Chapter: XML and Web Services : Building XML-Based Applications : Parsing XML Using SAX
Working with SAX
Working with SAX
In this section, we will explore a series of examples. The examples will
exercise different parts of the SAX API to illustrate how they are used and
demonstrate how they work.
Walking Through an XML Document
Let’s look at a simple example in which we read an XML document from
disk and print out some of the contents. This example will help you understand
how the SAX API works. In this example, we will print out just the element
names and the text between the elements. The source code for SAXDemo.java is shown in Listing 8.1.
LISTING 8.1 SAXDemo.java
package com.madhu.xml;
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class SAXDemo extends
DefaultHandler { public void startDocument() {
System.out.println(“***Start
of Document***”);
}
public void endDocument() {
System.out.println(“***End of Document***”);
}
public void startElement(String
uri, String localName, String qName, Attributes attributes) {
System.out.print(“<” + qName); int n = attributes.getLength(); for
(int i=0; i<n; i+=1) {
System.out.print(“ “ +
attributes.getQName(i) + “=’” + attributes.getValue(i) + “‘“);
}
System.out.println(“>”);
}
public void characters(char[] ch,
int start, int length) { System.out.println(new String(ch, start,
length).trim());
}
public void endElement(String
namespaceURI, String localName, String qName) throws SAXException {
System.out.println(“</” + qName
+ “>”);
}
public static void main(String
args[]) throws Exception { if (args.length != 1) {
System.err.println(“Usage: java SAXDemo
<xml-file>”); System.exit(1);
}
SAXDemo handler =
new SAXDemo();
SAXParserFactory factory =
SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse(new File(args[0]), handler);
}
}
The first thing we need to do is import the necessary packages. For this
example, we will need the org.xml.sax package and the org.xml.helpers package. In addition, we have imported the javax.xml.parsers package. This package is part of
JAXP, defined by the Java Community Process (JCP). Although this package is
outside the scope of SAX proper,
it is helpful in locating and creating a default SAX parser. It is not
absolutely required, as you will see in later examples, but it shows one of the
recommended ways of creating a SAX parser. This package is shipped with Xerces
as well as JAXP from Sun Microsystems.
Our class extends DefaultHandler in order to capture events. DefaultHandler is a con-venience adapter class defined in org.xml.sax.helpers. It implements four interfaces:
EntityResolver,
DTDHandler,
ContentHandler, and ErrorHandler. We could have implemented ContentHandler alone, but then we would be
required to fill in all the methods of ContentHandler, even if we were not interested in all the events.
DefaultHandler defines empty stub methods for
all these events. That way, we are free to fill in only the methods we are interested in. All other events are
discarded.
In order to register our handler, we can create a SAXParser instance and call its parse() method with a file and handler
instance. The code to do this is located in the main() method of the example. This uses a factory class defined in JAXP. In
later examples, we will see other ways of creating a parser and registering
handlers.
In the example, we have defined five methods: startDocument(), endDocument(), startElement(), characters(), and endElement(). These methods will be called in response to related events, and they are defined in the ContentHandler interface, along with a number
of others. Once the parse() method is called, our methods will be called in response to events
until the end of input is reached or an error occurs. Descriptions of all the
methods defined in ContentHandler are provided in Table 8.4.
TABLE 8.4 The ContentHandler Methods
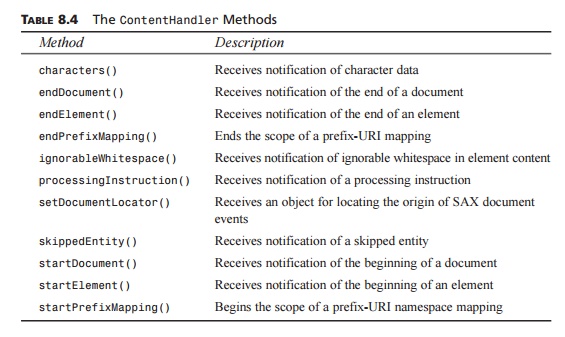
Method : Description
characters() :
Receives notification of character data
endDocument() :
Receives notification of the end of a document
endElement() :
Receives notification of the end of an element
endPrefixMapping() :
Ends the scope of a prefix-URI mapping
ignorableWhitespace()
: Receives notification of ignorable whitespace in element content
processingInstruction()
: Receives notification of a processing instruction
setDocumentLocator() :
Receives an object for locating the origin of SAX document events
skippedEntity() :
Receives notification of a skipped entity
startDocument() :
Receives notification of the beginning of a document
startElement() :
Receives notification of the beginning of an element
startPrefixMapping() :
Begins the scope of a prefix-URI namespace mapping
The startElement() and endElement() methods accept several arguments: namespace URI, local name, qualified
name, and attributes. The first three are defined depending on whether
namespaces are used. The characters() method provides an array of characters and locations where valid
characters are found in the array. This is done for performance reasons.
Typically, a String can be easily created, as shown earlier.
A sample XML document, library.xml, is used for testing and is
shown in Listing 8.2.
LISTING 8.2 library.xml—Sample
XML Document
<?xml version=”1.0” encoding=”UTF-8”?>
<!DOCTYPE library SYSTEM “library.dtd”>
<library>
<fiction>
<book author=”Herman Melville”>Moby Dick</book>
<book author=”Zane Grey”>The Last Trail</book>
</fiction>
<biography>
<book author=”William Manchester”>
The Last Lion, Winston Spencer
Churchill </book>
</biography>
<science>
<book author=”Hecht,
Zajac”>Optics</book>
</science>
</library>
To execute SAXDemo, you can enter the following
command:
java com.madhu.xml.SAXDemo library.xml
This command specifies that the input file, library.xml, is located in the current
direc-tory. The output of SAXDemo is shown in Listing 8.3. It shows beginning and end of docu-ment
events, elements, and text. Note that formatting such as tabs and spaces is
lost. This happens because text is trimmed of whitespace by calling the trim() method of the
String class.
LISTING 8.3 Output from SAXDemo
***Start of Document*** <library>
<fiction>
<book author=’Herman Melville’> Moby Dick
</book>
<book author=’Zane Grey’> The Last Trail
</book>
</fiction>
<biography>
<book author=’William Manchester’>
The Last Lion, Winston Spencer Churchill </book>
</biography>
<science>
<book author=’Hecht, Zajac’> Optics
</book>
</science>
</library>
***End of Document***
Validation
SAX parsers come in two varieties: validating and nonvalidating.
Validating parsers can determine whether an XML document is valid based on a
Document Type Definition (DTD) or Schema.
The SAX parser shipped with Apache Xerces is a validating parser. In
order to use vali-dation, you must turn it on by setting the validation feature
to true. If you
attempt to turn on validation with a nonvalidating parser, a SAXNotSupportedException will be thrown. If the parser
does not recognize the feature, a SAXNotRecognizedException will be thrown. This helps in determining whether you mistyped the
feature name.
In the following example, we will write a simple program to validate an
XML document. The document is expected to include a reference to its DTD, and
the DTD is expected to be accessible. In this example, the DTD will be located
on the local hard drive in the same directory as the document itself. SAX
parsers are smart enough to understand URLs, so if an HTTP URL is specified,
the parser will go out to the network to get the DTD. Later, you will see how
this automatic resolution of DTDs can be controlled in our code. The source
code for SAXValidator.java is shown in Listing 8.4.
LISTING 8.4 SAXValidator.java
package com.madhu.xml;
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class SAXValidator
extends DefaultHandler {
private boolean valid; private boolean wellFormed;
public SAXValidator() { valid =
true; wellFormed = true;
}
public void startDocument() {
System.out.println(“***Start of Document***”);
}
public void endDocument() {
System.out.println(“***End of Document***”);
}
public void error(SAXParseException
e) { valid = false;
}
public void
fatalError(SAXParseException e) { wellFormed = false;
}
public void
warning(SAXParseException e) { valid = false;
}
public boolean isValid() { return
valid;
}
public boolean isWellFormed() {
return wellFormed;
}
public static void main(String
args[]) throws Exception { if (args.length != 1) {
System.err.println(“Usage: java SAXValidate
<xml-file>”); System.exit(1);
}
XMLReader parser =
XMLReaderFactory.createXMLReader( “org.apache.xerces.parsers.SAXParser”);
parser.setFeature(“http://xml.org/sax/features/validation”, true);
SAXValidator handler = new SAXValidator();
parser.setContentHandler(handler);
parser.setErrorHandler(handler);
parser.parse(new InputSource(new FileReader(args[0]))); if (!handler.isWellFormed())
{
System.out.println(“Document is
NOT well formed.”);
}
if (!handler.isValid()) {
System.out.println(“Document is NOT valid.”);
}
if (handler.isWellFormed()
&& handler.isValid()) { System.out.println(“Document is well formed and
valid.”);
}
}
}
In this example, we will avoid the use of JAXP classes in order to
create a parser. Instead, we will use XMLReaderFactory. This is needed to set features and properties. In order to validate
the document, we will enable validation by setting the feature http://xml.org/sax/features/validation to true. We will register an error
handler in
addition to a ContentHandler. Remember that DefaultHandler implements
ErrorHandler.
ErrorHandler contains three methods that can
be used to determine whether a document is well formed and valid. A summary of the ErrorHandler methods is provided in Table 8.5.
TABLE 8.5 The ErrorHandler Methods
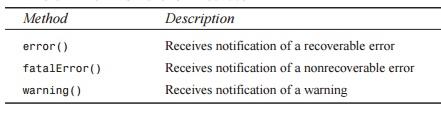
Method : Description
error() : Receives
notification of a recoverable error
fatalError() :
Receives notification of a nonrecoverable error
warning() : Receives
notification of a warning
Either error() or warning() will be called if the document is well formed but not valid (that is,
it violates the rules of the DTD), and fatalError() will be called if the docu-ment is not well formed. In this example, we
will set flags for different types of errors and report the results when
parsing is finished.
We will use an invalid XML document, invalid-library.xml, for testing. The docu-ment and referenced DTD, library.dtd, is shown in Listings 8.5 and
8.6, respectively. If you look closely, you will notice what is wrong with the
document. If you can’t find the problem, it will become clear in the next
example.
LISTING 8.5 invalid-library.xml—Invalid XML Document
<?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE library SYSTEM
“library.dtd”> <library>
<fictions>
<book author=”Herman Melville”>Moby Dick</book>
<book author=”Zane Grey”>The Last Trail</book>
</fictions>
<biography>
<book author=”William Manchester”>
The Last Lion, Winston Spencer
Churchill </book>
</biography>
<science>
<book author=”Hecht,
Zajac”>Optics</book>
</science>
</library>
LISTING 8.6 library.dtd—DTD
File
<?xml version=”1.0” encoding=”US-ASCII”?>
<!ELEMENT library (fiction|biography|science)*>
<!ELEMENT fiction (book)+>
<!ELEMENT biography (book)+>
<!ELEMENT science (book)+>
<!ELEMENT book (#PCDATA)>
<!ATTLIST book author
CDATA #REQUIRED>
The output is shown in Listing 8.7.
LISTING 8.7 Output from SAXValidator
***Start of Document***
***End of Document*** Document is NOT valid.
A number of features are defined in SAX. A detailed list can be found at
http://www.megginson.com/SAX/Java/features.html. Features are enabled by calling the setFeature() method with the feature name and the value true. Features are dis-abled with the
value false. Here is a brief summary of SAX 2.0 features:
http://xml.org/sax/features/namespaces
true:
Performs namespace processing.
• http://xml.org/sax/features/namespace-prefixes
true: Reports
the original prefixed names and attributes used for namespace decla-rations.
http://xml.org/sax/features/string-interning
true: All
element names, prefixes, attribute names, namespace URIs, and local names are internalized using java.lang.String.intern.
http://xml.org/sax/features/validation
true: Reports
all validation errors (implies external-general-entities and
external-parameter-entities).
http://xml.org/sax/features/external-general-entities
true: Includes all external general (text) entities.
http://xml.org/sax/features/external-parameter-entities
true: Includes all external parameter
entities, including the external DTD subset.
Handling Errors
Did you figure out what was wrong with the XML document in the last
example? Don’t worry if you didn’t. We’ll write a program to tell us what’s
wrong. The previous example told us the document was not valid, but it didn’t
tell us where or what was not valid. The Locator interface can give us the parse position within a ContentHandler method. The position information includes
line number and column number. It is important to note that the Locator object should not be used in any other methods,
including ErrorHandler methods. Fortunately, ErrorHandler methods supply a SAXParseException object that can also give us position information.
The source code for SAXErrors.java is shown in Listing 8.8.
LISTING 8.8 SAXErrors.java
package com.madhu.xml;
import java.io.*; import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class SAXErrors extends
DefaultHandler { private Locator locator;
public void startDocument() { System.out.println(“***Start of
Document***”);
}
public void endDocument() {
System.out.println(“***End of Document***”);
}
public void
setDocumentLocator(Locator inLocator) { System.out.println(“***Got
Locator***”); locator = inLocator;
int line =
locator.getLineNumber();
int column = locator.getColumnNumber(); String publicID =
locator.getPublicId(); String systemID = locator.getSystemId();
System.out.println(“Line “ + line + “, column “ + column); if (publicID
!= null) {
System.out.println(“Public ID
“ + publicID);
}
if (systemID != null) {
System.out.println(“System ID “ + systemID);
}
}
public void
printLocation(SAXParseException e) { int line = e.getLineNumber();
int column = e.getColumnNumber(); String publicID = e.getPublicId();
String systemID = e.getSystemId();
System.out.println(“Line “ + line + “, column “ + column); if (publicID
!= null) {
System.out.println(“Public ID
“ + publicID);
}
if (systemID != null) {
System.out.println(“System ID “ + systemID);
}
}
public void
error(SAXParseException e) { printLocation(e);
System.out.println(“Recoverable error: “ + e.getMessage()); Exception ex
= e.getException();
if (ex !=
null) {
System.out.println(“Embedded
exception: “ +
ex.getMessage());
}
}
public void fatalError(SAXParseException e) { printLocation(e);
System.out.println(“Non-recoverable error: “ + e.getMessage());
Exception ex = e.getException();
if (ex !=
null) {
System.out.println(“Embedded exception:
“ + ex.getMessage());
}
}
public void
warning(SAXParseException e) { printLocation(e);
System.out.println(“Warning: “ + e.getMessage()); Exception ex =
e.getException();
if (ex !=
null) {
System.out.println(“Embedded exception:
“ + ex.getMessage());
}
}
public static void main(String
args[]) throws Exception { if (args.length != 1) {
System.err.println(“Usage: java SAXErrors
<xml-file>”); System.exit(1);
}
XMLReader parser =
XMLReaderFactory.createXMLReader( “org.apache.xerces.parsers.SAXParser”);
parser.setFeature(“http://xml.org/sax/features/validation”, true);
SAXErrors handler = new SAXErrors(); parser.setContentHandler(handler);
parser.setErrorHandler(handler);
parser.parse(new InputSource(new FileReader(args[0])));
}
}
This example is very similar to the previous example, but the ContentHandler method setDocumentLocator() is added to obtain a Locator instance. Detailed information is printed in the error methods.
We will use the same invalid document and DTD from the previous example
for testing. The output is shown in Listing 8.9.
LISTING 8.9 Output from SAXErrors
***Got Locator*** Line 1, column 1
***Start of Document***
Line 4, column
12
Recoverable error: Element type “fictions” must be declared. Line 16,
column 11
Recoverable error: The content of element type “library” must match
[ic:ccc]”(fiction|biography|science)*”.
***End of Document***
As expected, a validation error occurs at line 4. The fictions tag should be fiction. Another error is encountered at
the ending library tag. This is caused by the same error.
Entity References
SAX parsers will resolve entity references automatically. However, there
are cases when you might want to resolve an entity reference yourself. In the
following example, we will define an entity for hardcover books. It will be
referenced as &hc; and defined in our DTD. If we use an HTTP URL to define the entity, the
SAX parser will go out to the network to resolve it. What we want to do here is
resolve the entity using a local file. We can accomplish this using an EntityResolver. The source code for SAXEntity.java is shown in Listing 8.10.
LISTING 8.10 SAXEntity.java
package com.madhu.xml;
import java.io.*; import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class SAXEntity extends
DefaultHandler { public SAXEntity() {
}
public void startDocument() {
System.out.println(“***Start of Document***”);
}
public void endDocument() {
System.out.println(“***End of Document***”);
}
public void startElement(String uri, String localName, String qName,
Attributes attributes) {
System.out.print(“<” +
qName);
int n = attributes.getLength(); for (int i=0; i<n; i+=1) {
System.out.print(“ “ +
attributes.getQName(i) + “=’” + attributes.getValue(i) + “‘“);
}
System.out.println(“>”);
}
public void characters(char[] ch,
int start, int length) { System.out.println(new String(ch, start,
length).trim());
}
public void endElement(String
namespaceURI, String localName, String qName) throws SAXException {
System.out.println(“</” + qName
+ “>”);
}
public InputSource
resolveEntity(String publicId, String systemId) { try {
if
(systemId.equals(“http://www.madhu.com/xml/hardcover.txt”)) { return new
InputSource(
new
FileReader(“hardcover.txt”));
}
} catch (IOException
e) {
}
return null; //
for default behavior
}
public static void main(String
args[]) throws Exception { if (args.length != 1) {
System.err.println(“Usage: java SAXEntity
<xml-file>”); System.exit(1);
}
XMLReader parser =
XMLReaderFactory.createXMLReader( “org.apache.xerces.parsers.SAXParser”);
parser.setFeature(“http://xml.org/sax/features/validation”, true);
SAXEntity handler = new SAXEntity(); parser.setContentHandler(handler);
parser.setEntityResolver(handler);
parser.parse(new
InputSource(new
FileReader(args[0])));
}
}
EntityResolver is also implemented by DefaultHandler.
EntityResolver contains only one method, resolveEntity(), which will be called with the
system ID and public ID, depending on how the entity is defined. Once we
determine what the entity is, we must return an InputSource pointing to where the entity resides.
InputSource is a class defined in package org.xml.sax.
InputSource can be created given an InputStream or Reader. If an entity with our ID is
referenced, we will return an InputSource pointing to a local file named
hardcover.txt. In all other cases, null is returned, meaning use the default
behavior and resolve all other entities automatically.
We will use an XML document that uses the hardcover entity, entity-ref.xml, for test-ing. The document and referenced DTD, library.dtd, is shown in Listings 8.11 and
8.12, respectively.
LISTING 8.11 entity-ref.xml—XML Document with Entity Reference
<?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE library SYSTEM
“library.dtd”> <library>
<fiction>
<book author=”Herman Melville”>Moby Dick</book> <book
author=”Zane Grey”>The Last Trail</book>
</fiction>
<biography>
<book author=”William Manchester”>
The Last Lion, Winston Spencer
Churchill &hc; </book>
</biography>
<science>
<book author=”Hecht,
Zajac”>Optics &hc;</book> </science>
</library>
LISTING 8.12 library.dtd—DTD
with Entity Reference Definition
<?xml version=”1.0” encoding=”US-ASCII”?>
<!ELEMENT library (fiction|biography|science)*>
<!ELEMENT fiction (book)+>
<!ELEMENT biography (book)+>
<!ELEMENT science (book)+>
<!ELEMENT book (#PCDATA)>
<!ATTLIST book author
CDATA #REQUIRED>
<!ENTITY hc SYSTEM
“http://www.madhu.com/xml/hardcover.txt”>
The output is shown in Listing 8.13.
***Start of Document*** <library>
<fiction>
<book author=’Herman Melville’> Moby Dick
</book>
<book author=’Zane Grey’> The Last Trail
</book>
</fiction>
<biography>
<book author=’William Manchester’>
The Last Lion, Winston Spencer Churchill (hardcover)
</book>
</biography>
<science>
<book author=’Hecht, Zajac’> Optics
(hardcover)
</book>
</science>
</library>
***End of Document***
Parsers can skip entities if they are nonvalidating or if entity
features are set to false. In either case, the skippedEntity() method defined in ContentHandler will be called with the name of the entity.
Lexical Events
You saw earlier how to capture basic events, such as elements and
characters, but what about comments, CDATA, and DTD references? We can receive these events as well using an
extension interface called LexicalHandler. LexicalHandler is part of the org.xml.sax.ext package, which is not necessarily supported by all SAX implementa-tions.
Xerces, of course, provides support for the extension package.
The source code for SAXLexical.java is shown in Listing 8.14.
LISTING 8.14 SAXLexical.java
package com.madhu.xml;
import java.io.*; import org.xml.sax.*;
import org.xml.sax.ext.*; import org.xml.sax.helpers.*;
public class SAXLexical extends
DefaultHandler implements LexicalHandler { public SAXLexical() {
}
public void startDocument() {
System.out.println(“***Start of Document***”);
}
public void endDocument() {
System.out.println(“***End of Document***”);
}
public void startElement(String
uri, String localName, String qName, Attributes attributes) {
System.out.print(“<” + qName); int n = attributes.getLength(); for
(int i=0; i<n; i+=1) {
System.out.print(“ “ +
attributes.getQName(i) + “=’” + attributes.getValue(i) + “‘“);
}
System.out.println(“>”);
}
public void characters(char[] ch,
int start, int length) { System.out.println(new String(ch, start,
length).trim());
}
public void endElement(String
namespaceURI, String localName, String qName) throws SAXException {
System.out.println(“</” + qName
+ “>”);
}
public void startDTD(String name,
String publicId, String systemId) throws SAXException {
System.out.print(“*** Start DTD, name “ + name); if (publicId != null) {
System.out.print(“
PUBLIC “ +
publicId);
}
if (systemId !=
null) {
System.out.print(“
SYSTEM “ +
systemId);
}
System.out.println(“ ***”);
}
public void endDTD() throws
SAXException { System.out.println(“*** End DTD ***”);
}
public void startEntity(String
name) throws SAXException { System.out.println(“*** Start Entity “ + name + “
***”);
}
public void endEntity(String
name) throws SAXException { System.out.println(“*** End Entity “ + name + “
***”);
}
public void startCDATA() throws
SAXException { System.out.println(“*** Start CDATA ***”);
}
public void endCDATA() throws
SAXException { System.out.println(“*** End CDATA ***”);
}
public void comment(char[] ch,
int start, int length) throws SAXException {
System.out.println(“<!— “ +
new
String(ch, start, length)
+ “ —>”);
}
public static void main(String
args[]) throws Exception { if (args.length != 1) {
System.err.println(“Usage: java SAXLexical
<xml-file>”); System.exit(1);
}
XMLReader parser =
XMLReaderFactory.createXMLReader( “org.apache.xerces.parsers.SAXParser”);
parser.setFeature(“http://xml.org/sax/features/validation”, true);
SAXLexical handler = new SAXLexical();
parser.setContentHandler(handler);
parser.setProperty(“http://xml.org/sax/properties/lexical-handler”,
handler);
parser.parse(new
InputSource(new
FileReader(args[0])));
}
}
Notice that we are explicitly implementing LexicalHandler. This is necessary because DefaultHandler does not implement LexicalHandler. We must fill in all methods of LexicalHandler whether we are interested in them
or not. That’s just the way interfaces work. The methods for LexicalHandler are listed in Table 8.6.
TABLE 8.6 The LexicalHandler Methods
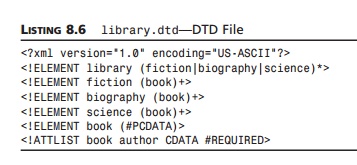
Method : Description
comment() : Reports an
XML comment anywhere in the document
endCDATA() : Reports
the end of a CDATA section
endDTD() : Reports the
end of DTD declarations
endEntity() : Reports
the end of an entity
startCDATA() : Reports
the start of a CDATA section
startDTD() : Reports
the start of DTD declarations, if any
startEntity() :
Reports the beginning of some internal and external XML entities
In the main() method, notice that in order to register a lexical
handler, we must call setProperty(). This is different from the standard
handlers because LexicalHandler is an extension. If a method in the standard
API includes a reference to LexicalHandler, it will not
compile unless the extension package is included. The setProperty() method accepts a String property name and an Object property. This avoids the direct
reference to LexicalHandler in the API. The property, in this case, is the handler itself.
A sample XML document, comment.xml, is used for testing and is shown in Listing 8.15.
LISTING 8.15 comment.xml—Sample
XML Document
<?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE library SYSTEM
“library.dtd”>
<!— A short
list of books
in a library
—>
<library>
<fiction>
<book author=”Herman Melville”>Moby Dick</book> <book
author=”Zane Grey”>The Last Trail</book>
</fiction>
<biography>
<book author=”William Manchester”>
The Last Lion, Winston Spencer
Churchill </book>
</biography>
<science>
<book author=”Hecht,
Zajac”>Optics</book> </science>
</library>
The output is shown in Listing 8.16.
LISTING 8.16 Output from SAXLexical
***Start of Document***
Start DTD,
name library SYSTEM
library.dtd ***
Start Entity
[dtd] ***
End Entity
[dtd] ***
End DTD
***
<!— A short list of books in a library —> <library>
<fiction>
<book author=’Herman Melville’> Moby Dick
</book>
<book author=’Zane Grey’> The Last Trail
</book>
</fiction>
<biography>
<book author=’William Manchester’>
The Last Lion, Winston Spencer Churchill </book>
</biography>
<science>
<book author=’Hecht, Zajac’> Optics
</book>
</science>
</library>
***End
of Document***
Notice the DTD and entity references in the beginning and the comment
immediately following the DTD events.
Historically,
the census was recorded on paper. In the late 1800s, it was pro-jected that the
population of the U.S. had grown to such a point that more than 10 years would
have been required to process and tabulate all the data! As soon as the census
data was tabulated, it would have become obsolete and a new census would be
required. The problem was solved by inventor Herman Hollerith, who devised a
scheme of punching holes in paper that could be tabu-lated quickly using a
machine. This was the first punch-card machine. Hollerith founded the
Tabulating Machine Company in 1896, which, after mergers and acquisitions, grew
into International Business Machines (IBM).
Because the
census is conducted by the federal government and paid for by public funds, the
information is available to the public free of charge. In fact, it is available
on the U.S. Census Web site (probably stored in an IBM database!). The problem
is that the data is prepared for human consumption in HTML, which is not easily
digested by databases.
The census has
a site dedicated to state and county quick facts. It can be found at http://quickfacts.census.gov/qfd/index.html. This site contains just a
small portion of the data compiled by the Census Bureau, but it’s still a lot
of data! It would be useful to grab this data and reformat it so that it can be
bulk-loaded into a database. Once the data is in a database, we can perform
inter-esting queries on people, businesses, and geography.
This is where
SAX fits in. What we need to do is write a program that parses these Web pages
and pulls out the important information. There are, in fact, hundreds of pages
of information, because there is data on every state and every county in every
state. For our case study, we will just collect the data for each state. The
program can easily be extended to collect data for each county as well.
As you are
probably aware, common HTML is usually not well formed. So it is not possible
to use standard SAX parsers such as Xerces. Fortunately, Anders Kristensen has
developed HTML Enabled XML Parser (HEX) for just this purpose. HEX is a SAX 1.0
parser that accepts HTML and tolerates all its problems. HEX can be found at http://www-uk.hpl.hp.com/people/sth/java/hex.html.
The Census Quick Facts Web
pages are organized in a hierarchy. The home page contains links to state
pages, and each state page contains links to county pages. What we need to do is
first parse the home page, grab the links for the state pages, and then parse
each state page. The home page and the state pages are formatted differently,
so there are different content handlers for each. The source code for the main
class, Spider.java, is shown in Listing 8.
17.
LISTING 8.17 Spider.java
package
com.madhu.spider;
import java.io.*; import java.util.*; import
java.net.*;
import org.xml.sax.*; import hplb.xml.Tokenizer;
public
class Spider {
private int numberOfStates; private PrintWriter
out;
public void process(String
nStates, String outFile) throws Exception {
numberOfStates
= Integer.parseInt(nStates);
out = new PrintWriter(new FileWriter(outFile));
processUSA();
out.close();
}
public void processUSA() throws
Exception { USAHandler usa = new USAHandler(); Tokenizer t = new Tokenizer();
t.setDocumentHandler(usa); t.setErrorHandler(usa);
URL u = new
URL(“http://quickfacts.census.gov/qfd/index.html”); InputStream is =
u.openStream();
t.parse(is);
is.close();
int nStates = numberOfStates; Iterator it =
usa.getStateNames();
while (it.hasNext() &&
nStates— > 0) { String state = (String) it.next();
String url =
“http://quickfacts.census.gov” + usa.getStateURI(state);
processState(state,
url);
}
}
public void processState(String
state, String url) throws Exception {
StateHandler st = new StateHandler(); Tokenizer t =
new Tokenizer(); t.setDocumentHandler(st); t.setErrorHandler(st);
URL u = new URL(url); InputStream is =
u.openStream(); t.parse(is);
is.close();
System.out.println(state); out.print(“\”” + state +
“\””); ArrayList dataList = st.getDataList(); int n = dataList.size();
for
(int i=0; i<n;
i+=1) {
String[] data = (String[]) dataList.get(i);
out.print(“, \”” + data[1] + “\””);
}
out.println();
}
public static void main(String
args[]) throws Exception { if (args.length != 2) {
System.err.println(
“Usage: java Spider <# of
states> <out-file>”); System.exit(1);
}
Spider m = new Spider(); m.process(args[0],
args[1]);
}
}
When compiling
this code, make sure there are no other SAX class libraries in your classpath.
HEX includes classes in the same package as other SAX parsers, so a name
conflict might arise. Make certain that you have not placed Xerces or other SAX
APIs in your java/jre/lib/ext directory, because these
classes are automatically added to your classpath.
The API for HEX is slightly
different from SAX, but the principles are the same. Spider creates
a Tokenizer (similar to
XMLReader)
and registers a handler, USAHandler, for the home page. This
handler grabs the names of each state and the links to each state
page.
Once this is done, a StateHandler is registered and input is accepted from the state Web pages. This is
done for each state Web page. The output is stored in a text file named as a
command-line parameter.
The source code for USAHandler.java is shown in Listing 8.18.
LISTING 8.18 USAHandler.java
package
com.madhu.spider;
import java.io.*; import java.util.*;
import org.xml.sax.*; import hplb.xml.Tokenizer;
public class USAHandler extends
HandlerBase { private HashMap linkMap;
private String actionURL; private String
stateParamName; private boolean grabText; private String statePage; private
String optionText; private String url;
public
USAHandler() {
linkMap = new HashMap(75); grabText = false;
}
public void startElement(String
name, AttributeMap atts) { if (name.equalsIgnoreCase(“form”)) {
actionURL = atts.getValue(“ACTION”); return;
}
if
(name.equalsIgnoreCase(“SELECT”)) { stateParamName = atts.getValue(“NAME”);
url = actionURL + “?” + stateParamName + “=”;
return;
}
if
(name.equalsIgnoreCase(“OPTION”)) { statePage = atts.getValue(“value”); if
(statePage == null) {
statePage
= atts.getValue(“VALUE”);
}
grabText = true; return;
}
}
public void characters(char ch[],
int start, int length) throws Exception {
if
(grabText) {
String text = new String(ch, start, length); text =
text.replace(‘\n’, ‘ ‘);
text = text.replace(‘\r’, ‘ ‘); optionText =
text.trim(); linkMap.put(optionText, statePage);
}
}
public void endElement(String
name) { grabText = false;
}
public void warning(String
message, String systemID, int line, int column) throws Exception {
//
ignore errors
}
public Iterator getStateNames() {
return linkMap.keySet().iterator();
}
public
String getStateURI(String state)
{
String htmlPage = (String) linkMap.get(state); if
(htmlPage == null) {
return null;
}
return
url + htmlPage;
}
}
The home page
contains an HTML form with a drop-down list in a form for each state. USAHandler
grabs the ACTION attribute from the form,
which is needed to get the state pages. It also grabs the state names and
values from the drop-down list.
StateHandler does the real work of collecting the raw data. Each state Web page contains
three tables with information on people, businesses, and geography. StateHandler grabs the data in each of these tables and puts it all in an array list. Spider takes
this list and pulls out the state data, formats it, and writes it out to a file.
The source code for StateHandler.java is shown in listing 8.19.
package com.madhu.spider;
import java.io.*; import java.util.*;
import org.xml.sax.*; import hplb.xml.Tokenizer;
public class StateHandler extends
HandlerBase { public static final int MAX_COLUMNS = 3;
private HashMap linkMap; private ArrayList
dataList;
private String actionURL; private String
countyParamName; private String countyPage; private String optionText; private
String url;
private boolean grabOptionText; private boolean
grabTable; private String[] row;
private
int columnIndex;
public StateHandler() { linkMap =
new HashMap(75);
dataList = new ArrayList(100); grabOptionText =
false;
row = new String[MAX_COLUMNS]; columnIndex = -1;
grabTable
= false;
}
public void startElement(String
name, AttributeMap atts) { if (name.equalsIgnoreCase(“form”)) {
actionURL = atts.getValue(“ACTION”); return;
}
if
(name.equalsIgnoreCase(“SELECT”)) { countyParamName = atts.getValue(“NAME”);
url = actionURL + “?” + countyParamName + “=”;
return;
}
if (name.equalsIgnoreCase(“OPTION”)) { countyPage =
atts.getValue(“value”); if (countyPage == null) {
countyPage
= atts.getValue(“VALUE”);
}
grabOptionText = true; return;
}
if (grabTable &&
name.equalsIgnoreCase(“TR”)) { columnIndex = 0;
}
}
public void characters(char ch[],
int start, int length) throws Exception {
String text = new String(ch, start, length); text =
text.replace(‘\n’, ‘ ‘);
text = text.replace(‘\r’, ‘ ‘); text = text.trim();
if (text.length() == 0) { return;
}
if (grabOptionText) {
grabOptionText = false; optionText = text;
linkMap.put(optionText, countyPage);
}
if (text.equals(“People
QuickFacts”) || text.equals(“Business QuickFacts”) || text.equals(“Geography
QuickFacts”)) {
grabTable
= true;
}
if (columnIndex >= 0
&& columnIndex < MAX_COLUMNS) { row[columnIndex++] = text;
}
if (columnIndex == MAX_COLUMNS) {
columnIndex = -1; dataList.add(row);
row = new
String[MAX_COLUMNS];
}
}
public void endElement(String
name) { grabOptionText = false;
if (name.equalsIgnoreCase(“table”))
{ grabTable = false;
}
}
public void warning(String
message, String systemID, int line, int column) throws Exception {
//
ignore errors
}
public Iterator getCountyNames()
{ return linkMap.keySet().iterator();
}
public
String getCountyURI(String state)
{
String htmlPage = (String) linkMap.get(state); if
(htmlPage == null) {
return null;
}
return
url + htmlPage;
}
public ArrayList getDataList() {
return dataList;
}
}
The program will take some
time to run completely, depending on your Internet connection. What comes out
is a file with one row for each state con-taining data on that state. The data
is all quoted, so it can be easily bulk-loaded into most databases.
As mentioned earlier, the
program can be extended to collect information on each county in every state.
This is quite a bit of data, but it will contain a lot of interesting
information on specific regions of the U.S. To collect county informa-tion,
another handler, similar to StateHandler, can be created that parses
data from the county Web pages. Fortunately, StateHandler also grabs the links for
the counties, so a lot of the work is already done.
The output is shown in
Listing 8.20. Note that the output is comma separated, which is acceptable by
any database. Many databases now accept XML as an input format for bulk
loading. XML format is also attractive for further process-ing or reformatting
using XSLT. The program can be easily modified to produce valid XML by changing
the print statements. Making other adjustments, such as
removing percent symbols and commas in large numbers, might be a good idea
also. These modifications are left as an exercise for you, the reader.
“Utah”, “2,233,169”, “29.6%”, “9.4%”, “32.2%”, “8.5%”, “89.2%”, “0.8%”,
“Maryland”, “5,296,486”, “10.8%”, “6.7%”, “25.6%”, “11.3%”, “64.0%”, “New
Mexico”, “1,819,046”, “20.1%”, “7.2%”, “28.0%”, “11.7%”, “66.8%”, “North
Carolina”, “8,049,313”, “21.4%”, “6.7%”, “24.4%”, “12.0%”, “Washington”,
“5,894,121”, “21.1%”, “6.7%”, “25.7%”, “11.2%”, “81.8%”,
Summary
SAX is an easy-to-use API for parsing XML data. It’s available in source
and binary form free of charge. SAX has become one of the most popular tools
for parsing XML due to its ease of use and widespread availability.
Unlike DOM, SAX is an event-based parser. SAX reads XML serially and
generates events when elements, text, comments and other data are found. To use
SAX, you simply extend or implement the relevant handler (DefaultHandler will work in most cases) and
register it. Once this is done, the parser is pointed to an XML source and
parsing can begin.
The event-based parsing scheme used by SAX does not solve all problems.
It is not pos-sible to traverse a document at random or modify a document’s
structure. Even still, SAX solves a large class of XML parsing problems easily
and efficiently.
Related Topics