most of the features of reliable
messaging. This is an area where more work must be done before business will be
able to use Web Services over the Internet reliably.
Composition and Conversations
So far, we have been looking at Web Services as individual components:
how to create, find, publish and implement single services. However, for Web
Services to be truly use-ful in a global e-business environment, there must be
a way to combine and coordinate collections of Web Services so they can be used
to support complex, real-world business processes. The ability to use
collections of Web Services falls into two general cate-gories: composition of Web Services and conversations among Web Services.
Composition of Web Services
Composition essentially means combining multiple individual Web Services
into larger components that are themselves Web Services. Composition of Web
Services falls into two broad categories:
Web Services can be combined within an enterprise in order to describe a
business process. In this case, the composition of the Web Services follows a
particular usage pattern.
Web Services from multiple
companies can be coordinated in order to describe partner interactions. In this
case, the composition of the Web Services follows a particular interaction pattern.
In addition, Web Services can be composed recursively. A Web Service that is recur-sively composed of other
Web Services can itself be used as a component in further com-positions of Web
Services.
Naturally, it makes sense to describe the composition of Web Services
with an open, XML-based description language. This avenue of research is still
very new, but the most progress has been made by IBM with its Web Services Flow
Language (WSFL). The WSFL is an XML-based description language that describes
both categories of Web Services in the preceding list.
In order to apply the WSFL, an enterprise would first identify a
business process that it wishes to implement with Web Services. Then it would
take that business process and identify the following:
The component business processes (typically implemented in the form of
existing Web Services) that make up the larger process.
The business rules that determine the sequence of steps that form the
business process.
The flow of information that joins the individual process steps.
From these elements, the enterprise would create the WSFL flow model
that defines the overall structure of the business process.
Conversations Among Web Services
A conversation between two
collaborating Web Services is a sequence of requests and responses that is
correlated into a particular group or unit of work. Conversations become
important when there is a need for transactional properties to apply to the
sequence of requests and responses.
The concept of a transaction
is fundamental to the application of distributed computing. Although database
transaction models and transaction-processing (TP) monitor program-ming models
are typically sufficient in existing heterogeneous enterprise IT environ-ments,
the Web Services model requires a more flexible mechanism for handling
transactional capabilities such as atomicity, phased commits, and rollbacks.
(See Chapter 15 for an in-depth discussion of transactional capabilities.) Some
differences between the two environments are as follows:
Within enterprises, applications
that support asynchronous messaging typically assume a chained,
multiple-transaction model when crossing different messaging systems. Web
Service collaborations, however, typically rely on asynchronous mes-sages
across enterprise boundaries and must support transactional capabilities in the
absence of a single messaging system.
The TP monitor infrastructure
that manages transactions in heterogeneous enter-prise environments typically
provides a single span of control for executing trans-actions. Such systems
must have sophisticated management and monitoring tools to avoid problems with
failures. Web Service collaborations across different enter-prises, however, have
multiple spans of control.
The ability of Web Service
requests to combine multiple method calls into a single request, combined with
the ability of Web Services to send and receive both syn-chronous and
asynchronous messages, means that multiple-company Web Service collaborations
will typically take much more time than the individual requests and responses
in traditional transactional environments.
Because of these fundamental differences between traditional
environments and the Web Services model, transactions must be handled
differently. We require a more incremental approach to transactional
capabilities, as follows:
First, we need an activity service that specifies the
operational context of a series of requests. Included in this operational
context are the duration of the activity, the participants involved, and a
description of the possible outcomes of the activity.
Next, there is a need for a conversation service that provides
request atomicity. Request atomicity guarantees that a particular set of Web
Service operations either happen completely or not at all. The endpoint manager
publishes the atomicity capability to the participants.
The conversation service must
also correlate sequences of requests into a single unit of work, by providing a
structure for conversations that includes indications of the beginning and end
of the conversations as well as success and failure outcomes. The conversation
service must be able to accept a rollback command from either participant, and
then it must provide the semantics of the rollback command to each participant.
Related Topics