Chapter: Embedded and Real Time Systems : Case Study
Data Compressor- Embedded and Real Time Systems
DATA
COMPRESSOR:
1.
Requirements and Algorithm
We use the Huffman coding
technique, We require some understanding of how our compression code fits into
a larger system. Figure 3.20 shows a collaboration diagram for the data
compression process.
The data compressor takes in a sequence of input symbols and then produces a stream of output symbols. Assume
for simplicity that the input symbols are one byte in length.The output symbols are variable length,sowe have
to choose a format in which to deliver the output data.
Delivering each coded symbol separately is tedious, since we would have
to supply the length of each symbol and use external code to pack them into
words.
On the other hand, bit-by-bit delivery is almost certainly too slow.
Therefore, we will rely on the data compressor to pack the coded symbols into
an array. There is not a one-to-one relationship between the input and output
symbols, and we may have to wait for several input symbols before a packed
output word comes out.
The data compressor as discussed above is not a
complete system, but we can create at least a partial requirements list for the
module as seen below. We used the abbreviation N/A for not applicable to
describe some items that do not make sense for a code module.
2.
Specification
Let’s refine the description of Figure 3.20 to come up with a more
complete specification for our data compression module. That collaboration
diagram concentrates on the steady-state behavior of the system.
For a fully functional system, we have to provide the following
additional behavior.
We have to be able to provide the compressor with a
new symbol table.
We should be able to flush the symbol buffer to
cause the system to release all pending symbols that have been partially
packed. We may want to do this when we change the symbol table or in the middle
of an encoding session to keep a transmitter busy.
A class description for this refined understanding of the requirements
on the module is shown in Figure 5.5. The class’s buffer and current-bit
behaviors keep track of the state of the encoding, and the table attribute provides the current symbol table.
The class has three methods as follows:
Encode performs the basic encoding
function. It takes in a 1-byte input symbol and returns two values: a
boolean showing whether it is returning a full buffer and, if the boolean is
true, the full buffer itself.
New-symbol-table installs
a new symbol table into the object and throws away the current contents of the
internal buffer.
Flush returns the current state of the buffer, including the number of valid bits in the buffer
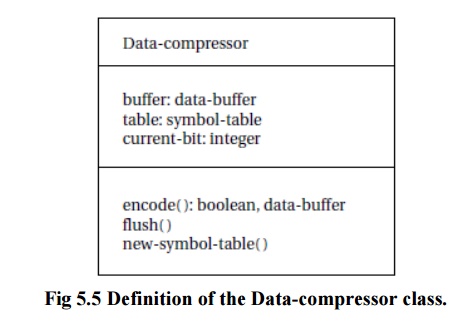 .
.
We also need to define classes for the data buffer and the symbol table.
These classes are shown in Figure 5.6.
The data-buffer will be used to hold both packed symbols and unpacked ones (such as in the symbol table). It defines the buffer itself and the length of the buffer. We have to define a data type because the longest encoded symbol is longer than an input symbol.
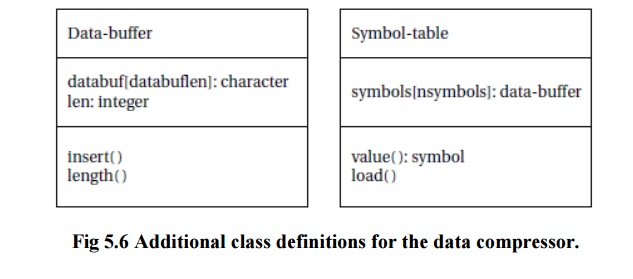
The longest Huffman code for an eight-bit input symbol is 256 bits.
(Ending up with a symbol this long happens only when the symbol probabilities
have the proper values.)
The insert function packs a new symbol into the upper bits of the
buffer; it also puts the remaining bits in a new buffer if the current buffer
is overflowed.
The Symbol-table class indexes
the encoded version of each symbol. The class defines an access behavior for
the table; it also defines a load
behavior to create a new symbol table.
The relationships between these classes are shown
in Figure 5.7 a data compressor object includes one buffer and one symbol
table.
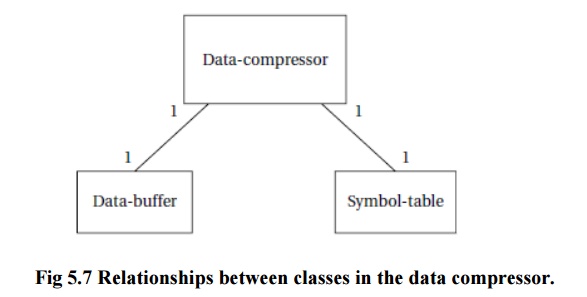
Figure 5.8 shows a state diagram for the encode behavior. It shows that most of the effort goes into filling the buffers with variable-length symbols.
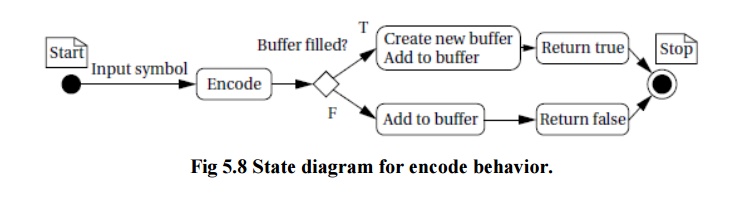
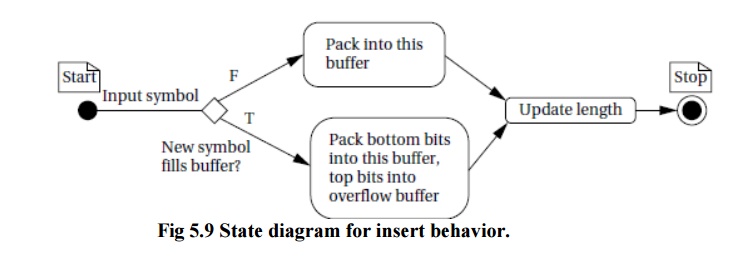
Figure 5.9 shows a state diagram for insert. It shows that we must consider
two cases—the new symbol does not fill the current buffer or it does.
Related Topics