Chapter: XML and Web Services : Building XML-Based Applications : Architecting Web Services
Architecting Web Services
Architecting Web Services
Software architects are at the vanguard of the software development
lifecycle. If Web Services truly represent a paradigm shift in how distributed
computing is performed, rather than merely an incremental improvement, it is up
to the architects first to under-stand this shift and then to communicate it to
their teams as well as their management.
Software architecture is a broad, somewhat-vague discipline that
includes elements of design, abstraction, and aesthetics, as well as a more
fundamental view of what really works and what doesn’t. Architects touch upon
the hardware, the network, the applica-tions, and the interfaces as well as the
users, the partners, and the marketplace. In order to architect complex,
multifaceted systems, including those made up of Web Services, architects must
exercise many ways of thinking and many ways of viewing the problems before
them.
One established model for how architects visualize the systems before
them is the 4+1 View Model of Software Architecture, popularized by Philippe
Kruchten of Rational Software.
Whereas the four blind men each touch the elephant in a different place and
therefore come to different understandings of it, the architect has clear
vision, seeing the elephant from all four views. As a result, the architect has
a comprehensive picture of the elephant.
This is the same with the 4+1 View Model. This model describes four
distinct ways of looking at the architecture for a system, plus a fifth view
that overlaps the others, as shown in Figure 14.4.
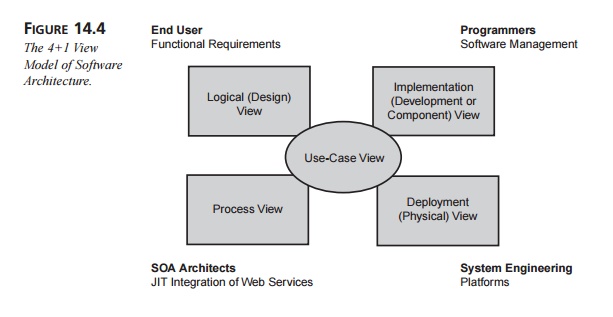
Each of the four main views takes the perspective of key stakeholders in
the development process. The fifth view, the Use-Case View, overlaps the other
views and plays a special role with regard to the architecture. This section
approaches the Web Services model from each of the four views, demonstrating
the different ways architects should envision Web Services. A discussion of the
Use-Case View closes out the chapter.
The Implementation Architectural View: The Web Services Technology Stack
In general, the Implementation View (also called
the Development or Component View) describes the
organization of the software artifacts and also addresses issues of software
management. The Implementation View of the SOA focuses on the Web Services
technology stack, as shown in Figure 14.5.
Figure 14.5 shows a conceptual Web Services
technology stack, where each layer on the left builds upon the capabilities of
the layer beneath it. The vertical columns on the right represent capabilities
that the architect must address at every level of the stack.
The base stack includes those technologies
necessary to create and invoke Web Services. At the bottom is the network
layer, which fundamentally allows Web Services to be available to service
requesters. Although HTTP is the de facto standard network protocol, the
architect may consider any of a number of other options, including SMTP (for
e-mail), FTP, IIOP, or messaging technologies such as MQ. Some of these choices
are request/response based, whereas others are message based; furthermore, some
are syn-chronous, whereas others are asynchronous. The architect may find that
in a large sys-tem, a combination of different network protocols is
appropriate.
In the next two layers, SOAP is the XML-based messaging protocol that
forms the basis for all interactions with Web Services. When running on top of
HTTP, SOAP messages are simple POST operations with SOAP’s XML envelope as the
payload. SOAP mes-sages support the publish, find, and bind operations that
form the basis of the SOA, as shown previously in Figure 14.2. (SOAP is covered
in depth in Chapter 15.)
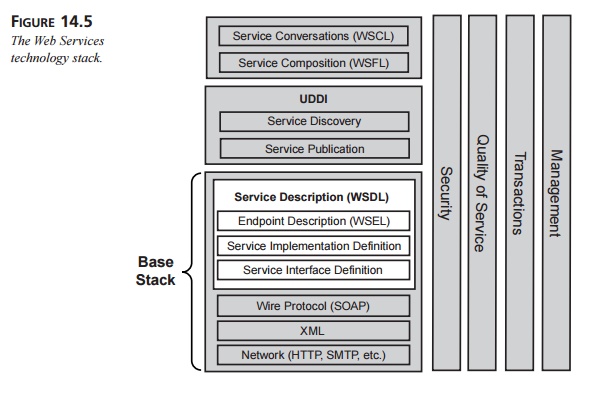
On top of the SOAP layer comes three layers that together form the
service description. WSDL is the de facto standard for service descriptions,
with the addition of the still-tentative WSEL for endpoint descriptions. The
service interface definition contains the binding, portType, message, and type elements, which form the portion of the service description that is reusable from
one implementation to another. (These elements are fully described in Chapter
16.)
The service implementation definition, however, contains those elements
that are specific to each implementation: the service and port elements. A third party (say, a standards body) might specify the
service interface definition for a particular type of Web Service, leaving the
service implementation definition up to each implementation team.
Next comes the endpoint description, which introduces semantics to the
service descrip-tions that apply to a particular implementation. Endpoint
descriptions can contain secu-rity, QoS, and management attributes that help to
define the policies for each of these vertical columns.
Once the architect has dealt with all the issues in the base stack, the
Web Services are essentially fully constructed. Next, the development team uses
UDDI to publish the services to a registry or another repository of information
about available Web Services. Once Web Services are published, UDDI can then be
used to discover them in the registries.
Only when the architect has dealt with the issues of service publication
and discovery can he move on to the more complex issues regarding the interaction
of multiple Web Services. The two protocols shown in Figure 14.5, WSFL and
WSCL, are still in development, and it’s not clear how these layers will be
handled in the future.
One important lesson to be gained from the Web Services stack is that security,
QoS, transactions, and service management each apply to every layer in the
stack. The architect must therefore consider the intersection of each vertical
column with each horizontal layer. For example, network security will likely be
handled by HTTPS (SSL over HTTP), but the security of individual messages may
still need to be handled by encrypted payloads and digital signatures, which
are incorporated into the SOAP header. Securing the base stack is relatively
straightforward, because it is internal to the enter-prise; securing Web
Services involved in publication and discovery across the Internet is another
issue entirely.
QoS, as well, means different things at each layer. Network QoS involves
network uptime, packet delivery, and valid HTTP messages. Reliable messaging,
however, depends heavily on the capabilities of the endpoint manager, which
uses WSEL or another endpoint description language. Transactions depend on
endpoint descriptions, as well.
Transactions, in fact, must be handled on multiple levels of the service
stack, because of the complexity of handling rollbacks in a multi-enterprise
Web Services environment. To roll back a particular conversation, each
operation within that conversation may need to be reversed. Alternatively, there
may need to be a way to remember the earlier state of multiple systems in order
to perform a rollback. In either case, there is no single span of control
managing the transactional environment. Transactions may be some of the most
intractable issues with Web Services today.
On top of all of these development and implementation concerns, the
architect must also think about the management of Web Services. Management of
Web Services will likely be handled by a management application, which may need
to be built in-house. This management application must be able to do the
following:
Determine the availability and
health of the Web Services infrastructure, in-cluding the network as well as
the physical systems that support the execution of the Web Services.
Determine the availability and
health of the internal Web Services themselves. Web Services may need to be
built with a management interface in order to support this level of management.
Determine the availability and
health of the service registries. Some of these reg-istries may be internal to
the enterprise, allowing for direct access to their inner workings, but other
registries are external and may only expose a minimal interface for external
management.
Determine the availability and
health of external Web Services, once they are dis-covered, attempt to invoke
them. Again, these services are external and may not provide a management
interface.
Control and configure all
internal systems, including the infrastructure as well as the Web Services
themselves.
These management requirements emphasize the need for a standard way of
building management interfaces for Web Services (as well as the infrastructure
that supports them). In addition, there is clearly a need for a reporting and
recovery process for pub-licly available Web Services (either on the open
Internet or available to specific business partners). Partners should be able
to access an interface that provides status reports on a company’s services and
infrastructure, without having to understand the details of how the company
manages its internal infrastructure.
The Logical Architectural View: Composition of
Web Services
The Logical (or Design) Architectural View starts
with the end user’s functional require-ments and provides a top-down abstraction
of the overall design of the system. In the case of B2B functionality (say, in
the case of processing a purchase order), the user interface may be handled
separately from the Web Services; therefore, the “end users” in this case are
the businesses themselves. In other cases, Web Services may provide
func-tionality to the user interface more directly.
In the B2B case, the functional requirements of a Web Services–based
system will typi-cally involve complex conversations among Web Services that
participate in multi-step business processes. In addition, the individual Web
Services involved are likely to be composed of component Web Services. As a
result, an architect working from the Logical View will likely be concerned
with workflows of Web Services.
For example, let’s take the case of a buyer’s Web Service contacting a
seller’s Web Service to make a purchase. Figure 14.6 shows a possible
(simplified) workflow for this interaction.
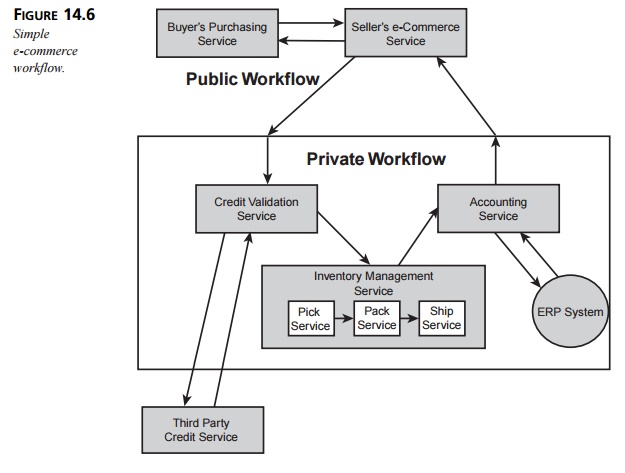
This workflow consists of two separate workflows: a
public workflow as well as one pri-vate to the seller. From the buyer’s point
of view, the seller is exposing a single public Web Service that is composed of
separate Web Services in succession.
The interfaces to the two public services are both
written in WSDL. The buyer has obtained the seller’s service description
beforehand—either by looking it up in a registry or through a prearranged
relationship between the buyer and the seller. The buyer uses the service
description to build the SOAP messages it exchanges with the seller.
Once the seller receives a request from the buyer, a sequence of
business processes within the private workflow takes place. First, a
credit-validation service sends a request to a third-party, credit-checking Web
Service, which it may have established a preexist-ing relationship with. This
third-party service is an example of an enabling
service. Depending on the response from the third-party service, the seller
continues with the e-commerce workflow or possibly sends a “credit rejected”
response back to the buyer. (The architect must consider both the “rejected”
special case as well as how to handle the situation where the third-party
credit service is unavailable.) In a more general case, it will likely not be
necessary to query this service if the seller has an established relationship
with the buyer.
Once the buyer’s credit is approved, the internal credit-validation
service sends a request to the inventory-management service. This service is
recursively constructed from indi-vidual component services (three of which are
shown for illustration purposes, but in reality such services would be more
complex). The architect must determine the interface for the
inventory-management service as well as detail the workflow that takes place within
the service.
The architect must work with several different elements in a complex
workflow like this one, including the following:
The sequencing rules that describe how the Web Services interact over
time.
The information flows between each of the services (including the
necessary data mapping).
The service providers responsible for executing each step. Is the
inventory-manage-ment service responsible for executing any of its internal
steps, or are they taken care of by the component services?
The associations between activities in the workflow.
The operations offered by each service provider.
The three component services within the inventory-management service may
also repre-sent applications that are not themselves Web Services. In such a
case, the inventory-management service is responsible for communicating with
each component via a preexisting framework, such as CORBA, DCOM, or J2EE.
Once the purchased item has been shipped (assuming there were no
errors), the account-ing service is responsible for interacting with the ERP
system. This system is an example of a component that is not itself a Web
Service. Typically, the architect will call for a wrapper that will present a
Web Service interface to the rest of the system. In this case, the accounting
service may itself be that wrapper, in which case the links between it and the
ERP system would be implemented with the APIs provided by the ERP system.
This simple example appears to be a synchronous system—that is, there is
a single, closed loop starting and ending at the buyer that every request
follows to completion. In reality, however, some of the processes will be
synchronous whereas others will be asyn-chronous. The inventory-management
service will likely communicate with the buyer through the public e-commerce
service to determine whether or not the product is in stock, and then the pick,
pack, and ship process will take place asynchronously. As a result, the
architect must also consider how the buyer (as well as the seller) will be able
to monitor and control the asynchronous inventory service.
If this is a B2B example, then the buyer’s purchasing service likely
ties into the buyer’s enterprise systems as part of its supply chain management
system. However, in a Business to Consumer (B2C) situation, the buyer’s
purchasing service might be hosted on a B2C Web site. In this situation, the user context is a primary concern
of the architect.
User context is a critical part of all consumer (and generally,
individual user) focused Web Services, including Microsoft’s .NET My Services
initiative as well as Sun’s SunONE framework.
The user context contains information about the
user as well as information about the user’s session, including the following:
Demographic information, credit card information, and so on
The user’s physical location
The user’s locale (the user’s language, currency, number format, and so
on)
The user’s security level and permissions
Personalization information that pertains to the Web site the user is
visiting, including merchandise preferences, calendar information, buddy lists,
and so on
The Deployment Architectural View: From Application Servers to
Peer-to-Peer
The Deployment (or Physical)
Architectural View maps the software to its underlying platforms, including the
hardware, the network, and the supporting software platforms. Today, Web
Services are hosted on application server platforms such as IBM’s WebSphere,
BEA’s WebLogic, and Microsoft’s Windows 2000. There are many benefits to
building Web Services on top of platforms like these: They handle database
access, load balancing, scalability, and interface support as well as provide a
familiar environ-ment for dealing with hardware and network issues.
Because Web Services typically exchange messages over HTTP, a Web server
is typi-cally the desired host for supporting a Web Service. Both the Microsoft
and the J2EE platforms share a similar developer model, as shown in Figure
14.7.
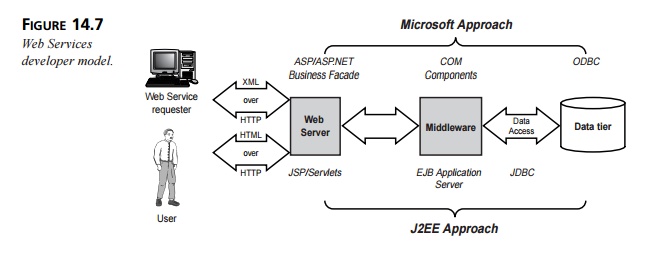
This model follows a traditional n-tier
architecture, except that the Web server is also responsible for sending and
receiving the XML messages that form the Web Services interface. The technology
that supports Web Services is therefore already well under-stood; the
fundamental difference between Web Services and Web pages is that pages are
intended for humans to read, whereas Web Services expose an interface intended
for machines.
Running Web Services off of Web servers is not the only way to support
the services, however. It is also possible to build Web Services on a
peer-to-peer (P2P) developer model. P2P, popularized by the Napster music
service, is a distributed architecture that does not rely on central servers
but rather distributes responsibility to systems (called peers) in the network. Unfortunately, P2P technologies are every
bit as new and bleeding edge as Web
Services, so only time will tell which P2P models will become established. The
self-organizing promise of Web Services does lend itself to P2P, but a lot of
work remains before we will see how this fascinating area will develop.
The Process Architectural View: Life in the Runtime
The Process Architectural View addresses all runtime issues, including
processes, concur-rency, and scalability. As the applications of Web Services
move up the hierarchy of Web Service integration options to JIT integration (as
shown previously in Figure 14.3), the Process Architectural View will take on
increasing importance. In fact, the Process Architectural View will be where
the bulk of the SOA architect’s work will take place.
For example, let’s take another look at the simple e-commerce workflow
in Figure 14.6. If you just look at the figure, you might think that there’s
nothing much new here; this diagram could represent an e-commerce system based
on a simple n-tier architecture.
The reason that the diagram doesn’t immediately demonstrate the power of
the Web Services model is that in the diagram, the buyer has already identified
the seller, the seller has already identified its third-party credit service,
and the seller’s private work-flow is already put in place. If all these
statements are in fact true, then, yes, Web Services has little to offer over
traditional n-tier architectures. On
the other hand, let’s take a JIT approach, as shown in Figure 14.8.
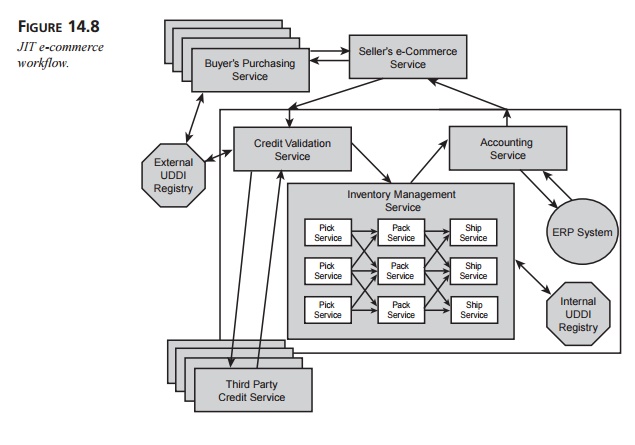
Figure 14.8 shows an e-commerce workflow much like the one in Figure
14.6, except that multiple buyers have looked up the seller in a registry and
have chosen to invoke the seller’s e-commerce service. Likewise, the seller
looks up third-party credit services in an external registry and looks up pick,
pack, and ship services in an internal registry. (As before, these three
services are used as examples rather than to indicate how inventory management
would actually take place.) The inventory-management service then selects the
internal components on-the-fly at runtime.
This example begs the following questions: What if the buyer sends an
automatic query to a registry, identifies and qualifies an appropriate seller
on-the-fly, and negotiates the purchase dynamically? What if the seller looks
up a potentially different credit service every time, given a changing set of
criteria such a service might need to meet? Even more significant, what if the
seller’s inventory-management service dynamically selects its pick, pack, and
ship services at runtime, depending on supply chain issues such as
availability, price, and logistics?
Herein lies the power of Web Services. The architect must be able to
plan and structure processes where individual Web Services might be selected,
queried, and invoked dynamically at runtime. Therefore, the Process View is the
most important, and yet the least understood, of the architectural views of the
SOA.
JIT integration also complicates scalability and redundancy issues. Many
of these issues can be handled by the underlying software platform that
supports the Web Services. However, with JIT integration, it is not necessarily
possible to predict at design time which Web Services will be invoked or what
service implementations they will expose. How do you plan for scalability and
redundancy when you don’t even know whether a particular component will be
invoked at all?
Related Topics