Chapter: Compilers : Principles, Techniques, & Tools : Introduction
Programming Language Basics
Programming Language Basics
1 The Static/Dynamic Distinction
2 Environments and States
3 Static Scope and Block Structure
4 Explicit Access Control
5 Dynamic Scope
6 Parameter Passing Mechanisms
7 Aliasing
8 Exercises
In this section, we shall cover the most important terminology and
distinctions that appear in the study of programming languages. It is not our
purpose to cover all concepts or all the popular programming languages. We
assume that the reader is familiar with at least one of C, C + + , C # , or
Java, and may have encountered other languages as well.
The Static/Dynamic Distinction
Among the most important issues that we face when designing a compiler
for a language is what decisions can the compiler make about a program. If a
language uses a policy that allows the compiler to decide an issue, then we say
that the language uses a static
policy or that the issue can be decided at compile
time. On the other hand, a policy
that only allows a decision to be made when
we execute the program is said to be a dynamic policy or to require a decision
at run time.
One issue on which we shall concentrate is the scope of declarations.
The scope of a declaration of x is the region of the program in which
uses of x refer to this declaration. A language uses static scope or lexical scope if it is possible to determine the scope of a
declaration by looking only at the program. Otherwise, the language uses dynamic scope. With dynamic scope, as
the program runs, the same use of x
could refer to any of several different declarations of x.
Most languages, such as C and Java, use static scope. We shall discuss static
scoping in Section 1.6.3.
E x a m p l e 1.3 : As another example of the
static/dynamic distinction, consider
the use of the term "static" as it applies to data in a Java
class declaration. In Java, a variable is a name for a location in memory used
to hold a data value. Here, "static" refers not to the scope of the
variable, but rather to the ability of the compiler to determine the location
in memory where the declared variable can be found. A declaration like
public
static int x;
makes x a class variable and says that there is only one copy of x, no matter how many objects of this
class are created. Moreover, the compiler can determine a location in memory
where this integer x will be held. In
contrast, had "static" been omitted from this declaration, then each
object of the class would have its own location where x would be held, and the compiler could not determine all these
places in advance of running the program. •
Environments and States
Another important distinction we must make when discussing programming
languages is whether changes occurring as the program runs affect the values of
data elements or affect the interpretation of names for that data. For example,
the execution of an assignment such as x
= y +1 changes the value denoted by the name x. More specifically, the assignment changes the value in whatever
location is denoted by x.
It may be less clear that the location denoted by x can change at run
time.
For instance, as we discussed in Example 1.3, if x is not a static (or
"class") variable, then every object of the class has its own
location for an instance of variable x. In that case, the assignment to x can
change any of those "instance" variables, depending on the object to
which a method containing that assignment is applied.
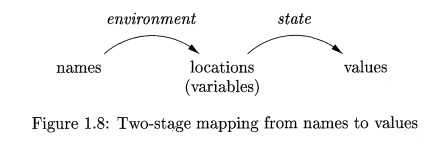
The association of names with locations in memory (the store) and then with values can be
described by two mappings that change as the program runs (see Fig. 1.8):
The environment is a mapping from names to locations in the store.
Since variables refer to locations ("1-values" in the terminology of
C), we could alternatively define an environment as a mapping from names to
variables.
The state is a mapping from locations in store to their values. That
is, the state maps 1-values to their corresponding r-values, in the terminology
of C.
Environments change according to the scope rules of a language.
E x a m p l e 1.4: Consider the C program fragment in Fig. 1.9. Integer i
is declared a global variable,
and also declared as a variable local to function /. When / is executing, the
environment adjusts so that name i
refers to the location reserved for the i
that is local to /, and any use of i,
such as the assignment i
= 3 shown explicitly, refers to that
location. Typically, the local i is
given a place on the run-time stack.
Whenever a function g other
than / is executing, uses of i cannot
refer to the i that is local to /.
Uses of name i in g must be within the scope of some other
declaration of i. An example is the
explicitly shown statement x = i+1, which is inside some procedure whose definition is not shown. The i in i
+ 1 presumably refers to the global i.
As in most languages, declarations in C must precede their use, so a function
that comes before the global i cannot
refer to it. •
The environment and state mappings in Fig. 1.8 are
dynamic, but there are a few exceptions:
1. Static versus dynamic binding of names
to locations. Most binding of
names to locations is dynamic, and we discuss
several approaches to this binding throughout the section. Some declarations,
such as the global i in Fig. 1.9, can be
given a location in the store once and for all, as the compiler generates
object code.2
Static versus dynamic binding of
locations to values. The binding of lo-cations to values (the second stage in
Fig. 1.8), is generally dynamic as well, since we cannot tell the value in a
location until we run the program. Declared constants are an exception. For
instance, the C definition
#define ARRAYSIZE 1000
Names, Identifiers, and Variables
Although the terms "name" and "variable," often
refer to the same thing, we use them carefully to distinguish between
compile-time names and the run-time locations denoted by names.
An identifier is a string of
characters, typically letters or digits, that refers to (identifies) an entity,
such as a data object, a procedure, a class, or a type. All identifiers are
names, but not all names are identifiers. Names can also be expressions. For
example, the name x.y might denote
the field y of a structure denoted by
x. Here, x and y are identifiers,
while x.y is a name, but not an
identifier. Composite names like x.y are
called qualified names.
A variable refers to a
particular location of the store. It is common for the same identifier to be
declared more than once; each such declaration introduces a new variable. Even
if each identifier is declared just once, an identifier local to a recursive
procedure will refer to different locations of the store at different times.
binds the name ARRAYS IZE to the value 1000 statically. We can determine this binding by
looking at the statement, and we know that it is impossible for this binding to
change when the program executes.
Static Scope and Block Structure
Most languages, including C and its family, use static scope. The scope
rules for C are based on program structure; the scope of a declaration is
determined implicitly by where the declaration appears in the program. Later
languages, such as C + + , Java, and C # , also provide explicit control over
scopes through the use of keywords like public,
private, and protected .
In this section we consider static-scope rules for a language with
blocks, where a block is a grouping
of declarations and statements. C uses braces { and } to delimit a block; the
alternative use of begin and end for the same purpose dates back to
Algol.
E x a m p l e 1.5 : To a first approximation, the C
static-scope policy is as follows:
A C program consists of a
sequence of top-level declarations of variables and functions.
Functions may have variable declarations within them, where variables
include local variables and parameters. The scope of each such declaration is
restricted to the function in which it appears.
Procedures, Functions, and
Methods
To avoid saying "procedures, functions, or methods," each time
we want to talk about a subprogram that may be called, we shall usually refer
to all of them as "procedures." The exception is that when talking
explicitly of programs in languages like C that have only functions, we shall
refer to them as "functions." Or, if we are discussing a language
like Java that has only methods, we shall use that term instead.
A function generally returns a value of some type (the "return
type"), while a procedure does not return any value. C and similar
languages, which have only functions, treat procedures as functions that have a
special return type "void," to signify no return value.
Object-oriented languages like Java and C + + use the term "methods."
These can behave like either functions or procedures, but are associated with a
particular class.
3. The scope of a top-level declaration of a name x consists of the entire program that follows, with the exception
of those statements that lie within a function that also has a declaration of x.
The additional detail regarding the C static-scope policy deals with
variable declarations within statements. We examine such declarations next and
in Example 1.6. •
In C, the syntax of blocks is given by
One type of statement is a block.
Blocks can appear anywhere that other types of statements, such as assignment
statements, can appear.
A block is a sequence of
declarations followed by a sequence of statements, all surrounded by braces.
Note that this syntax allows blocks to be nested inside each other. This
nesting property is referred to as block
structure. The C family of languages has block structure, except that a
function may not be defined inside another function.
We say that a declaration D
"belongs" to a block B if B is the most closely nested block
containing D; that is, D is located within B, but not within any block that is nested within B.
The static-scope rule for variable declarations in a block-structured
lan-guages is as follows. If declaration D
of name x belongs to block B, then the scope of D is all of B,
except for any blocks B' nested to any depth within J5, in which x is
redeclared. Here, x is redeclared in B' if some other declaration D' of the
same name x belongs to B'.
An equivalent way to express this rule is to focus on a use of a name x.
Let Bi, i?2, • • • , Bk be all the blocks that surround this use of x, with Bk
the smallest, nested within Bk-i, which is nested within Bk-2, and so on.
Search for the largest i such that there is a declaration of x belonging to B^.
This use of x refers to the declaration in B{. Alternatively, this use of x is
within the scope of the declaration in Bi.
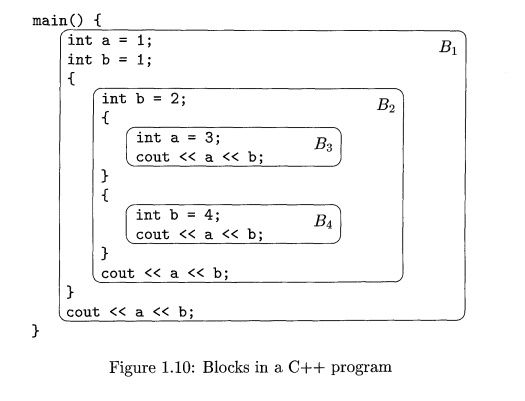
E x a m p l e 1.6: The C + + program in Fig. 1.10 has four blocks, with several definitions of variables a and b. As a memory aid, each declaration initializes its variable to
the number of the block to which it belongs.
For instance, consider the declaration i n t a = 1 in block Bi. Its
scope is all of Bi, except for those blocks nested (perhaps deeply) within B±
that have their own declaration of a. Z?2, nested immediately within B±, does
not have a declaration of a, but B3 does. B4 does not have a declaration of a,
so block B3 is the only place in the entire program that is outside the scope
of the declaration of the name a that belongs to B\. That is, this scope
includes B4 and all of Z?2 except for the part of B2 that is within B3. The
scopes of all five declarations are summarized in Fig. 1.11.
From another point of view, let us consider the output statement in
block B4 and bind the variables a and b used there to the proper declarations.
The list of surrounding blocks, in order of increasing size, is B4,B2,Bi. Note
that #3 does not surround the point in question. B4 has a declaration of b, so
it is to this declaration that this use of b refers, and the value of 6 printed
is 4. However, B4 does not have a declaration of o, so we next look at £?2-
That block does not have a declaration of a either, so we proceed to B\.
Fortunately, there is a declaration i n t a = 1 belonging to that block, so the
value of a printed is 1. Had there been no such declaration, the program would
have been erroneous.
Explicit Access Control
Classes and structures introduce a new scope for their members. If p is an object of a class with a field
(member) x, then the use of x in p.x
refers to field x in the class
definition. In analogy with block structure, the scope of a member declaration x in a class C extends to any subclass C,
except if C has a local declaration
of the same name x.
Through the use of keywords like public,
private, and protected,
object-oriented languages such as C + + or Java provide explicit control over
access to member names in a superclass. These keywords support encapsulation by restricting access.
Thus, private names are purposely given a scope that includes only the method
declarations and definitions associated with that class and any
"friend" classes (the C + + term). Protected names are accessible to
subclasses. Public names are accessible from outside the class.
In C + + , a class definition may be separated from the definitions of
some or all of its methods. Therefore, a name x associated with the class C
may have a region of the code that is outside its scope, followed by another
region (a method definition) that is within its scope. In fact, regions inside
and outside the scope may alternate, until all the methods have been defined.
Dynamic Scope
Technically, any scoping policy is dynamic if it is based on factor(s)
that can be known only when the program executes. The term dynamic scope, however, usually refers to the following policy: a
use of a name x refers to the
declaration of x in the most recently
called procedure with such a declaration. Dynamic scoping of this type appears
only in special situations. We shall consider two ex-amples of dynamic
policies: macro expansion in the C preprocessor and method resolution in
object-oriented programming.
Declarations and Definitions
The apparently similar terms "declaration" and
"definition" for programming-language concepts are actually quite
different. Declarations tell us about the types of things, while definitions
tell us about their values. Thus, i n t i is a declaration of i, while i = 1 is
a definition of i.
The difference is more significant when we deal with methods or other
procedures. In C + + , a method is declared in a class definition, by giving
the types of the arguments and result of the method (often called the signature
for the method. The method is then defined, i.e., the code for executing the
method is given, in another place. Similarly, it is common to define a C
function in one file and declare it in other files where the function is
used.
Example 1.7: In the C program of Fig. 1.12, identifier a is a macro that
stands for expression (a? + 1). But what is xl We cannot resolve x statically,
that is, in terms of the program text.
#define a (x+1)
i n t x = 2;
void b ( ) { i n t x = 1; p r i n
t f ("0 /.d\n", a ) ; }
void c() { printf (" , / .
d\n", a ) ; }
void mainO { b ( ) ; c ( ) ; }
Figure 1.12: A macro whose names must be scoped dynamically
In fact, in order to interpret x, we must use the usual dynamic-scope
rule.
We examine all the function calls that are currently active, and we take
the most recently called function that has a declaration of It is to this
declaration that the use of x refers.
In the example of Fig. 1.12, the function main first calls function 6.
As b executes, it prints the value of the macro a. Since (x + 1) must be
substituted for a, we resolve this use of x to the declaration i n t x=l in
function b. The reason is that b has a declaration of x, so the (x + 1) in the
p r i n t f in b refers to this x. Thus, the value printed is 1.
After b finishes, and c is called, we again need to print the value of
macro a. However, the only x accessible to c is the global x. The p r i n t f
statement in c thus refers to this declaration of x, and value 2 is printed.
Dynamic scope resolution is also essential for polymorphic procedures,
those that have two or more definitions for the same name, depending only on
the types of the arguments. In some languages, such as ML (see Section 7.3.3),
it is possible to determine statically types for all uses of names, in which
case the compiler can replace each use of a procedure name p by a reference to
the code for the proper procedure. However, in other languages, such as Java
and C + + , there are times when the compiler cannot make that determination.
Analogy Between Static and
Dynamic Scoping
While there could be any number of static or dynamic policies for
scoping, there is an interesting relationship between the normal
(block-structured) static scoping rule and the normal dynamic policy. In a
sense, the dynamic rule is to time as the static rule is to space. While the
static rule asks us to find the declaration whose unit (block) most closely
surrounds the physical location of the use, the dynamic rule asks us to find
the declaration whose unit (procedure invocation) most closely surrounds the
time of the use.
Example 1 . 8 : A distinguishing feature of object-oriented programming is the ability of each object to invoke the
appropriate method in response to a message. In other words, the procedure
called when x.mQ is executed depends
on the class of the object denoted by x
at that time. A typical example is as follows:
1. There is a class C with a
method named m() .
2. D is a subclass of C, and D has its own method named ra().
3. There is a use of m of the form x.mQ, where x is an
object of class C.
Normally, it is impossible to tell at compile time whether x will be of class C or of the subclass D. If
the method application occurs several times, it is highly likely that some will be on objects denoted by x that are in class C but not D, while others
will be in class D. It is not until
run-time that it can be decided which definition of m is the right one. Thus, the code generated by the compiler must
determine the class of the object x,
and call one or the other method named m. •
Parameter Passing Mechanisms
All programming languages have a notion of a procedure, but they can
differ in how these procedures get their arguments. In this section, we shall
consider how the actual parameters
(the parameters used in the call of a procedure) are associated with the formal parameters (those used in the
procedure defi-nition). Which mechanism is used determines how the
calling-sequence code treats parameters. The great majority of languages use
either "call-by-value," or "call-by-reference," or both. We
shall explain these terms, and another method known as
"call-by-name," that is primarily of historical interest.
Call - by - Value
In call-by-value, the actual
parameter is evaluated (if it is an expression) or copied (if it is a
variable). The value is placed in the location belonging to the corresponding
formal parameter of the called procedure. This method is used in C and Java,
and is a common option in C + + , as well as in most other languages.
Call-by-value has the effect that all computation involving the formal parameters
done by the called procedure is local to that procedure, and the actual
parameters themselves cannot be changed.
Note, however, that in C we can pass a pointer to a variable to allow
that variable to be changed by the callee. Likewise, array names passed as
param eters in C, C + + , or Java give
the called procedure what is in effect a pointer or reference to the array
itself. Thus, if a is the name of an array of the calling procedure, and it is
passed by value to corresponding formal parameter x, then an assignment such as x [ i ] = 2 really changes the array
element a[2]. The reason is that, although x
gets a copy of the value of a, that
value is really a pointer to the beginning of the area of the store where the
array named a is located.
Similarly, in Java, many variables are really references, or pointers,
to the things they stand for. This observation applies to arrays, strings, and
objects of all classes. Even though Java uses call-by-value exclusively,
whenever we pass the name of an object to a called procedure, the value
received by that procedure is in effect a pointer to the object. Thus, the
called procedure is able to affect the value of the object itself.
Call - by - Reference
In call-by-reference, the
address of the actual parameter is passed to the callee as the value of the
corresponding formal parameter. Uses of the formal parameter in the code of the
callee are implemented by following this pointer to the location indicated by
the caller. Changes to the formal parameter thus appear as changes to the
actual parameter.
If the actual parameter is an expression, however, then the expression
is evaluated before the call, and its value stored in a location of its own.
Changes to the formal parameter change this location, but can have no effect on
the data of the caller.
Call-by-reference is used for "ref" parameters in C + + and is
an option in many other languages. It is almost essential when the formal
parameter is a large object, array, or structure. The reason is that strict
call-by-value requires that the caller copy the entire actual parameter into
the space belonging to the corresponding formal parameter. This copying gets
expensive when the parameter is large. As we noted when discussing call-by-value,
languages such as Java solve the problem of passing arrays, strings, or other
objects by copying only a reference to those objects. The effect is that Java
behaves as if it used call-by-reference for anything other than a basic type
such as an integer or real.
Call - by - Name
A third mechanism — call-by-name — was used in the early programming
language Algol 60. It requires that
the callee execute as if the actual parameter were substituted literally for
the formal parameter in the code of the callee, as if the formal parameter were
a macro standing for the actual parameter (with renaming of local names in the
called procedure, to keep them distinct). When the actual parameter is an
expression rather than a variable, some unintuitive behaviors occur, which is
one reason this mechanism is not favored today.
Aliasing
There is an interesting consequence of call-by-reference parameter
passing or its simulation, as in Java, where references to objects are passed
by value. It is possible that two formal parameters can refer to the same
location; such variables are said to be aliases
of one another. As a result, any two variables, which may appear to take their
values from two distinct formal parameters, can become aliases of each other,
as well.
Example 1. 9 : Suppose a is an
array belonging to a procedure p, and p calls another procedure
q(x,y) with a call
q(a,a). Suppose also
that parameters are passed by value, but that array names are really
references to the location where the array is stored, as in C or similar
languages. Now, x and y have become aliases of each other. The important point is that if within q there
is an assignment x[10] = 2, then the
value of y[10] also becomes 2.
It turns out that understanding aliasing and the mechanisms that create
it is essential if a compiler is to optimize a program. As we shall see
starting in Chapter 9, there are
many situations where we can only optimize code if we can be sure certain variables
are not aliased. For instance, we might determine that x = 2 is the only place that variable x is ever assigned. If so, then we can replace a use of x by a use of 2; for example, replace a =
x+3 by the simpler a = 5. But
suppose there were another variable y
that was aliased to x.
Then an assignment y = 4 might have the unexpected effect
of changing x. It might also mean
that replacing a = x+3 by a = 5 was a mistake; the proper value
of could be 7 there.
Exercises for Section 1.6
Exercise 1 . 6 . 1 : For the block-structured C code of Fig. 1.13(a), indicate the values
assigned to w, x, y, and z.
Exercise 1 . 6 . 2: Repeat
Exercise 1.6.1 for the code of Fig. 1.13(b).
Exercise 1 . 6 . 3 : For the block-structured code of Fig. 1.14, assuming the usual static
scoping of declarations, give the scope for each of the twelve declarations.
Summary of Chapter 1
Language Processors. An
integrated software development environment
includes many different kinds of language processors such as compilers, interpreters,
assemblers, linkers, loaders, debuggers, profilers.
Compiler Phases. A compiler operates as a sequence of phases, each of which transforms the source program from one intermediate
representa-tion to another.
4> Machine and Assembly Languages.
Machine languages were the first-generation programming languages, followed by
assembly languages. Pro - gramming in these languages was time consuming and
error prone.
Modeling in Compiler Design. Compiler
design is one of the places where theory
has had the most impact on practice. Models that have been found useful include
automata, grammars, regular expressions, trees, and many others.
4 Code Optimization. Although
code cannot truly be "optimized," the sci-ence of improving the
efficiency of code is both complex and very impor-tant. It is a major portion
of the study of compilation.
4 Higher-Level Languages. As
time goes on, programming languages take on progressively more of the tasks
that formerly were left to the program-mer, such as memory management,
type-consistency checking, or parallel execution of code.
4 Compilers and Computer Architecture. Compiler technology influences
computer architecture, as well as being influenced by the advances in
architecture. Many modern innovations in architecture depend on compilers being
able to extract from source programs the opportunities to use the hardware
capabilities effectively.
4 Software Productivity and Software Security. The same technology that
allows compilers to optimize code can be used for a variety of program-analysis
tasks, ranging from detecting common program bugs to discovering that a program
is vulnerable to one of the many kinds of intrusions that "hackers"
have discovered.
4 Scope Rules. The scope of a declaration of x is the context in which
uses of x refer to this declaration. A language uses static scope or lexical
scope if it is possible to determine the scope of a declaration by looking only
at the program. Otherwise, the language uses dynamic scope.
Environments. The association of
names with locations in memory and then with values can be described in terms
of environments, which map names to locations in store, and states, which map
locations to their values.
4 Block Structure. Languages that allow blocks to be nested are said to
have block structure. A name a: in a nested block B is in the scope of a
declaration D of x in an enclosing block if there is no other declaration of x
in an intervening block.
4 Parameter Passing. Parameters are passed from a calling procedure to
the callee either by value or by reference. When large objects are passed by
value, the values passed are really references to the objects themselves,
resulting in an effective call-by-reference.
Aliasing. When parameters are
(effectively) passed by reference, two for-mal parameters can refer to the same
object. This possibility allows a change in one variable to change another.
Related Topics