Chapter: Advanced Computer Architecture : Multi-Core Architectures
Design Issues: Design Challenges of SMT
DESIGN
ISSUES:
SMT and CMP Architectures
They
determine the performance measures of each processor in a precise manner. The
issue slots usage limitations and its issues also determine the performance.Why
Multithreading Today ILP is exhausted, TLP is in. Large performance gap between
MEMORY and PROCESSOR. Too many transistors on chip. More existing MT
applications today. Multiprocessors on a single chip. Long network latency, too
1. DESIGN CHALLENGES OF SMT
Impact of fine grained scheduling on single thread
performance?
A
preferred thread approach sacrifices throughput and single threaded
performance. Unfortunately with a preferred thread, the processor is likely to
sacrifice some throughput
Reason for loss of throughput
Pipeline
is less likely to have a mix of instructions from several threads resulting in
a greater probability that either empty slots or a stall will occur
Design Challenges
Larger
register file needed to hold multiple contexts.Not affecting clock cycle time,
especially in
Ø Instruction
issue- more candidate instructions need to be considered
Ø Instruction
completion- choosing which instructions to commit may be challenging
Ensuring
that cache and TLP conflicts generated by SMT do not degrade performance. There
are mainly two observations
Ø Potential
performance overhead due to multithreading is small
Ø Efficiency
of current superscalar is low with the room for significant improvement
A SMT
processor works well if Number of compute intensive threads does not exceed the
number of threads supported in SMT. Threads have highly different
charecteristics For eg; 1 thread doing mostly integer operations and another
doing mostly floating point operations
It does
not work well if Threads try to utilize the same functional units and for
assignment problems
Ø Eg; a
dual core processor system, each processor having 2 threads simultaneously
Ø 2
computer intensive application processes might end up on the same processor
instead of different processors
The
problem here is the operating system does not see the difference between the
SMT and real processors !!!
Transient Faults
Faults
that persist for a “short” duration. Cause is cosmic rays (e.g., neutrons).The
effect is knock off electrons, discharge capacitor.The Solution is no practical
absorbent for cosmic rays.1 fault per 1000 computers per year (estimated fault
rate)
Processor Utilization vs. Latency
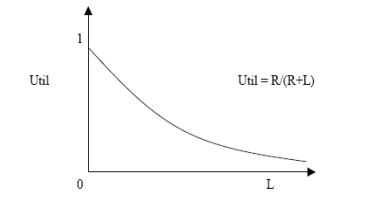
R = the run length to a long
latency event
L = the amount of latency
Simultaneous & Redundantly Threaded Processor
(SRT)
SRT = SMT
+ Fault Detection + Less hardware compared to replicated microprocessors SMT
needs ~5% more hardware over uniprocessor SRT adds very little hardware
overhead to existing SMT+ Better performance than complete replication better
use of resources + Lower cost avoids complete replication
SRT Design Challenges
Lock
stepping doesn’t work because SMT may issue same instruction from redundant
threads in different cycles. Must carefully fetch/schedule instructions from
redundant threads since branch misprediction &cache miss will occur
Transient Fault Detection in CMPs
CRT
borrows the detection scheme from the SMT-based simultaneously and Redundantly
Threaded (SRT) processors and applies the scheme to CMPs.
replicated two communicating threads (leading
& trailing threads)
Compare
the results of the two.
CRT
executes the leading and trailing threads on different processors to achieve
load balancing and to reduce the probability of a fault corrupting both threads
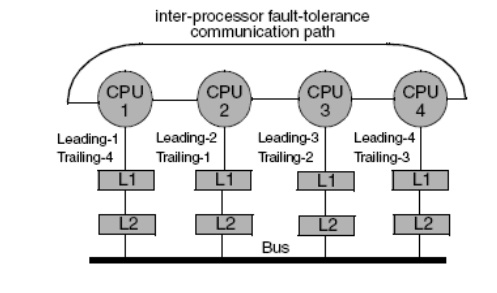
Detection
is based on replication but to which extent?.Itreplicates register values (in
register file in each core) but not memory values. The CRT’s leading thread
commits stores only
after
checking, so that memory is guaranteed to be correct.CRT compares only stores
and uncached loads, but not register values, of the two threads.
An
incorrect value caused by a fault propagates through computations and is
eventually consumed by a store, checking only stores suffices for detection;
other instructions commit without checking.
CRT uses
a store buffer (StB) in which the leading thread places its committed store
values and addresses. The store values and addresses of the trailing thread are
compared against the StB entries to determine whether a fault has occurred.
(one checked store reaches to the cache hierarchy)
Transient Fault Recovery for CMPs
Unlike
CRT, CRTR must not allow any trailing instruction to commit before it is
checked for faults, so that the register state of the trailing thread may be
used for recovery. However, the leading thread in CRTR may commit register state
before checking, as in CRT.
This
asymmetric commit strategy allows CRTR to employ a long slack to absorb
inter-processor latencies. As in CRT, CRTR commits stores only after checking.
In addition to communicating branch outcomes, load addresses, load values,
store addresses, and store values like CRT, CRTR also communicates register
values.
Challenges with this approach
Ø I-Cache:
Ø Instruction
bandwidth
Ø I-Cache
misses:
Since instructions are being grabbed from many
different contexts, instruction locality is degraded and the I-cache miss rate
rises.
Ø Register
file access time:
Ø Register
file access time increases due to the fact that the regfile had to
significantly increase in size to accommodate many separate contexts.
Ø In fact,
the HEP and Tera use SRAM to implement the regfile, which means longer access
times.
Ø Single
thread performance
Ø Single thread
performance significantly degraded
since the context
is
forced to switch
to a new thread even if none are available.
Ø Very high
bandwidth network, which is fast and wide
Ø Retries
on load empty or store full
To
maximize SMT performance Issue slots, Functional units, Renaming registers
Related Topics