Chapter: Fundamentals of Database Systems : Database Design Theory and Normalization : Basics of Functional Dependencies and Normalization for Relational Databases
Informal Design Guidelines for Relation Schemas
Informal Design Guidelines for Relation Schemas
Before discussing the formal theory of relational database design, we
discuss four informal guidelines that
may be used as measures to determine the
quality of relation schema
design:
Making sure that the semantics of
the attributes is clear in the schema
Reducing the redundant
information in tuples
Reducing the NULL values in tuples
Disallowing the possibility of generating
spurious tuples
These measures are not always independent of one another, as we will
see.
1. Imparting Clear
Semantics to Attributes in Relations
Whenever we group attributes to form a relation schema, we assume that
attributes belonging to one relation have certain real-world meaning and a
proper interpretation associated with them. The semantics of a relation refers to its meaning result-ing from the
interpretation of attribute values in a tuple. In Chapter 3 we discussed how a
relation can be interpreted as a set of facts. If the conceptual design
described in Chapters 7 and 8 is done carefully and the mapping procedure in
Chapter 9 is fol-lowed systematically, the relational schema design should have
a clear meaning.
In general, the easier it is to explain the semantics of the relation,
the better the relation schema design will be. To illustrate this, consider
Figure 15.1, a simplified version of the COMPANY
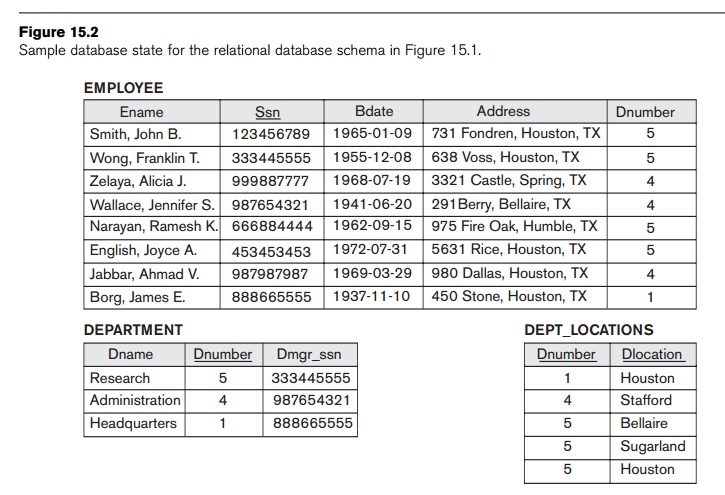
relational database schema in Figure 3.5, and Figure 15.2, which presents an
example of populated relation states of this schema. The meaning of the EMPLOYEE relation schema is quite simple: Each tuple represents an employee,
with values for the employee’s name (Ename), Social
Security number (Ssn), birth date (Bdate), and address (Address), and the number of the department that the employee works for (Dnumber). The Dnumber attribute is a foreign key that represents an implicit relationship between EMPLOYEE and DEPARTMENT. The semantics of the DEPARTMENT and PROJECT schemas are also straightforward: Each DEPARTMENT tuple
represents a department entity, and each PROJECT tuple
represents a project entity. The attribute Dmgr_ssn of DEPARTMENT relates a department to the employee who is its manager, while Dnum of PROJECT relates a project to its controlling department; both are foreign key
attributes. The ease with which the meaning of a relation’s attributes can be
explained is an informal measure of
how well the relation is designed.
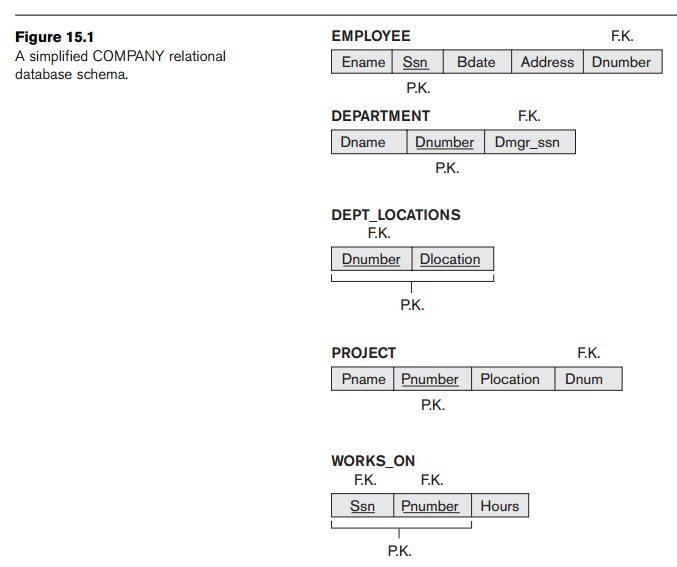
The semantics of the other two relation schemas in Figure 15.1 are
slightly more complex. Each tuple in DEPT_LOCATIONS gives a
department number (Dnumber) and one of the locations of the department (Dlocation). Each tuple in WORKS_ON gives an employee Social
Security number (Ssn), the project number of one of
the projects that the employee works on (Pnumber), and
the number of hours per week that the employee works on that project (Hours). However, both schemas have a well-defined and unambiguous
interpretation. The schema DEPT_LOCATIONS rep-resents a multivalued
attribute of DEPARTMENT, whereas WORKS_ON represents an M:N relationship between EMPLOYEE and PROJECT. Hence, all the relation schemas in Figure 15.1 may be considered as
easy to explain and therefore good from the standpoint of having clear
semantics. We can thus formulate the following informal design guideline.
Guideline 1
Design a relation schema so that it is easy to explain its meaning. Do
not combine attributes from multiple entity types and relationship types into a
single relation. Intuitively, if a relation schema corresponds to one entity
type or one relationship type, it is straightforward to interpret and to
explain its meaning. Otherwise, if the relation corresponds to a mixture of
multiple entities and relationships, semantic ambiguities will result and the
relation cannot be easily explained.
Examples of Violating
Guideline 1. The relation schemas in Figures
15.3(a) and
15.3(b) also have clear semantics. (The reader
should ignore the lines under the relations for now; they are used to
illustrate functional dependency notation, dis-cussed in Section 15.2.) A tuple
in the EMP_DEPT relation schema in Figure 15.3(a) represents a single employee but
includes additional information—namely, the name (Dname) of the department for which the employee works and the Social Security
number (Dmgr_ssn) of the department manager. For the EMP_PROJ
rela-tion in Figure 15.3(b), each tuple relates an employee to a project but
also includes
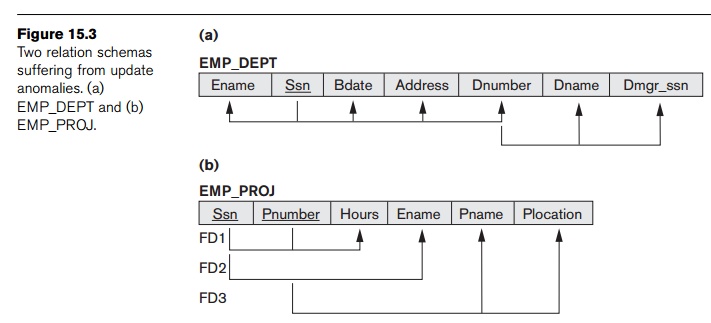
the employee name (Ename), project name (Pname), and project location (Plocation).
Although there is nothing wrong logically with these two relations, they
violate Guideline 1 by mixing attributes from distinct real-world entities: EMP_DEPT mixes attributes of employees and departments, and EMP_PROJ mixes attributes of employees and projects and the WORKS_ON relationship. Hence, they fare poorly against the above measure of
design quality. They may be used as views, but they cause problems when used as
base relations, as we discuss in the following section.
2. Redundant Information in Tuples and Update Anomalies
One goal of schema design is to minimize the storage space used by the
base rela-tions (and hence the corresponding files). Grouping attributes into
relation schemas has a significant effect on storage space. For example,
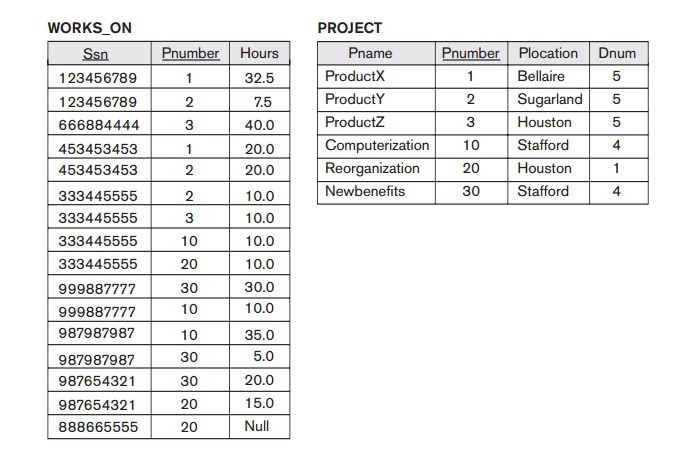
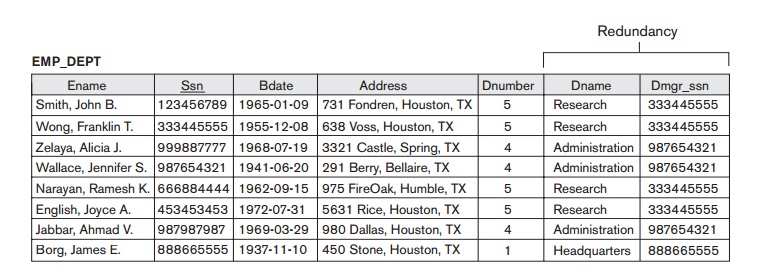
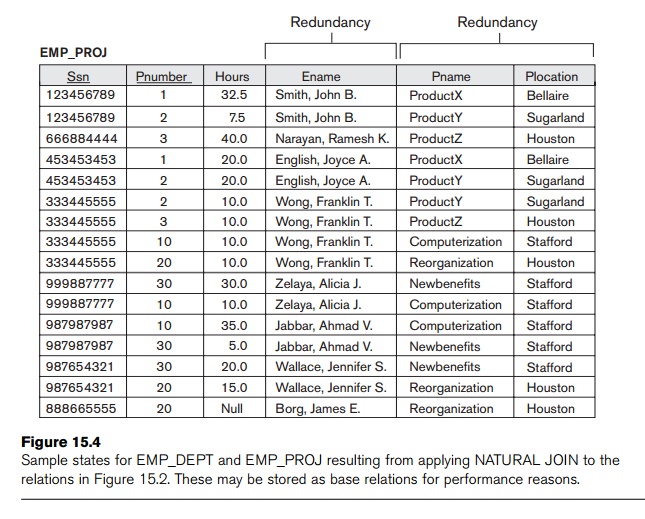
compare the space used by the two base relations EMPLOYEE and DEPARTMENT in Figure 15.2 with that for an EMP_DEPT base
relation in Figure 15.4, which is the result of applying the NATURAL JOIN operation to EMPLOYEE and DEPARTMENT. In EMP_DEPT, the attribute values pertaining to a particular department (Dnumber, Dname, Dmgr_ssn) are repeated for every employee
who works for that department. In contrast, each department’s information
appears only once in the DEPARTMENT relation in Figure 15.2. Only
the department number (Dnumber) is repeated in the EMPLOYEE relation for each employee who works in that department as a foreign
key. Similar com-ments apply to the EMP_PROJ relation
(see Figure 15.4), which augments the WORKS_ON relation
with additional attributes from EMPLOYEE and PROJECT.
Storing natural joins of base relations leads to an additional problem referred to as update anomalies. These can be classified into insertion anomalies, deletion anomalies, and modification anomalies.
Insertion Anomalies. Insertion anomalies can be differentiated into two types, illustrated by the following examples based on the EMP_DEPT relation:
To insert a new employee tuple
into EMP_DEPT, we must include either the attribute values for the department that
the employee works for, or NULLs (if the employee does not work
for a department as yet). For example, to insert a new tuple for an employee
who works in department number 5, we must enter all the attribute values of
department 5 correctly so that they are
consistent with the corresponding values for department 5 in other tuples in EMP_DEPT. In the
design of Figure 15.2, we do not have to worry about this consistency problem because we enter only the department number in the
employee tuple; all other attribute values of department 5 are recorded only
once in the database, as a single tuple in the DEPARTMENT
relation.
It is difficult to insert a new department that has no employees as yet
in the EMP_DEPT
relation. The only way to do this is to place NULL values in the
attributes for employee. This violates the entity integrity for EMP_DEPT because Ssn is its primary key. Moreover, when the first employee is assigned to
that department, we do not need this tuple with NULL values
any more. This problem does not occur in the design of Figure 15.2 because a
department is entered in the DEPARTMENT relation whether or not any
employees work for it, and whenever an employee is assigned to that department,
a cor-responding tuple is inserted in EMPLOYEE.
Deletion Anomalies. The problem of deletion anomalies is related to the second insertion anomaly situation just discussed. If we delete from EMP_DEPT an employee tuple that happens to represent the last employee working
for a particular department, the information concerning that department is lost
from the database. This problem does not occur in the database of Figure 15.2
because DEPARTMENT tuples are stored separately.
Modification Anomalies. In
EMP_DEPT, if we change the value of one of the attributes
of a particular department—say, the manager of department 5—we must update the
tuples of all employees who work in
that department; otherwise, the database will become inconsistent. If we fail
to update some tuples, the same depart-ment will be shown to have two different
values for manager in different employee tuples, which would be wrong.
It is easy to see that these three anomalies are undesirable and cause
difficulties to maintain consistency of data as well as require unnecessary
updates that can be avoided; hence, we can state the next guideline as follows.
Guideline 2
Design the base relation schemas so that no insertion, deletion, or
modification anomalies are present in the relations. If any anomalies are
present, note them clearly and make sure that the programs that update the
database will operate correctly.
The second guideline is consistent with and, in a way, a restatement of
the first guideline. We can also see the need for a more formal approach to
evaluating whether a design meets these guidelines. Sections 15.2 through 15.4
provide these needed formal concepts. It is important to note that these
guidelines may some-times have to be
violated in order to improve the
performance of certain queries. If EMP_DEPT is used
as a stored relation (known otherwise as a materialized view) in addition to the base relations of EMPLOYEE and DEPARTMENT, the anomalies in EMP_DEPT must be noted and accounted for
(for example, by using triggers or stored
procedures that would make automatic updates). This way, whenever the base
relation is updated, we do not end up with inconsistencies. In general, it is
advisable to use anomaly-free base relations and to specify views that include
the joins for placing together the attributes frequently referenced in
important queries.
3. NULL Values in
Tuples
In some schema designs we may group many attributes together into a
“fat” relation. If many of the attributes do not apply to all tuples in the
relation, we end up with many NULLs in those tuples. This can waste
space at the storage level and may also lead to problems with understanding the
meaning of the attributes and with specifying JOIN operations
at the logical level. Another problem with NULLs is how to account for them when
aggregate operations such as COUNT or SUM are applied. SELECT and JOIN operations
involve comparisons; if NULL values are present, the results may become unpredictable. Moreover, NULLs can have multiple interpretations, such as the following:
The attribute does not apply to this tuple. For
example, Visa_status may not apply to U.S. students.
The attribute value for this
tuple is unknown. For example, the Date_of_birth may be unknown for an employee.
The value is known but absent; that is, it has not been recorded yet. For
example, the Home_Phone_Number for an employee may exist, but may not be available and recorded yet.
Having the same representation for all NULLs
compromises the different meanings they may have. Therefore, we may state
another guideline.
Guideline 3
As far as possible, avoid placing attributes in a base relation whose
values may frequently be NULL. If NULLs are unavoidable, make sure that they apply in exceptional cases only
and do not apply to a majority of tuples in the relation.
Using space efficiently and avoiding joins with NULL values are the two overriding criteria that determine whether to
include the columns that may have NULLs in a relation
or to have a separate relation for those columns (with the appropriate key
columns). For example, if only 15 percent of employees have individual offices,
there is little justification for including an attribute Office_number in the EMPLOYEE relation; rather, a relation EMP_OFFICES(Essn, Office_number) can be created to include tuples for only the employees with
individual offices.
4. Generation of
Spurious Tuples
Consider the two relation schemas EMP_LOCS and EMP_PROJ1 in Figure 15.5(a), which can be used instead of the single EMP_PROJ relation in Figure 15.3(b). A tuple in EMP_LOCS means
that the employee whose name is Ename works on
some project whose location is Plocation. A tuple in EMP_PROJ1 refers to the fact that the employee
whose Social Security number is Ssn works Hours per week on the project whose name, number, and location are Pname, Pnumber, and Plocation. Figure 15.5(b) shows relation states of EMP_LOCS and EMP_PROJ1 corresponding to the


EMP_PROJ relation in Figure 15.4, which are obtained by applying the appropriate PROJECT (π) operations to EMP_PROJ (ignore the dashed lines in
Figure 15.5(b)
for now).
Suppose that we used EMP_PROJ1 and EMP_LOCS as the base relations instead of EMP_PROJ. This produces a particularly bad schema design because we cannot recover the information that was originally in EMP_PROJ from EMP_PROJ1 and EMP_LOCS. If we attempt a NATURAL JOIN operation on EMP_PROJ1 and EMP_LOCS, the result produces many more tuples than the original set of tuples in EMP_PROJ. In Figure 15.6, the result of applying the join to only the tuples above the dashed lines in Figure 15.5(b) is shown (to reduce the size of the resulting rela ion). Additional tuples that were not in are called spurious tuples
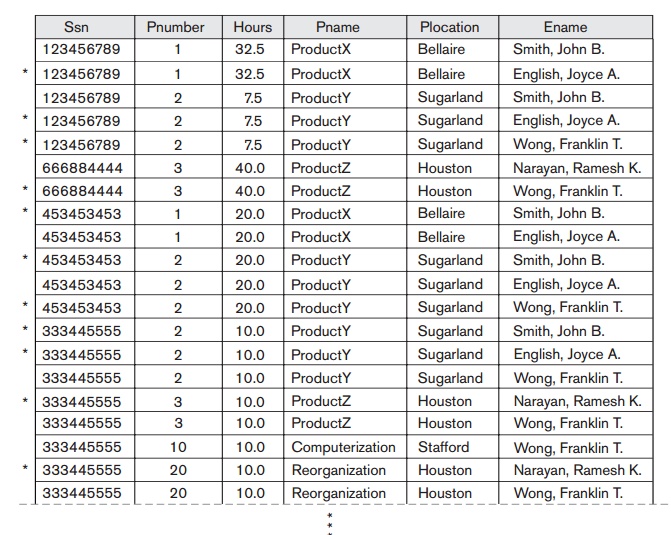

because they represent spurious information that is not valid. The
spurious tuples are marked by asterisks (*) in Figure 15.6.
Decomposing EMP_PROJ into EMP_LOCS and EMP_PROJ1 is undesirable because when we JOIN them
back using NATURAL
JOIN, we do not get the correct original information.
This is because in this case Plocation is the attribute that relates EMP_LOCS and
EMP_PROJ1, and Plocation is neither a primary key nor a foreign key in
either EMP_LOCS or EMP_PROJ1. We can now informally state another design guideline.
Guideline 4
Design relation schemas so that they can be joined with equality
conditions on attributes that are appropriately related (primary key, foreign
key) pairs in a way that guarantees that no spurious tuples are generated.
Avoid relations that contain matching attributes that are not (foreign key,
primary key) combinations because joining on such attributes may produce
spurious tuples.
This informal guideline obviously needs to be stated more formally. In
Section 16.2 we discuss a formal condition called the nonadditive (or lossless)
join property that guarantees that certain joins do not produce spurious
tuples.
5. Summary and
Discussion of Design Guidelines
In Sections 15.1.1 through 15.1.4, we informally discussed situations
that lead to problematic relation schemas and we proposed informal guidelines
for a good relational design. The problems we pointed out, which can be
detected without additional tools of analysis, are as follows:
Anomalies that cause redundant
work to be done during insertion into and modification of a relation, and that
may cause accidental loss of information during a deletion from a relation
Waste of storage space due to NULLs and the difficulty of performing selections, aggregation operations,
and joins due to NULL values
Generation of invalid and
spurious data during joins on base relations with matched attributes that may
not represent a proper (foreign key, primary key) relationship
In the rest of this chapter we present formal concepts and theory that
may be used to define the goodness
and badness of individual relation schemas more precisely. First we discuss
functional dependency as a tool for analysis. Then we specify the three normal
forms and Boyce-Codd normal form (BCNF) for relation schemas. The strategy for
achieving a good design is to decompose a badly designed relation
appropriately. We also briefly introduce additional normal forms that deal with
additional dependencies. In Chapter 16, we discuss the properties of
decomposition in detail, and provide algorithms that design relations bottom-up
by using the functional dependencies as a starting point.
Related Topics