Chapter: Embedded and Real Time Systems : Hardware Accelerates & Networks
Accelerated System Design
ACCELERATED
SYSTEM DESIGN:
The
complete architectural design of the accelerated system depends on the
application being implemented. However, it is helpful to think of an architectural
framework into which our accelerator fits. Because the same basic
techniques for connecting the CPU and accelerator can be applied to many
different problems, understanding the framework helps us quickly identify what
is unique about our application.
An
accelerator can be considered from two angles: its core functionality and its
interface to the CPU bus. We often start with the accelerator’s basic
functionality and work our way out to the bus interface, but in some cases the
bus interface and the internal logic are closely intertwined in order to
provide high-performance data access.
The
accelerator core typically operates off internal registers. Howmany registers are
required is an important design decision. Main memory accesses will probably
take multiple clock cycles, slowing down the accelerator. If the algorithm to
be accelerated can predict which data values it will use, the data can be
prefetched from main memory and stored in internal registers.
The
accelerator will almost certainly use registers for basic control. Status
registers like those of
I/O
devices are a good way for the CPU to test the accelerator’s state and to
perform basic operations such as starting, stopping, and resetting the
accelerator.
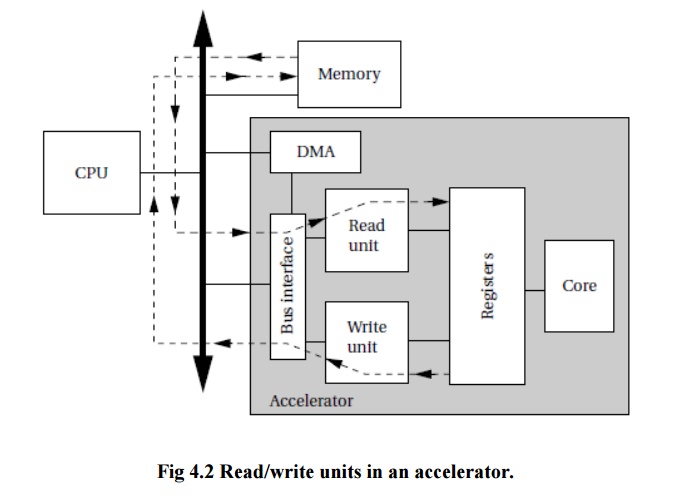
Large-volume
data transfers may be performed by special-purpose read/write logic. Figure 4.2
illustrates an accelerator with read/write units that can supply higher volumes
of data without CPU intervention. A register file in the accelerator acts as a
buffer between main memory and the accelerator core.
The read
unit can read ahead of the accelerator’s requirements and load the registers
with the next required data; similarly, the write unit can send recently
completed values to main memory while the core works with other values.
In order
to avoid tying up the CPU, the data transfers can be performed in DMA mode,
which means that the accelerator must have the required logic to become a bus
master and perform DMA operations.
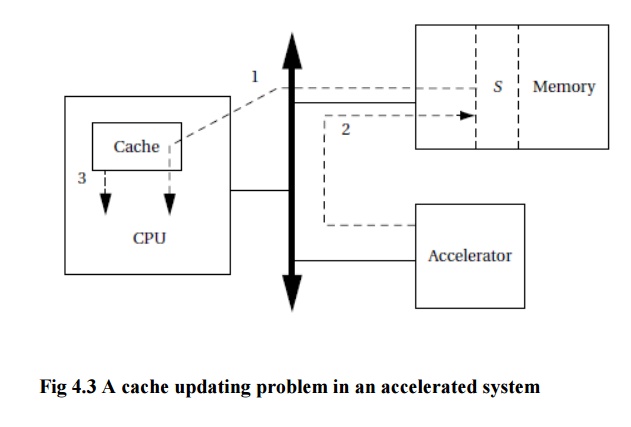
The CPU cache can cause problems for accelerators. Consider the following sequence of operations as illustrated in Figure 4.3:
·
The CPU
reads location S.
·
The accelerator
writes S.
·
The CPU
again reads S.
If the CPU has cached location S,the program will not see the value of S written by the accelerator. It will instead get the old value of S stored in the cache.To avoid this problem, the CPU’s cache must be updated to
reflect the fact that this cache entry is invalid. Your CPU may provide cache
invalidation instructions; you can also remove the location from the cache by
reading another location that is mapped to the same cache line
Some CPUs
are designed to support multiprocessing. The bus interface of such machines
provides mechanisms for other processors to tell the CPU of required cache
changes. This mechanism can be used by the accelerator to update the cache.
If the
CPU and accelerator operate concurrently and communicate via shared memory, it
is possible that similar problems will occur in main memory, not just in the
cache. If one PE reads a value and then updates it, the other PE may change the
value, causing the first PE’s update to be invalid. In some cases, it may be
possible to use a very simple synchronization scheme for communication.
The CPU
writes data into a memory buffer, starts the accelerator, waits for the
accelerator to finish, and then reads the shared memory area. This amounts to
using the accelerator’s status registers as a simple semaphore system.
If the
CPU and accelerator both want access to the same block of memory at the same
time, then the accelerator will need to implement a test-and-set operation in
order to implement semaphores. Many CPU buses implement test-and-set atomic
operations that the accelerator can use for the semaphore operation.
Related Topics