Chapter: Advanced Computer Architecture : Multi-Core Architectures
SMT and CMP Architectures
SMT and CMP Architectures
Instruction-level parallelism(ILP)
Ø Wide-issue
Superscalar processors (SS)
Ø Four or
more instruction per cycle
Ø Executing
a single program or thread
Ø Attempts
to find multiple instructions to issue each cycle.
Ø Out-of-order
execution => instructions are sent to execution units based on instruction
dependencies rather than program order
Thread-level parallelism(TLP)
Ø Fine-grained
multithreaded superscalars(FGMS)
Ø Contain
hardware state for several threads
Ø Executing
multiple threads
Ø On any
given cycle a processor executes instructions from one of the
threads
Ø Multiprocessor(MP)
Ø Performance
improved by adding more CPUs
Simultaneous Multithreading
The idea
is issue multiple instructions from multiple threads each cycle
The
Features are
Ø Fully
exploit thread-level parallelism and instruction-level parallelism.
Ø Multiple
functional units
Ø Modern
processors have more functional units available then a single thread can
utilize.
Ø Register
renaming and dynamic scheduling
Ø Multiple instructions from
independent threads can co-exist and co-execute.
Superscalar processor with no multithreading:
Only one
thread is processed in one clock cycle
Ø Use of
issue slots is limited by a lack of ILP.
Ø Stalls
such as an instruction cache miss leaves the entire processor idle.
Fine grained Multithreading
Switches
threads on every clock cycle
Ø Pro: hide
latency of from both short and long stalls
Ø Con:
Slows down execution of the individual threads ready to go. Only one thread
issues inst. In a given clock cycle.
Course-grained multithreading:
Switches
threads only on costly stalls (e.g., L2
stalls)
Ø Pros: no
switching each clock cycle, no slow down for ready-to-go threads. Reduces no of
completely idle clock cycles.
Ø Con:
limitations in hiding shorter stalls
Simultaneous Multithreading:
Exploits
TLP at the same time it exploits ILP with multiple threads using the issue
slots in a single-clock cycle.
Ø issue
slots is limited by the following factors:
Ø Imbalances
in the resource needs.
Ø Resource
availability over multiple threads.
Ø Number of
active threads considered.
Ø Finite
limitations of buffer.
Ø Ability
to fetch enough instructions from multiple threads.
Ø Practical
limitations of what instructions combinations can issue from one thread and
multiple threads.
Performance Implications of SMT
Ø Single
thread performance is likely to go down (caches, branch predictors, registers,
etc. are shared) – this effect can be mitigated by trying to prioritize one
thread
Ø While
fetching instructions, thread priority can dramatically influence total
throughput – a widely accepted heuristic (ICOUNT): fetch such that each thread
has an equal share of processor resources
Ø With
eight threads in a processor with many resources, SMT yields throughput
improvements of roughly 2-4
Ø Alpha
21464 and Intel Pentium 4 are examples of SMT
Effectively Using Parallelism on a SMT Processor
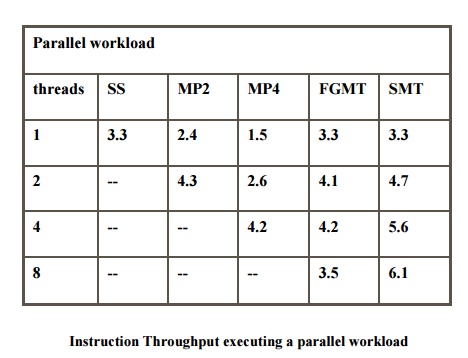
Instruction Throughput executing
a parallel workload
Comparison of SMT vs Superscalar
SMT
processors are compared to base superscalar processors in several key measures
:
![]()
Ø Utilization
of functional units.
Ø Utilization
of fetch units.
Ø Accuracy
of branch predictor.
Ø Hit rates
of primary caches.
Ø Hit rates
of secondary caches.
Performance improvement:
Ø Issue
slots.
Ø Funtional
units.
Ø Renaming
registers.
1. CMP Architecture
Ø Chip-level
multiprocessing(CMP or multicore): integrates two or more independent
cores(normally a CPU) into a single package composed of a single integrated
circuit(IC), called a die, or more dies packaged, each executing threads
independently.
Ø Every
funtional units of a processor is duplicated.
Ø Multiple
processors, each with a full set of architectural resources, reside on the same
die
Ø Processors
may share an on-chip cache or each can have its own cache
Ø Examples:
HP Mako, IBM Power4
Ø Challenges:
Power, Die area (cost)
Single core computer
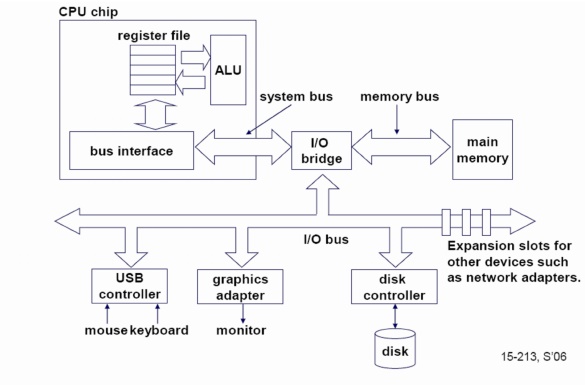
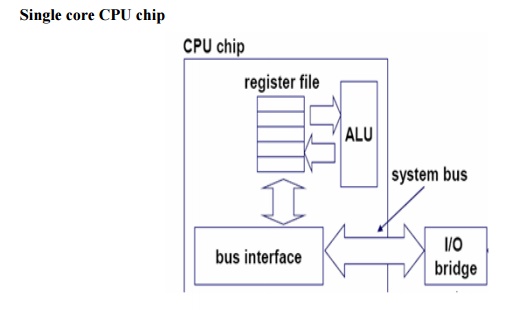
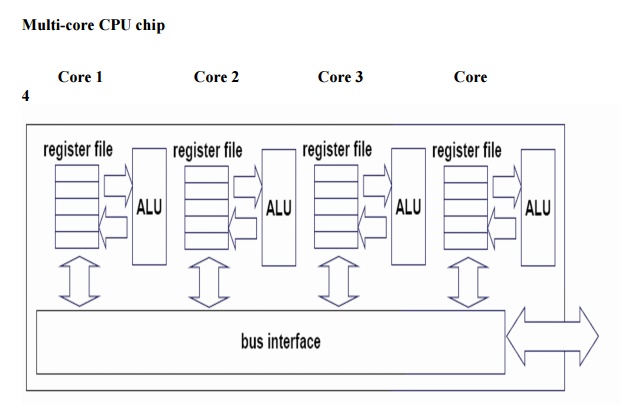
Chip Multithreading
Chip Multithreading = Chip Multiprocessing +
Hardware Multithreading.
Ø Chip
Multithreading is the capability of a processor to process multiple s/w threads
simulataneous h/w threads of execution.
Ø CMP is
achieved by multiple cores on a single chip or multiple threads on a single
core.
Ø CMP
processors are especially suited to server workloads, which generally have high
levels of Thread-Level Parallelism(TLP).
CMP’s Performance
Ø CMP’s are
now the only way to build high performance microprocessors , for a variety of
reasons:
Ø Large
uniprocessors are no longer scaling in performance, because it is only possible
to extract a limited amount of parallelism from a typical instruction stream.
Ø Cannot
simply ratchet up the clock speed on today’s processors,or the power
dissipation will become prohibitive.
Ø CMT
processors support many h/w strands through efficient sharing of on-chip
resources such as pipelines, caches and predictors.
Ø CMT
processors are a good match for server workloads,which have high levels of TLP
and relatively low levels of ILP.
SMT and CMP
Ø The
performance race between SMT and CMP is not yet decided.
Ø CMP is
easier to implement, but only SMT has the ability to hide latencies.
Ø A
functional partitioning is not exactly reached within a SMT processor due to
the centralized instruction issue.
Ø A
separation of the thread queues is a possible solution, although it does not
remove the central instruction issue.
Ø A
combination of simultaneous multithreading with the CMP may be superior.
Ø Research
: combine SMT or CMP organization with the ability to create threads with
compiler support of fully dynamically out of a single thread.
Ø Thread-level
speculation
Ø Close to
multiscalar
Related Topics