Chapter: XML and Web Services
XML Documents
Documents
[Definition: A data object is
an XML document if it is well-formed, as defined in this specification. A
well-formed XML document may in addition be valid if it meets certain further
constraints.]
Each XML document has both a
logical and a physical structure. Physically, the docu-ment is composed of
units called entities. An entity may refer to other entities to cause their
inclusion in the document. A document begins in a “root” or document entity.
Logically, the document is
composed of declarations, elements, comments, character ref-erences, and
processing instructions, all of which are indicated in the document by explicit
markup. The logical and physical structures must nest properly, as described in
4.3.2 Well-Formed Parsed Entities.
1
Well-Formed XML Documents
[Definition: A textual object
is a well-formed XML document if:]
Taken as a whole, it matches the production labeled document.
It meets all the well-formedness constraints given in this
specification.
Each of the parsed entities which is referenced directly or
indirectly within the document is well-formed.
Matching
the document production implies that:
It contains one or more
elements.
[Definition: There is exactly
one element, called the root, or document element, no part of which appears in
the content of any other element.] For all other elements, if the start-tag is
in the content of another element, the end-tag is in the content of the same
element. More simply stated, the elements, delimited by start- and end-tags,
nest properly within each other.
[Definition: As a consequence
of this, for each non-root element C in the docu-ment, there is one other
element P in the document such that C is in the content of P, but is not in the
content of any other element that is in the content of P. P is referred to as
the parent of C, and C as a child of P.]
2 Characters
[Definition:
A parsed entity contains text, a sequence of characters, which may represent
markup or character data.] [Definition: A character is an atomic unit of text
as specified by ISO/IEC 10646 [ISO/IEC 10646] (see also [ISO/IEC 10646-2000]).
Legal characters are tab, carriage return, line feed, and the legal characters
of Unicode and ISO/IEC 10646. The versions of these standards cited in A.1
Normative References were current at the time this document was prepared. New
characters may be added to these standards by amendments or new editions.
Consequently, XML processors must accept any charac-ter in the range specified
for Char. The use of “compatibility characters”, as defined in section 6.8 of
[Unicode] (see also D21 in section 3.6 of [Unicode3]), is discouraged.]
Character
Range
[2] Char ::= #x9 |
#xA | #xD
| [#x20-#xD7FF] |
[#xE000-#xFFFD] |
➥ [#x10000-#x10FFFF] /* any Unicode character,
excluding the surrogate blocks, FFFE, and FFFF. */
The
mechanism for encoding character code points into bit patterns may vary from entity
to entity. All XML processors must accept the UTF-8 and UTF-16 encodings of
10646; the mechanisms for signaling which of the two is in use, or for bringing
other encodings into play, are discussed later, in 4.3.3 Character Encoding in
Entities.
3 Common Syntactic Constructs
This
section defines some symbols used widely in the grammar.
S (white space) consists of
one or more space (#x20) characters, carriage returns, line feeds, or tabs.
White
Space
[3] S ::= (#x20 | #x9
| #xD | #xA)+
Characters are classified for
convenience as letters, digits, or other characters. A letter consists of an
alphabetic or syllabic base character or an ideographic character. Full
defi-nitions of the specific characters in each class are given in B Character
Classes.
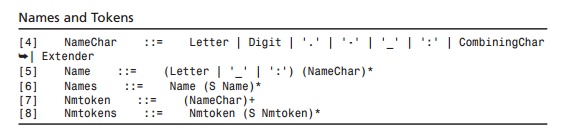
[Definition: A Name is a
token beginning with a letter or one of a few punctuation char-acters, and
continuing with letters, digits, hyphens, underscores, colons, or full stops,
together known as name characters.] Names beginning with the string “xml”, or
any string which would match ((‘X’|’x’) (‘M’|’m’) (‘L’|’l’)), are reserved for
standardization in this or future versions of this specification.
An Nmtoken (name token) is
any mixture of name characters.
Literal data is any quoted
string not containing the quotation mark used as a delimiter for that string.
Literals are used for specifying the content of internal entities
(EntityValue), the values of attributes (AttValue), and external identifiers
(SystemLiteral). Note that a SystemLiteral can be parsed without scanning for
markup.

4 Character Data and Markup
Text
consists of intermingled character data and markup. [Definition: Markup takes
the form of start-tags, end-tags, empty-element tags, entity references,
character references, comments, CDATA section delimiters, document type
declarations, processing instruc-tions, XML declarations, text declarations,
and any white space that is at the top level of the document entity (that is,
outside the document element and not inside any other markup).]
[Definition:
All text that is not markup constitutes the character data of the document.]
The
ampersand character (&) and the left angle bracket (<) may appear in
their literal form only when used as markup delimiters, or within a comment, a
processing instruc-tion, or a CDATA section. If they are needed elsewhere, they
must be escaped using either numeric character references or the strings
“&” and “<” respectively. The right angle bracket (>) may be
represented using the string “>”, and must, for com-patibility, be
escaped using “>” or a character reference when it appears in the string
“]]>” in content, when that string is not marking the end of a CDATA
section.
In the
content of elements, character data is any string of characters which does not
con-tain the start-delimiter of any markup. In a CDATA section, character data
is any string of characters not including the CDATA-section-close delimiter,
“]]>”.
To allow
attribute values to contain both single and double quotes, the apostrophe or
sin-gle-quote character (‘) may be represented as “'”, and the
double-quote character (“) as “"”.
Character
Data
[14] CharData ::= [^<&]* - ([^<&]* ‘]]>’
[^<&]*)
5
Comments
[Definition: Comments may
appear anywhere in a document outside other markup; in addition, they may
appear within the document type declaration at places allowed by the grammar.
They are not part of the document’s character data; an XML processor may, but
need not, make it possible for an application to retrieve the text of comments.
For compatibility, the string “—” (double-hyphen) must not occur within
comments.] Parameter entity references are not recognized within comments.
Comments
[15] Comment ::= ‘<!--’ ((Char -
‘-’) | (‘-’
(Char - ‘-’)))*
‘-->’
An example of a comment:
<!-- declarations
for <head> &
<body> -->
6
Processing Instructions
[Definition: Processing
instructions (PIs) allow documents to contain instructions for applications.]
Processing
Instructions

PIs are not part of the
document’s character data, but must be passed through to the application. The
PI begins with a target (PITarget) used to identify the application to which
the instruction is directed. The target names “XML”, “xml”, and so on are
reserved for standardization in this or future versions of this specification.
The XML
Notation
mechanism may be used for formal declaration of PI targets. Parameter entity
references are not recognized within processing instructions.
7 CDATA Sections
[Definition:
CDATA sections may occur anywhere character data may occur; they are used to
escape blocks of text containing characters which would otherwise be recognized
as markup. CDATA sections begin with the string “<![CDATA[“ and end with the
string “]]>”:]
CDATA
Sections

Within a
CDATA section, only the CDEnd string is recognized as markup, so that left
angle brackets and ampersands may occur in their literal form; they need not
(and can-not) be escaped using “<” and “&”. CDATA sections
cannot nest.
An
example of a CDATA section, in which “<greeting>” and “</greeting>”
are recog-nized as character data, not markup:
<![CDATA[<greeting>Hello, world!</greeting>]]>
8 Prolog and Document Type Declaration
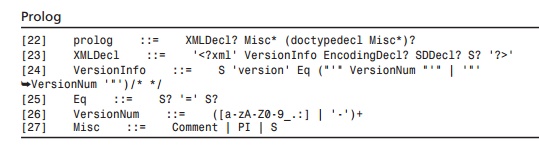
[Definition:
XML documents should begin with an XML declaration which specifies the version
of XML being used.] For example, the following is a complete XML document,
well-formed but not valid:
<?xml version=”1.0”?> <greeting>Hello, world!</greeting>
and so
is this:
<greeting>Hello, world!</greeting>
The version number “1.0”
should be used to indicate conformance to this version of this specification;
it is an error for a document to use the value “1.0” if it does not conform to
this version of this specification. It is the intent of the XML working group
to give later versions of this specification numbers other than “1.0”, but this
intent does not indicate a commitment to produce any future versions of XML,
nor if any are produced, to use any particular numbering scheme. Since future
versions are not ruled out, this construct is provided as a means to allow the
possibility of automatic version recognition, should it become necessary.
Processors may signal an error if they receive documents labeled with versions
they do not support.
The function of the markup in
an XML document is to describe its storage and logical structure and to
associate attribute-value pairs with its logical structures. XML provides a
mechanism, the document type declaration, to define constraints on the logical
structure and to support the use of predefined storage units. [Definition: An
XML document is valid if it has an associated document type declaration and if
the document complies with the constraints expressed in it.]
The document type declaration
must appear before the first element in the document.
[Definition: The XML document
type declaration contains or points to markup declara-tions that provide a
grammar for a class of documents. This grammar is known as a doc-ument type
definition, or DTD. The document type declaration can point to an external
subset (a special kind of external entity) containing markup declarations, or
can contain the markup declarations directly in an internal subset, or can do
both. The DTD for a document consists of both subsets taken together.]
[Definition: A markup
declaration is an element type declaration, an attribute-list decla-ration, an
entity declaration, or a notation declaration.] These declarations may be
con-tained in whole or in part within parameter entities, as described in the
well-formedness and validity constraints below. For further information, see 4
Physical Structures.
Document
Type Definition

Note
that it is possible to construct a well-formed document containing a
doctypedecl that neither points to an external subset nor contains an internal
subset.
The
markup declarations may be made up in whole or in part of the replacement text
of parameter entities. The productions later in this specification for
individual nonterminals (elementdecl, AttlistDecl, and so on) describe the
declarations after all the parameter entities have been included.
Parameter
entity references are recognized anywhere in the DTD (internal and external
subsets and external parameter entities), except in literals, processing
instructions, com-ments, and the contents of ignored conditional sections (see
3.4 Conditional Sections).
They are
also recognized in entity value literals. The use of parameter entities in the
internal subset is restricted as described below.
Validity constraint: Root Element Type
The Name
in the document type declaration must match the element type of the root
element.
Validity constraint: Proper Declaration/PE
Nesting
Parameter-entity
replacement text must be properly nested with markup declarations. That is to
say, if either the first character or the last character of a markup
declaration (markupdecl above) is contained in the replacement text for a
parameter-entity reference, both must be contained in the same replacement text.
Well-formedness constraint: PEs in Internal
Subset
In the
internal DTD subset, parameter-entity references can occur only where markup
declarations can occur, not within markup declarations. (This does not apply to
refer-ences that occur in external parameter entities or to the external
subset.)
Well-formedness constraint: External Subset
The
external subset, if any, must match the production for extSubset.
Well-formedness constraint: PE Between
Declarations
The
replacement text of a parameter entity reference in a DeclSep must match the
production extSubsetDecl.
Like the internal subset, the
external subset and any external parameter entities refer-enced in a DeclSep
must consist of a series of complete markup declarations of the types allowed
by the non-terminal symbol markupdecl, interspersed with white space or
para-meter-entity references. However, portions of the contents of the external
subset or of these external parameter entities may conditionally be ignored by
using the conditional section construct; this is not allowed in the internal
subset.
The external subset and
external parameter entities also differ from the internal subset in that in
them, parameter-entity references are permitted within markup declarations, not
only between markup declarations.
An example of an XML document
with a document type declaration:
<?xml version=”1.0”?> <!DOCTYPE
greeting SYSTEM “hello.dtd”> <greeting>Hello,
world!</greeting>
The system identifier
“hello.dtd” gives the address (a URI reference) of a DTD for the document.
The declarations can also be
given locally, as in this example:

<?xml version=”1.0”
encoding=”UTF-8” ?> <!DOCTYPE greeting [
<!ELEMENT greeting
(#PCDATA)>
]>
<greeting>Hello, world!</greeting>
If both the external and
internal subsets are used, the internal subset is considered to occur before
the external subset. This has the effect that entity and attribute-list
declara-tions in the internal subset take precedence over those in the external
subset.
9
Standalone Document Declaration
Markup declarations can
affect the content of the document, as passed from an XML processor to an
application; examples are attribute defaults and entity declarations. The
standalone document declaration, which may appear as a component of the XML
decla-ration, signals whether or not there are such declarations which appear
external to the document entity or in parameter entities. [Definition: An
external markup declaration is defined as a markup declaration occurring in the
external subset or in a parameter entity (external or internal, the latter
being included because non-validating processors are not required to read
them).]
Standalone Document Declaration

In a
standalone document declaration, the value “yes” indicates that there are no
external markup declarations which affect the information passed from the XML
processor to the application. The value “no” indicates that there are or may be
such external markup dec-larations. Note that the standalone document
declaration only denotes the presence of external declarations; the presence,
in a document, of references to external entities, when those entities are
internally declared, does not change its standalone status.
If there
are no external markup declarations, the standalone document declaration has no
meaning. If there are external markup declarations but there is no standalone
document declaration, the value “no” is assumed.
Any XML
document for which standalone=”no” holds can be converted algorithmically to a
standalone document, which may be desirable for some network delivery
applica-tions.
Validity constraint: Standalone Document
Declaration
The
standalone document declaration must have the value “no” if any external markup
declarations contain declarations of:
attributes with default values, if elements to which these
attributes apply appear in the document without specifications of values for
these attributes, or
entities (other than amp, lt, gt, apos, quot), if references to
those entities appear in the document, or
attributes with values subject to normalization, where the
attribute appears in the document with a value which will change as a result of
normalization, or
element types with element content, if white space occurs directly
within any instance of those types.
An
example XML declaration with a standalone document declaration:
<?xml version=”1.0”
standalone=’yes’?>
10
White Space Handling
In editing XML documents, it
is often convenient to use “white space” (spaces, tabs, and blank lines) to set
apart the markup for greater readability. Such white space is typically not
intended for inclusion in the delivered version of the document. On the other
hand, “significant” white space that should be preserved in the delivered
version is common, for example in poetry and source code.
An XML processor must always
pass all characters in a document that are not markup through to the
application. A validating XML processor must also inform the application which
of these characters constitute white space appearing in element content.
A special attribute named
xml:space may be attached to an element to signal an intention that in that
element, white space should be preserved by applications. In valid docu-ments,
this attribute, like any other, must be declared if it is used. When declared,
it must be given as an enumerated type whose values are one or both of
“default” and “pre-serve”. For example:
<!ATTLIST poem xml:space (default|preserve) ‘preserve’>
<!-- -->
<!ATTLIST pre
xml:space (preserve) #FIXED
‘preserve’>
The value “default” signals
that applications’ default white-space processing modes are acceptable for this
element; the value “preserve” indicates the intent that applications preserve
all the white space. This declared intent is considered to apply to all
elements within the content of the element where it is specified, unless
overriden with another instance of the xml:space attribute.
The root element of any
document is considered to have signaled no intentions as regards application
space handling, unless it provides a value for this attribute or the attribute
is declared with a default value.
11
End-of-Line Handling
XML parsed entities are often
stored in computer files which, for editing convenience, are organized into
lines. These lines are typically separated by some combination of the
characters carriage-return (#xD) and line-feed (#xA).
To simplify the tasks of
applications, the characters passed to an application by the XML processor must
be as if the XML processor normalized all line breaks in external parsed
entities (including the document entity) on input, before parsing, by
translating both the two-character sequence #xD #xA and any #xD that is not
followed by #xA to a single #xA character.
12
Language Identification
In document processing, it is
often useful to identify the natural or formal language in which the content is
written. A special attribute named xml:lang may be inserted in docu-ments to
specify the language used in the contents and attribute values of any element
in an XML document. In valid documents, this attribute, like any other, must be
declared if it is used. The values of the attribute are language identifiers as
defined by [IETF RFC 1766], Tags for the Identification of Languages, or its
successor on the IETF Standards Track.
For
example:
<p
xml:lang=”en”>The quick brown fox jumps over the lazy dog.</p> <p
xml:lang=”en-GB”>What colour is it?</p>
<p
xml:lang=”en-US”>What color is it?</p> <sp who=”Faust” desc=’leise’
xml:lang=”de”>
<l>Habe
nun, ach! Philosophie,</l> <l>Juristerei, und Medizin</l>
<l>und leider auch Theologie</l>
<l>durchaus studiert mit heißem Bemüh’n.</l>
</sp>
The
intent declared with xml:lang is considered to apply to all attributes and
content of the element where it is specified, unless overridden with an
instance of xml:lang on another element within that content.
A simple
declaration for xml:lang might take the form
xml:lang NMTOKEN
#IMPLIED
but
specific default values may also be given, if appropriate. In a collection of
French poems for English students, with glosses and notes in English, the
xml:lang attribute might be declared this way:
<!ATTLIST poem xml:lang NMTOKEN ‘fr’>
<!ATTLIST gloss xml:lang NMTOKEN ‘en’>
<!ATTLIST note xml:lang NMTOKEN
‘en’>
Related Topics