Chapter: XML and Web Services : Essentials of XML : The Fundamentals of XML
XML Document Structure
XML
Document Structure
As you can tell from the
example in Listing 2.2, an XML document consists of a number of discrete
components or sections. Although not all the sections of an XML document may be
necessary, their use and inclusion helps to make for a well-structured XML
docu-ment that can easily be transported between systems and devices.
The major portions of an XML
document include the following:
The XML declaration
The Document Type Declaration
The element data
The attribute data
The character data or XML
content
Each of these major
components will be explored in great detail in this section of the chapter. By
the end of this section, you should have a thorough understanding of what
comprises an XML document.
XML
Declaration
The first part of an XML
document is the declaration. A declaration is exactly as it sounds: It is a
definite way of stating exactly what the document contains. Just like the Declaration of Independence states that
the United States planned to separate itself from Great Britain, the XML declaration states that the following
document contains XML content.
The XML declaration is a
processing instruction of the form <?xml ...?>. Although it is not required, the presence of
the declaration explicitly identifies the document as an XML document and
indicates the version of XML to which it was authored. In addition, the XML
declaration indicates the presence of external markup declarations and
charac-ter encoding. Because a number of document formats use markup similar to
XML, the declaration is useful in establishing the document as being compliant
with a specific ver-sion of XML without any doubt or ambiguity. In general,
every XML document should use an XML declaration. As documents increase in size
and complexity, this importance likewise grows.
The XML declaration consists
of a number of components. Table 2.2 lists these various components and their
specifications.

The standalone document
declaration defines whether an external DTD will be processed as part of the
XML document. When standalone is set to “yes”, only internal DTDs will be allowed. When it is set to “no”, an external DTD is required
and an internal DTD becomes an optional feature. Listing 2.3 illustrates a few
valid XML declarations.

The first declaration defines
a well-formed XML document, whereas the second defines a well-formed and valid
XML document. The third declaration shows a more complete definition that
states a typical use-case for XML. Namely, the declaration states that the XML
document complies with version 1.0 of the specification and requires external
markup declarations that are encoded in UTF-8.
Document
Type Declaration
Once we are aware that we are
talking about a specific version of an XML document, the next step is to be
more specific about the content contained within. The Document Type Declaration
(DOCTYPE) gives a name to the XML
content and provides a means to guaran-tee the document’s validity, either by
including or specifying a link to a Document Type Definition (DTD). Although
SGML requires a Document Type Declaration, XML has no restrictions of the sort,
although one should be included to avoid an ambiguous under-standing of
document content.
Although well-formed XML
documents don’t require the inclusion of the DOCTYPE, valid XML documents do. This discussion of
“well formed” and “valid” will be covered later in this document, but the basic
gist is that XML documents can be fairly freeform or comply to a strict
guideline of what content can be contained within. Valid XML docu-ments must
declare the document type to which they comply, whereas well-formed XML
documents can include the DOCTYPE to simplify the task of the various tools that will be
manipulating the XML document.
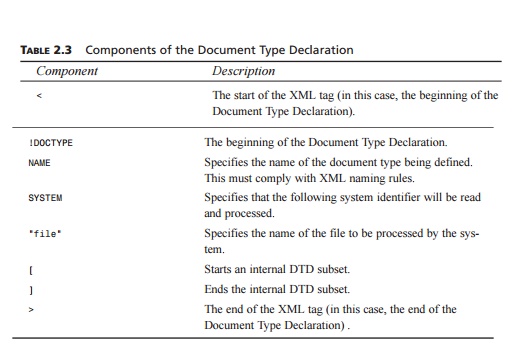
A Document Type Declaration names
the document type and identifies the internal con-tent by specifying the root element, in essence the first XML
tag that the XML-process-ing tools will encounter in the document. A DOCTYPE can identify the constraints
on the validity of the document by making a reference to an external DTD subset
and/or include the DTD internally within the document by means of an internal
DTD subset. The gen-eral forms of Document Type Declarations follow the forms
identified in Listing 2.4.
LISTING 2.4 General
Forms of the Document Type Declarations
<!DOCTYPE NAME SYSTEM
“file”> <!DOCTYPE NAME [ ]>
<!DOCTYPE NAME
SYSTEM “file” [
]>
In the first form listed, the
DOCTYPE is referring to a document
that only allows use of an externally defined DTD subset. The second
declaration only allows an internally defined subset within the document. The
final listing provides a place for inclusion of an inter-nally defined DTD
subset between the square brackets while also making use of an external subset.
In the preceding listing, the keyword NAME should be replaced with the actual root
element contained in the document, and the “file” keyword should be replaced with a path to a
valid DTD. In the case of our shirt example, the DOCTYPE is
<!DOCTYPE shirt
SYSTEM “shirt.dtd”>
because the first tag in the
document will be the <shirt> element and our DTD is saved to a file named shirt.dtd, which saved in the same
path as the XML document.
The only real difference
between internally and externally defined DTD subsets is that the DTD content
itself is contained within the square brackets, in the case of internal
subsets, whereas external subsets save this content to a file for reference,
usually with a .dtd extension. The actual components of the Document Type Declaration
are listed in Table 2.3.
Markup
and Content
In addition to the XML
declaration and the Document Type Declaration, XML docu-ments are composed of
markup and content. In general, six kinds of markup can occur in an XML
document: elements, entity references, comments, processing instructions,
marked sections, and Document Type Declarations. The following sections explore
these markup types and illustrate how they are used. Of course, needless to
say, that which is not markup is content, and this content must comply with
rules of its own.
Elements
Within an XML document,
elements are the most common form of markup. XML ele-ments are either a matched
pair of XML tags or single XML tags that are “self-closing.” Matching XML tags
consist of markup tags that contain the same content, except that the ending
tag is prefixed with a forward slash. For example, our shirt element begins
with <shirt>
and ends
with
</shirt>. Everything between these tags is additional XML text that has either been defined
by a DTD or can exist by virtue of the document merely being well formed. When
elements do not come in pairs, the element name is suffixed by the forward
slash. For example, if we were merely making a statement that a shirt existed,
we may use <on_sale/>. In this case, there would be no other matching element of the
same name used in a different manner. These “unmatched” elements are known as empty elements. The trailing “/>” in the modified syntax
indicates to a program process-ing the XML document that the element is empty
and no matching end tag should be sought. Because XML documents do not require
a Document Type Declaration, without this clue it could be impossible for an
XML parser to determine which tags were inten-tionally empty and which had been
left empty by mistake.
A question arises about the
difference between empty elements and matched element tags that simply contain
no content. In reality, there is basically no distinction between the two. It
is valid in XML to use the empty-element tag syntax in either case. Therefore,
it is legal to use a matched start and end tag pair for elements that are
declared as empty. However, for concerns of interoperability and parser
compliance, it is best to use the empty-element syntax for elements declared as
empty and to make sure that other ele-ments have some content contained within.
Elements can be arbitrarily
nested within other elements ad infinitum. In essence, XML is a hierarchical
tree. This means that XML elements exist within other elements and can branch
off with various children nodes. Although these elements may be restricted by
DTDs or schema, the nature of XML is to allow for the growth of these elements
in a manner that’s as “wide” or “deep” as possible. This means that a single
XML element can contain any number of child elements, and the depth of the XML
tree can consist of any number of nodes.
You can pretty much name XML
elements anything you want, but specific rules need to be followed so that the
elements aren’t confused with other markup content. XML ele-ments can contain
letters, numbers, and other characters, but names cannot start with a number or
any punctuation character. XML names cannot contain spaces because white-space
is used within an element to separate the various attribute sections. Also, XML
ele-ments cannot contain the greater-than or less-than characters for obvious
reasons. For less-obvious reasons, XML elements cannot start with the letters
“xml” because they are reserved for future use. Also, XML elements cannot
contain the colon character because it is reserved for use in XML namespaces
(covered later in this chapter).
In particular, no XML element
names are reserved because namespaces can be used to avoid inadvertent
conflicts. Although punctuation marks (other than the colon) can be used within
an XML element name, you should avoid the hyphen (-) and period (.) characters in element names
because some software applications might confuse them for arithmetic or object
operations. Element names should be descriptive and not confusing. After all,
one of the main values of XML is that it can be read by humans! For example,
what does <jxf12> mean to anyone but a computer—if anything at all? Document
cre-ators should use descriptive terms that accurately and as specifically as
possible describe the content contained within.
Element names can be as long
as you like, with almost no real size limitation. This means that the element <wow_this_really_is_one_heck_of_a_long_element_name> is actually valid, but what
programmer would want to type that element repeatedly or encode a soft-ware
application to key on that particular element name. Also, some devices with
con-strained memory capabilities may not work well with overly long XML tag
names. In any case, long names are an annoyance to developers, systems, and
users alike, despite XML’s support for this feature. It’s best to leave long
content strings to the XML content and keep them out of element and attribute
names. XML also allows for the use of non-English letters, such as á, é, and ò,
in a document. In fact, XML allows all Unicode 2.3 characters to be used,
although there is an effort to upgrade the specification to further use Unicode
3.0 characters in attribute and element names. However, there is no such
restric-tion on XML content, which allows any valid Unicode character to be
used.
Attributes
Within elements, additional
information can be communicated to XML processors that modifies the nature of
the encapsulated content. For example, we may have specified a <price> element, but how do we know
what currency this applies to? Although it’s pos-sible to create a <currency> subtag, another more viable
approach is to use an attribute. Attributes are name/value pairs contained
within the start element that can specify text strings that modify the context
of the element. Listing 2.5 shows an example of possible attributes in our
shirt example.
LISTING 2.5 Attribute
Examples
<price
currency=”USD”>…</price>
<on_sale
start_date=”10-15-2001”/>
One of the significant
features of attributes is that the content described by them can fol-low strict
rules as to their value. Attributes can be required, optional, or contain a
fixed value. Required or optional attributes can either contain freeform text
or contain one of a set list of enumerated values. Fixed attributes, if
present, must contain a specific value. Attributes can specify a default value
that is applied if the attribute is optional but not present. With these
properties, attributes can add a considerable amount of value to ele-ment content.
For example, we may wish to restrict the possible currency values submit-ted to
a list of acceptable three-character ISO currency codes. Or, we may only allow
the value “USD” to be submitted. Likewise, we can specify that if no currency
value is sub-mitted, the system will assume “USD” as the default value.
As
you have seen, we can represent information in either elements or attrib-utes.
So, when is the right time to communicate information in an element ver-sus
using an attribute to communicate the same information. For instance, in our
shirt example, when should we use <shirt><color>red</color></shirt>
versus <shirt color=”red”>? This issue of
elements versus attributes is a con-stantly recurring question that can be
traced back to the SGML days. Of course, the answer is, it depends! After all,
both formats are valid.
The
main way to determine whether an element approach is more favorable to an
attribute approach, or vice versa, is to identify how the information is to be
used. Because most XML users agree that the decision is dependent on the
implementation, many would argue that XML is not really an ideal language for
data modeling, which requires a more strict sense for how data should be
represented. Some of the common arguments are as follows.
Some
visual XML browsers display element information but ignore attribute val-ues
for purposes of display. Of course, many technologies display both element and
attribute values. For those that don’t, the use of elements may prevail over
attributes.
When
DTDs are used, attributes allow default or enumerated values as well as provide
a means to restrict the possible data entered. Of course, various XML-based
schema technologies are allowing these very same features in elements. However,
for those using exclusively DTDs, these features may be a deciding point for
the choice of attributes.
Because
attributes are nonstructural (that is, they are merely name/value pairs), if
you need further internal structure, the use of elements will be the logical
choice.
If
you are producing an application that is keyed on the name of elements, you
should choose elements as the source of information. However, if that
informa-tion is mainly in empty elements, using attributes can be equally
useful and more simple.
Attributes
can simplify the level of XML element nesting but can complicate document
processing.
Various
technologies are keyed on the element name rather than the attribute name or
value. For this reason, using either elements or attributes may be the right approach.
If
an item needs to occur multiple times, only elements can be used because
attributes are restricted to appearing once within an element.
In
general, elements are logical, structural units of information that represent
objects of information. These objects can either contain textual information or
subelements. However, attributes represent the characteristics of this
informa-tion and therefore can only contain textual information. So, elements
represent objects, whereas attributes represent the properties of those
objects. Therefore, elements should be used for information chunks that are
considered to be informational objects that can be related in a parent/child
relationship, whereas attributes should be used to represent any information
that describes the objects in context.
In
any case, neither approach is right or wrong. The use of elements or
attrib-utes is a choice that a designer needs to make upon implementation,
taking into consideration all the benefits and advantages of each approach.
Entity
References
There
are times when we want to introduce special characters or make use of content
that is constantly repeated without having to enter it multiple times. This is
the role of the XML entity. Entities provide a means to indicate to XML-processing
applications that a special text string is to follow that will be replaced with
a different literal value. Entities can solve some otherwise intractable
problems. For example, how do we insert a greater-than or less-than sign in our
text? XML processors would interpret those characters as parts of an XML tag,
which may not be our desired result. As such, the entity gives us a way to
provide a character sequence that will be replaced with these otherwise invalid
characters.
Each entity has a unique name
that is defined as part of an entity declaration in a DTD or XML Schema.
Entities are used by simply referring to them by name. Entity references are
delimited by an ampersand at the beginning and a semicolon at the ending. The
con-tent contained between the delimiters is the entity that will be replaced.
For example, the < entity inserts the less-than sign (<) into a document. Elements can be encoded so they aren’t processed or
replaced by their entity equivalents in order to be used for dis-play or
encoding within other element values. For example, the string <element> can be encoded in an XML
document as <element>, and it therefore will not be processed.
Listing 2.6 shows a number of sample entity references.
LISTING 2.6 Sample
Entity References
<description>The
following says that 8 is greater than 5</description>
<equation>4 >
5</equation>
<prescription>The Rx
prescription symbol is ℞
which is the same as
℞</prescription>
Entities can also be used to
refer to often repeated or varying text as well as to include the content of
external files. For example, an entity &legal; can be replaced with an organization’s legal
disclaimer, consisting of any XML text that is included in the DTD or read from
a file.
There are internal and
external entities, and they both can be general or parameter enti-ties.
Internal entities are defined and used within the context of a document,
whereas external entities are defined in a source that is accessible via a URI.
Internal entities are largely simple string replacements, whereas external
entities can consist of entire XML documents or non-XML text, such as binary
files. When using an external entity, you must define the type of the file.
External entities that refer to these files must declare that the data they
contain is not XML by using a notation. Parameter entities are entities that
are declared and used within the context of a DTD or schema. They allow users
to create replacement text that can be used multiple times to modularize the creation
of valid doc-uments. Parameter entities can be either internal or external, but
they cannot refer to non-XML data because you can’t have a parameter entity
with a notation.
Another special form of
entity is the character reference, which is used to insert arbitrary Unicode
characters into an XML document. This allows international characters to be
entered even if they can’t be typed directly on a keyboard. Character entities
use decimal or hexadecimal references to describe their Unicode data values.
For example, ℞ and ℞ both encode the “Rx” character, also known as character number U+211E in Unicode.
Comments
One of the key benefits of
XML is that humans can read it. A side effect of this feature is that there is
a necessity to provide documentation around XML content that describes the
intent or context of a given XML markup. Comments are quite simple to include
in a document. The character sequence <!-- begins a comment and --> ends the comment. Between
these two delimiters, any text at all can be written, including valid XML
markup. The only restriction is that the comment delimiters cannot be used;
neither can the literal string --. Comments can be placed anywhere in a document and are not
con-sidered to be part of the textual content of an XML document. As a result,
XML proces-sors are not required to pass comments along to an application. An
example of a comment is shown in Listing 2.7.

Processing
Instructions
Processing instructions (PIs)
perform a similar function as comments in that they are not a textual part of
an XML document but provide information to applications as to how the content
should be processed. Unlike comments, XML processors are required to pass along
PIs. Processing instructions have the following form:
<?instruction options?>
The instruction name, called
the PI target, is a special
identifier that the processing application is intended to understand. Any
following information can be optionally speci-fied so that the application is
able to understand the context or further requirements of the PI. PI names can
be formally declared as notations (a structure for sending such information).
The only restriction is that PI names may not start with xml, which is reserved for the
core XML standards. Listing 2.8 shows a sample processing instruction.
LISTING 2.8 Example
of a Processing Instruction
<?send-message “process
complete”?>
Marked
CDATA Sections
Some
documents will contain a large number of characters and text that an XML
processor should ignore and pass to an application. These are known as
character data (or CDATA) sec-tions. Within an XML document, a CDATA section
instructs the parser to ignore all markup characters except the end of the CDATA markup
instruction. This allows for a section of XML code to be “escaped” so that it
doesn’t inadvertently disrupt XML processing.
CDATA sections follow this general
form:
<![CDATA[content]]>
In the content section, any
characters can be included, with the necessary exception of the character string
]]>. All content contained in
the CDATA section is passed directly
to the application without interpretation. This means that elements, entity
references, com-ments, and processing instructions are all ignored and passed
as string literals to process-ing applications. CDATA instructions must exist in the context of XML
elements and not as standalone entities. Listing 2.9 shows sample CDATA information.
LISTING 2.9 A Sample CDATA Section
<object_code>
<![CDATA[
function master(poltice integer)
{
if poltice<=3 then {
intMaster=poltice+IntToString(FindElement(“<chicken>”));
}
}
]]> </object_code>
Document
Type Definitions
Document Type Definitions
(DTDs) provide a means for defining what XML markup can occur in an XML
document. Basically, the DTD provides a mechanism to guarantee that a given XML
document complies with a well-defined set of rules for document structure and
content. These rules provide a framework for guaranteeing the “validity” of a
document. DTDs and the more recent XML Schema are the means for defining the
validity constraints on XML documents. Each of these are covered in great
detail in later chapters of this book, but for now it is important to recognize
that DTDs represent a spe-cific form of XML text that is allowable in an XML
document.
XML
Content
Of course, the value of XML
is greatly enhanced by the presence of content within the elements. The content
between XML elements is where most of the value lies in an XML document. In
fact, that is almost exclusively where all the variable content lies. XML
elements are usually well defined and strict in their application. When a DTD
or XML Schema is used, users can’t change these portions of the document.
Therefore, the informational content that the metadata describes is precisely
where the variable data resides. Of course, it then behooves XML to be as
widely lenient about XML content as possible.
In fact, XML content can
consist of any data at all, including binary data, as long as it doesn’t
violate rules that would confuse the content with valid XML metadata
instruc-tions. This means that XML metadata delimiters must be escaped if they
are not to be processed, and entities should be referenced if they are needed.
XML content can contain any characters, including any valid Unicode and
international characters. The content can be as long as necessary and contain
hundreds of megabytes of textual infor-mation, if required. Of course, the size
of the content is an implementation decision.
Related Topics