Chapter: XML and Web Services
XML Logical Structures
Logical
Structures
[Definition: Each XML
document contains one or more elements, the boundaries of which are either
delimited by start-tags and end-tags, or, for empty elements, by an
empty-element tag. Each element has a type, identified by name, sometimes
called its “generic identifier” (GI), and may have a set of attribute
specifications.] Each attribute specification has a name and a value.

This specification does not
constrain the semantics, use, or (beyond syntax) names of the element types and
attributes, except that names beginning with a match to ((‘X’|’x’)(‘M’|’m’)(‘L’|’l’))
are
reserved for standardization in this or future ver-sions of this specification.
Well-formedness constraint: Element Type Match
The Name in an element’s
end-tag must match the element type in the start-tag.
Validity constraint: Element Valid
An element is valid if there
is a declaration matching elementdecl where the Name matches the element type,
and one of the following holds:
The declaration matches EMPTY and the element has no content.
The declaration matches children and the sequence of child elements
belongs to the language generated by the regular expression in the content
model, with optional white space (characters matching the nonterminal S)
between the start-tag and the first child element, between child elements, or
between the last child element and the end-tag. Note that a CDATA section
containing only white space does not match the nonterminal S, and hence cannot
appear in these positions.
The declaration matches Mixed and the content consists of character
data and child elements whose types match names in the content model.
The declaration matches ANY,
and the types of any child elements have been declared.
1 Start-Tags, End-ags, and Empty- Element
Tags
[Definition:
The beginning of every non-empty XML element is marked by a start-tag.]
Start-tag

The Name
in the start- and end-tags gives the element’s type. [Definition: The
Name-AttValue pairs are referred to as the attribute specifications of the element],
[Definition: with the Name in each pair referred to as the attribute name] and
[Definition: the content of the AttValue (the text between the ‘ or “
delimiters) as the attribute value.]Note that the order of attribute
specifications in a start-tag or empty-element tag is not significant.
Well-formedness constraint: Unique Att Spec
No
attribute name may appear more than once in the same start-tag or empty-element
tag.
Validity constraint: Attribute Value Type
The
attribute must have been declared; the value must be of the type declared for
it. (For attribute types, see (3) Attribute-List Declarations.)
Well-formedness constraint: No External Entity
References
Attribute
values cannot contain direct or indirect entity references to external entities.
Well-formedness constraint: No < in
Attribute Values
The
replacement text of any entity referred to directly or indirectly in an
attribute value must not contain a <.
An
example of a start-tag:
<termdef id=”dt-dog”
term=”dog”>
[Definition: The end of every
element that begins with a start-tag must be marked by an end-tag containing a
name that echoes the element’s type as given in the start-tag:]
An example of an end-tag:
</termdef>
[Definition: The text between
the start-tag and end-tag is called the element’s content:]
Content
of Elements
[43] content ::= CharData?
((element | Reference | CDSect | PI | ➥ Comment) CharData?)* /* */
[Definition: An element with
no content is said to be empty.] The representation of an empty element is
either a start-tag immediately followed by an end-tag, or an empty-element tag.
[Definition: An empty-element tag takes a special form:]
Tags for
Empty Elements
[44] EmptyElemTag ::= ‘<’ Name (S Attribute)* S?
‘/>’ [WFC: Unique
Att
➥ Spec]
Empty-element tags may be
used for any element which has no content, whether or not it is declared using
the keyword EMPTY. For interoperability, the empty-element tag should be used,
and should only be used, for elements which are declared EMPTY.
Examples of empty elements:
<IMG align=”left” src=”http://www.w3.org/Icons/WWW/w3c_home”
/>
<br></br>
<br/>
2
Element Type Declarations
The element structure of an
XML document may, for validation purposes, be constrained using element type
and attribute-list declarations. An element type declaration constrains the
element’s content.
Element type declarations
often constrain which element types can appear as children of the element. At
user option, an XML processor may issue a warning when a declaration mentions
an element type for which no declaration is provided, but this is not an error.
[Definition: An element type
declaration takes the form:]
Element Type Declaration
[45] elementdecl ::= ‘<!ELEMENT’ S Name S
contentspec S? ‘>’ [VC:
Unique Element Type Declaration]
[46] contentspec ::= ‘EMPTY’ | ‘ANY’ | Mixed |
children
where
the Name gives the element type being declared.
Validity constraint: Unique Element Type
Declaration
No
element type may be declared more than once.
Examples
of element type declarations:
<!ELEMENT br
EMPTY>
<!ELEMENT
p (#PCDATA|emph)* > <!ELEMENT %name.para; %content.para; >
<!ELEMENT container ANY>
2.1 Element Content
[Definition:
An element type has element content when elements of that type must con-tain
only child elements (no character data), optionally separated by white space
(charac-ters matching the nonterminal S).][Definition: In this case, the
constraint includes a content model, a simple grammar governing the allowed
types of the child elements and the order in which they are allowed to appear.]
The grammar is built on content particles (cps), which consist of names, choice
lists of content particles, or sequence lists of con-tent particles:
Element-content
Models
[47] children ::= (choice
| seq) (‘?’ | ‘*’
| ‘+’)?
[48] cp ::= (Name
| choice |
seq) (‘?’ | ‘*’ |
‘+’)?
[49] choice ::= ‘(‘
S? cp (
S? ‘|’ S? cp )+
S? ‘)’ /* */
/* */
[VC: Proper Group/PE
Nesting]
[50] seq ::= ‘(‘
S? cp (
S? ‘,’ S? cp )* S? ‘)’
/* */
[VC: Proper Group/PE
Nesting]
where each Name is the type
of an element which may appear as a child. Any content particle in a choice
list may appear in the element content at the location where the choice list
appears in the grammar; content particles occurring in a sequence list must
each appear in the element content in the order given in the list. The optional
character following a name or list governs whether the element or the content particles
in the list
may occur one or more (+),
zero or more (*), or zero or one times (?). The absence of such an operator
means that the element or content particle must appear exactly once. This
syntax and meaning are identical to those used in the productions in this
specification.
The content of an element
matches a content model if and only if it is possible to trace out a path
through the content model, obeying the sequence, choice, and repetition
opera-tors and matching each element in the content against an element type in
the content model. For compatibility, it is an error if an element in the
document can match more than one occurrence of an element type in the content
model. For more information, see E Deterministic Content Models.
Validity constraint: Proper Group/PE Nesting
Parameter-entity replacement
text must be properly nested with parenthesized groups. That is to say, if
either of the opening or closing parentheses in a choice, seq, or Mixed
construct is contained in the replacement text for a parameter entity, both
must be con-tained in the same replacement text.
For interoperability, if a
parameter-entity reference appears in a choice, seq, or Mixed construct, its
replacement text should contain at least one non-blank character, and nei-ther
the first nor last non-blank character of the replacement text should be a
connector (| or ,).
Examples of element-content
models:
<!ELEMENT spec
(front, body, back?)>
<!ELEMENT div1 (head, (p |
list | note)*, div2*)> <!ELEMENT dictionary-body (%div.mix; | %dict.mix;)*>
2.2
Mixed Content
[Definition: An element type
has mixed content when elements of that type may contain character data,
optionally interspersed with child elements.] In this case, the types of the
child elements may be constrained, but not their order or their number of
occurrences:
Mixed-content
Declaration
[51] Mixed ::= ‘(‘ S? ‘#PCDATA’ (S? ‘|’ S? Name)* S? ‘)*’ | ‘(‘ S?
‘#PCDATA’ S? ‘)’ [VC: Proper Group/PE Nesting]
[VC: No
Duplicate Types]
where the Names give the
types of elements that may appear as children. The keyword #PCDATA derives
historically from the term “parsed character data.”
Validity constraint: No Duplicate Types
The same
name must not appear more than once in a single mixed-content declaration.
Examples
of mixed content declarations:
<!ELEMENT p
(#PCDATA|a|ul|b|i|em)*>
<!ELEMENT
p (#PCDATA | %font; | %phrase; | %special; | %form;)* > <!ELEMENT b
(#PCDATA)>
3 Attribute-List Declarations
Attributes
are used to associate name-value pairs with elements. Attribute specifications
may appear only within start-tags and empty-element tags; thus, the productions
used to recognize them appear in (1) Start-Tags, End-Tags, and Empty-Element
Tags. Attribute-list declarations may be used:
To define the set of
attributes pertaining to a given element type.
To establish type constraints
for these attributes.
To provide default values for
attributes.
[Definition:
Attribute-list declarations specify the name, data type, and default value (if
any) of each attribute associated with a given element type:]
Attribute-list
Declaration
[52] AttlistDecl ::= ‘<!ATTLIST’ S Name AttDef*
S? ‘>’
[53] AttDef ::= S Name S
AttType S DefaultDecl
The Name
in the AttlistDecl rule is the type of an element. At user option, an XML processor
may issue a warning if attributes are declared for an element type not itself
declared, but this is not an error. The Name in the AttDef rule is the name of the
attribute.
When more than one AttlistDecl is provided for a given
element type, the contents of all those provided are merged. When more than one
definition is provided for the same attribute of a given element type, the
first declaration is binding and later declarations are ignored. For
interoperability, writers of DTDs may choose to provide at most one
attribute-list declaration for a given element type, at most one attribute
definition for a given attribute name in an attribute-list declaration, and at
least one attribute definition in each attribute-list declaration. For
interoperability, an XML processor may at user option issue a warning when more
than one attribute-list declaration is provided for a given ele-ment type, or
more than one attribute definition is provided for a given attribute, but this
is not an error.
3.1
Attribute Types
XML attribute types are of
three kinds: a string type, a set of tokenized types, and enu-merated types.
The string type may take any literal string as a value; the tokenized types
have varying lexical and semantic constraints. The validity constraints noted
in the gram-mar are applied after the attribute value has been normalized as
described in (3) Attribute-List Declarations.
Attribute
Types
[54] AttType ::= StringType |
TokenizedType | EnumeratedType
[55] StringType ::= ‘CDATA’
[56] TokenizedType ::= ‘ID’
[VC: ID]
[VC: One ID per Element
Type]
[VC: ID Attribute
Default]
| ‘IDREF’ [VC: IDREF]
| ‘IDREFS’ [VC: IDREF]
| ‘ENTITY’ [VC: Entity
Name]
| ‘ENTITIES’ [VC:
Entity
Name]
| ‘NMTOKEN’ [VC: Name
Token]
| ‘NMTOKENS’ [VC: Name
Token]
Validity constraint: ID
Values of type ID must match
the Name production. A name must not appear more than once in an XML document
as a value of this type; i.e., ID values must uniquely identify the elements
which bear them.
Validity constraint: One ID per Element Type
No element type may have more
than one ID attribute specified.
Validity constraint: ID Attribute Default
An ID attribute must have a
declared default of #IMPLIED or #REQUIRED.
Validity constraint: IDREF
Values of type IDREF must match the Name
production, and values of type IDREFS must match Names; each Name must match the value of an ID attribute on some element in
the XML document; i.e. IDREF values must match the value of some ID attribute.
Validity constraint: Entity Name
Values of type ENTITY must match the Name
production, values of type ENTITIES must match Names; each Name must match the name of an unparsed
entity declared in the DTD.
Validity constraint: Name Token
Values
of type NMTOKEN must match the Nmtoken production; values of type NMTOKENS must match Nmtokens.
[Definition:
Enumerated attributes can take one of a list of values provided in the
decla-ration]. There are two kinds of enumerated types:
Enumerated
Attribute Types
[57] EnumeratedType ::= NotationType |
Enumeration
[58] NotationType ::= ‘NOTATION’
S ‘(‘ S?
Name (S? ‘|’
S? Name)* S? ‘)’
[VC: Notation
Attributes]
[VC: One Notation
Per Element Type]
[VC: No Notation
on Empty Element]
[59] Enumeration ::= ‘(‘
S? Nmtoken (S?
‘|’ S? Nmtoken)*
S? ‘)’
[VC: Enumeration]
A NOTATION attribute identifies a
notation, declared in the DTD with associated system and/or public identifiers,
to be used in interpreting the element to which the attribute is attached.
Validity constraint: Notation Attributes
Values
of this type must match one of the notation names included in the declaration;
all notation names in the declaration must be declared.
Validity constraint: One Notation Per Element
Type
No
element type may have more than one NOTATION attribute specified.
Validity constraint: No Notation on Empty
Element
For
compatibility, an attribute of type NOTATION must not be declared on an element
declared EMPTY.
Validity constraint: Enumeration
Values
of this type must match one of the Nmtoken tokens in the declaration.
For
interoperability, the same Nmtoken should not occur more than once in the
enumer-ated attribute types of a single element type.
3.2
Attribute Defaults
An attribute declaration
provides information on whether the attribute’s presence is required, and if
not, how an XML processor should react if a declared attribute is absent in a
document.
Attribute
Defaults
[60] DefaultDecl ::= ‘#REQUIRED’ | ‘#IMPLIED’ | ((‘#FIXED’ S)?
AttValue) [VC: Required Attribute]
[VC: Attribute Default Legal]
[WFC: No < in Attribute Values] [VC: Fixed Attribute Default]
In an attribute declaration,
#REQUIRED means that the attribute must always be pro-vided, #IMPLIED that no
default value is provided. [Definition: If the declaration is nei-ther
#REQUIRED nor #IMPLIED, then the AttValue value contains the declared default
value; the #FIXED keyword states that the attribute must always have the
default value. If a default value is declared, when an XML processor encounters
an omitted attribute, it is to behave as though the attribute were present with
the declared default value.]
Validity constraint: Required Attribute
If the default declaration is
the keyword #REQUIRED, then the attribute must be speci-fied for all elements
of the type in the attribute-list declaration.
Validity constraint: Attribute Default Legal
The declared default value
must meet the lexical constraints of the declared attribute type.
Validity constraint: Fixed Attribute Default
If an attribute has a default
value declared with the #FIXED keyword, instances of that attribute must match
the default value.
Examples of attribute-list
declarations:
<!ATTLIST termdef
id ID
#REQUIRED name CDATA #IMPLIED>
<!ATTLIST list
type
(bullets|ordered|glossary) “ordered”> <!ATTLIST form
method CDATA #FIXED “POST”>
3.3
Attribute-Value Normalization
Before the value of an
attribute is passed to the application or checked for validity, the XML
processor must normalize the attribute value by applying the algorithm below,
or by using some other method such that the value passed to the application is
the same as that produced by the algorithm.
All line breaks must have
been normalized on input to #xA as described in 2.11 End-of-Line Handling, so
the rest of this algorithm operates on text normalized in this way.
Begin with a normalized value
consisting of the empty string.
For each character, entity
reference, or character reference in the unnormalized attribute value,
beginning with the first and continuing to the last, do the following:
For a character reference,
append the referenced character to the normalized value.
For an entity reference,
recursively apply step 3 of this algorithm to the replace-ment text of the
entity.
For a white space character
(#x20, #xD, #xA, #x9), append a space character (#x20) to the normalized value.
For another character, append
the character to the normalized value.
If the
attribute type is not CDATA, then the XML processor must further process the
normalized attribute value by discarding any leading and trailing space (#x20)
characters, and by replacing sequences of space (#x20) characters by a single
space (#x20) character.
Note
that if the unnormalized attribute value contains a character reference to a
white space character other than space (#x20), the normalized value contains
the referenced character itself (#xD, #xA or #x9). This contrasts with the case
where the unnormalized value contains a white space character (not a
reference), which is replaced with a space character (#x20) in the normalized
value and also contrasts with the case where the unnormalized value contains an
entity reference whose replacement text contains a white space character; being
recursively processed, the white space character is replaced with a space
character (#x20) in the normalized value.
All
attributes for which no declaration has been read should be treated by a
non-validat-ing processor as if declared CDATA.
Following
are examples of attribute normalization. Given the following declarations:
<!ENTITY d “
”>
<!ENTITY a “
”> <!ENTITY da “
”>
the attribute specifications
in the left column below would be normalized to the character sequences of the
middle column if the attribute a is declared NMTOKENS and to those of the right
columns if a is declared CDATA.
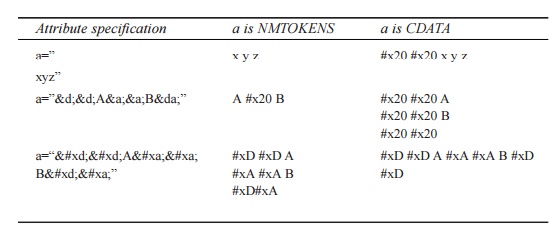
Note that the last example is invalid (but well-formed) if a is declared to be of type NMTOKENS.
4
Conditional Sections
[Definition: Conditional
sections are portions of the document type declaration external subset which
are included in, or excluded from, the logical structure of the DTD based on
the keyword which governs them.]
Conditional
Section

Validity constraint: Proper Conditional Section/PE Nesting
If any of the “<![“, “[“,
or “]]>” of a conditional section is contained in the replacement text for a
parameter-entity reference, all of them must be contained in the same
replace-ment text.
Like the internal and
external DTD subsets, a conditional section may contain one or more complete
declarations, comments, processing instructions, or nested conditional
sections, intermingled with white space.
If the
keyword of the conditional section is INCLUDE, then the contents of the
condi-tional section are part of the DTD. If the keyword of the conditional
section is IGNORE, then the contents of the conditional section are not
logically part of the DTD. If a condi-tional section with a keyword of INCLUDE
occurs within a larger conditional section with a keyword of IGNORE, both the
outer and the inner conditional sections are ignored. The contents of an
ignored conditional section are parsed by ignoring all charac-ters after the
“[“ following the keyword, except conditional section starts “<![“ and ends
“]]>”, until the matching conditional section end is found. Parameter entity
references are not recognized in this process.
If the
keyword of the conditional section is a parameter-entity reference, the
parameter entity must be replaced by its content before the processor decides
whether to include or ignore the conditional section.
An
example:
<!ENTITY
% draft ‘INCLUDE’ > <!ENTITY % final ‘IGNORE’ >
<![%draft;[
<!ELEMENT
book (comments*, title, body, supplements?)> ]]>
<![%final;[
<!ELEMENT
book (title, body, supplements?)> ]]>
Related Topics