Chapter: XML and Web Services : The Semantic Web : RDF for Information Owners
The RDF Data Model: Just Enough Graph Theory and The RDF Graph
The
RDF Data Model
The RDF data model is a
graph: a mathematical construct that connects nodes and arcs in tinker toy–like
fashion. Many find the fundamental simplicity of graphs very appealing. In
this section, you will learn just enough graph theory to understand the basic
math-ematical characteristics of the RDF graph. As a developer, you will find
this useful in selecting and tailoring graph algorithms for processing the RDF
graph.
You will see that the RDF
graph is a collection of statements (or triples).
We will look at issues of representing RDF statements in syntax and go through
the construction rules that allow an RDF graph to be created from XML syntax.
We will conclude the chapter by summarizing how XML elements and attributes are
assembled to create a representa-tion of the graph for interchange.
Just
Enough Graph Theory
The one-minute graph theorist
would say that there are only two fundamental graph con-structs:
Nodes
Arcs
Arcs may have labels and may
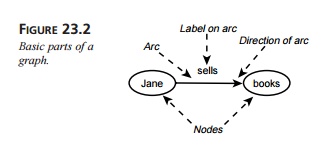
be directed (such as a one-way street). Figure 23.2 shows the basic parts of
graph, where “Jane” and “books” are nodes connected with a directed arc whose
label is “sells.”
A graph data model can be
very powerful. Graph structures are used for many large-scale modeling tasks,
including air traffic control, enterprise resource allocation, and so forth.
Graphs can model both object-oriented and relational database systems, and they
can be formalized mathematically. Therefore, it is possible (or at least should
be possible) to assess the structures of RDF graphs mathematically and prove
that some graphs are “bet-ter” than others, at least according to some formal
criterion. These formal properties are useful for a data model to have, as we
know from the power that relational algebra has given the relational model.
Graph literature is vast.
Mainstream graph theory, accessible to the nonspecialist, seems to focus more
on pleasing symmetries and visual elegance, but “real Web” graphs, such as the
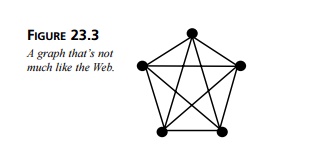
RDF graph, lack those characteristics. Figure 23.3 shows the sort of graph that
seems of interest to academics.
The Web—a set of connections
(arcs) between resources (nodes) that we must model in RDF to create the
Semantic Web—lacks such symmetry. That said, we have already listed two formal
characteristics of the RDF graph that a specialist would recognize:
Directed
Labeled
The one-minute graph theorist
would add that RDF graphs are distinguished by the char-acteristics they lack
as much as by the characteristics they possess. RDF graphs have the following
characteristics:
Complete. That is, all <IT>Not complete</IT> two nodes have an arc running
between them. As you’ll learn in the next section, RDF demands triples—two
nodes connected by a labeled arc—and nothing less than triples. The elegant
five-pointed star shown in Figure 23.3 is complete. A square, with its corners
consid-
ered nodes and its sides arcs, is not complete, but a square with a corner-to-corner × would be.
Not connected. It is not always possible to reach any node from any other node. (The sets of resources for two RDF
triples might disjoint.)
Not symmetrical. That is, an RDF graph is
not like a triangle, a square, a star, or a
buckyball; it is more like a model railroad track or the net.
In addition, the RDF graph
is:
• Cyclic.
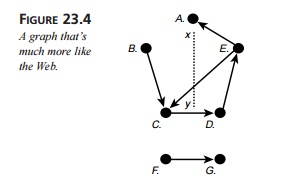
Figure 23.4 shows a cycle
from node C to node D to node E and back to node C. In
addi-tion, the figure illustrates the other formal characteristics we have just
discussed. The graph is complete. However, it is not connected: Nodes F and G can only be reached from each other, not from any of the other
nodes in the graph. What’s more, the graph isn’t symmetrical around the
vertical axis from x to y.
The
RDF Graph
The RDF graph is the data
model of RDF. It is a mathematical construct—a collection of triples—whose
characteristics define the expectations of developers and information owners
when RDF information is processed. Any RDF document should generate the same
graph when processed by any RDF processor; that is the operational definition
of interoperability.
The
RDF Statement
An RDF statement is often
called a triple because it has three
parts, as you’ll recall from the earlier blackboard discussion:
Subject
Predicate
Object
We now ask, in RDF, what are subjects, predicates, and objects?
The answer: They are all resources, uniquely identified on the Web by URIs. The
exceptions to this answer are string literals and “anonymous nodes” (to be
treated later in this chapter), which are resources but are not uniquely
identified, except possibly by an RDF application for its own internal
purposes.
As you saw in our blackboard
example, an RDF statement is like a simplified sentence in a natural language
like English. Figure 23.5 shows the sentence “Jane sells books” in the form of
an RDF graph. Jane (a nonretrievable resource represented by the URI [Jane]) is the subject node of the
statement. Books (nonretrievable and represented by [books]) is the object node of the
statement. Sells ([sells]) is the predicate, and it labels the arc between the subject and
object. Because arcs in RDF are directed, running from subject to object, we
always know which node is the subject and which node is the object.

Now that you know that
subjects, objects, and predicates are all resources on the Web and are uniquely
identified, you can see that many statements (indeed, an infinite number of
statements) can be made about any resource, and that any resource can be a
subject or an object (or a predicate). Figure 23.6 shows the flexibility of the
RDF graph, as it shows how to connect three statements: “Jane sells books,”
“books enrich publishers,” and “publishers pay Jane.” The figure shows that
resources that are subjects in one statement can be objects in another, and
vice versa.
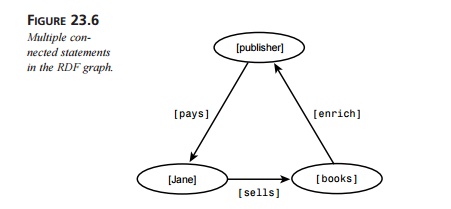
Figure 23.7 shows that we can
even make statements about statements—in this case, “‘Jane sells books’
exemplifies a statement.” This capability is called reification. Here are two examples of reification that show why it
is useful:
“John says that ‘Jane sells books.’”
“Morgoth the Vile says that ‘Jane sells books.’”
Suppose I trust John: The
reified statement “Jane sells books” is likely to be true, and I might go on to
investigate the books she sells. Suppose I do not trust Morgoth: The rei-fied
statement is likely to be false, and I probably wouldn’t invest the time to
work out its implications. (This is a small example of the “web of trust,”
discussed in Chapter 24.)
Further, if RDF were not able
to make statements about statements through reification, it would not be able
to document or assert that its own
statements are RDF statements, a strange limitation indeed. We’ll look at
reification in some detail later in this section.
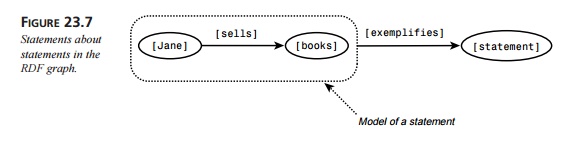
To sum up: RDF triples (or
statements) have subjects, predicates, and objects. Subjects, predicates, and
objects are all resources, uniquely identified by URIs (except, again, for
literals and anonymous nodes). Resources can participate in an infinite number
of state-ments. Furthermore, we can make statements about (models of)
statements. Before turn-ing to the data model of RDF, which formalizes these
relationships and provides the mathematical formalism to which all RDF
notations must conform, we need to look at RDF syntax, because we will need to
represent the model in syntax.
Issues
in RDF Syntax
RDF has a single data model,
but the specification allows the model to be represented in several ways:
Pictorially, in nodes and arcs diagrams
Via XML serialization (which can be “abbreviated”)
Via curly brace serialization
Typically, graph-based modeling
languages and data models have at least two syntactic representations.
Conceptual graphs and the Unified Modeling Language (UML) both have a graphical
and a serialized, linear notation, for example, as do most textbooks on graph
theory. The compact, pictorial representation is used for communication between
humans (authors, reviewers, and clients). The linear notation is used to
interchange mod-els between systems; the graphical notation is deconstructed
into the linear notation by the sender and reconstituted into the pictorial
notation by the receiver. The process of deconstruction and reconstitution
works because the linear and graphical notations are formally equivalent. RDF
is typical in this regard.
However, RDF’s XML syntax
exhibits atypical features. First, there is no W3C XML schema (or even XML DTD)
to which RDF instances must conform. Some implementers (that is, those outside
the “RDF community” who are not necessarily true believers) believe that the
lack of a clear syntax specification makes implementing the spec (at least
interoperably) virtually impossible. (Later in this chapter, Table 23.2
attempts to suma-rize RDF syntax.)
Second, RDF makes heavy use
of a technique called abbreviation,
where verbose and less-verbose versions of the XML are deemed to represent the
RDF graph in the same way. (This is shown later in the chapter in Figure
23.15.)
In this chapter, we will use
the pictorial and XML syntax for examples. RDF is about statements, and the
pictorial notation represents statements effectively. Even though the XML
syntax is not particularly stable, it is likely to be understood by the many
readers who will encounter it in other publications by the RDF community and
when they’re cre-ating their own documents.
For completeness, here is the
curly braces serialization of an RDF statement (“triple”):
{my:myPredicate,[mySubject],[myObject]}
In this notation, subjects,
predicates, and objects are determined by order, not graphical images or angle
brackets. Notice, too, that in curly braces notation, the predicate comes
first, unlike the XML serialization and the pictorial notation.
Now that you understand how
to represent RDF statements in both pictorial and XML syntax, we can now
exhibit the formal data model of RDF.
The
RDF Data Model
This section shows how the
concepts of the RDF data model are classified, how these elements map to XML
syntax, and how some “convenience” XML syntax enables the mapping of XML syntax
to the RDF data model.
There are 10 concepts in the
RDF formal model, as listed here:
RDF:Alt
RDF:Bag
RDF:Object
RDF:Predicate
RDF:Seq
RDF:Statement
RDF:Subject
RDF:Type
literal
ord
We’ll discuss the meaning of
each concept in turn. Most of them you are already familiar with. For example, RDF:Subject, RDF:Predicate, and RDF:Object are indeed the three parts
of the RDF triple, and RDF:Statement is that triple (or statement).
The new concepts are RDF:Alt, RDF:Bag, and RDF:Seq. These concepts are called con-tainers. Their names bear a
suspicious resemblance to the old-time SGML Abstract Syntax content model connectors—ALT, AND, and SEQ—and indeed the semantics are similar. Each
container concept represents a collection of subjects or objects, where the
items in the collection have the following characteristics:
Mutually exclusive. RDF:Alt (alternate). Like a content
model with an OR (|) con-nector, one of the
alternatives must be chosen.
Unordered. RDF:Bag (collection). Like a content
model with an AND (&) connector, the order in
which the members of the bag are serialized is not significant. (A bag is a
collection rather than a set, because detecting duplicate members of the
collec-tion is considered to be a validation function.)
Ordered. RDF:Seq (sequence). Like a content
model with a SEQ (,) connector, the order in
which the members of the bag are serialized is significant.
The ord data model concept gives us,
as you’ll see later when we construct containers, a way to refer to a
container’s individual members.
Finally, the literal data model concept enables
data (in XML, #PCDATA) to be incorpo-rated into the RDF graph. The data is treated as
primitive and is not interpreted in any way, even if it contains XML markup
characters.
These 10 data model concepts
are sorted into three buckets (object types):
Properties
Resources
Literals
In this case, properties is a
subset of resources.
You already know what
resources and literals are. A property is just a predicate. In object-oriented
(OO) design, resources correspond to objects and properties correspond to
instance variables.
How do these object types map
to the RDF triple? The RDF data model maps them as follows:
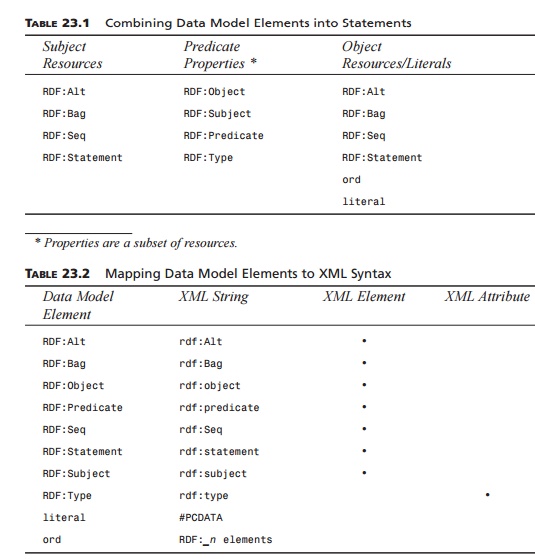
Subject. RDF:Alt, RDF:Bag, RDF:Seq, and RDF:Statement (resource object type)
Predicate. RDF:Object, RDF:Predicate, RDF:Subject, and RDF:Type (property object type)
Object. RDF:Alt, RDF:Bag, RDF:Seq, RDF:Statement, literal, and ord (resource and literal object type)
How does
the data model affect the nature of the statements we can make in RDF? First,
objects of the type Statement can be the subjects and objects of sentences,
but not the predicates of statements. For example, we cannot say “The man ‘The
man bit the dog’ the dog,” if indeed we would ever want to. Second, objects of the type Object, Predicate, Subject, or Type can be predicates in
statements but cannot be subjects or objects. Finally, objects of type literal (data) can be the object of
a statement but never the sub-ject—that is, what the statement is “about.” If
you hear the idea expressed that RDF is about metadata (data about data), not
data, this is the formal expression of that notion.
We now turn to mapping object
types in the data model to XML elements. As it turns out, the following types
all map directly to RDF XML elements: To create the RDF tag name, replace the
string “RDF” in the concept name with the RDF namespace prefix, so RDF:Alt becomes rdf:Alt, for example.
The string “RDF” in the
concept name is replaced in the tag name with the RDF name-space qualifier,
except for RDF:Type, which maps to an attribute (this mapping is implicit in RDFMS but
made explicit in RDFS):
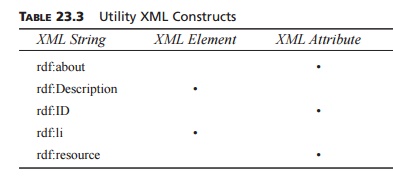
RDF:Alt
RDF:Bag
RDF:Object
RDF:Predicate
RDF:Seq
RDF:Statement
RDF:Subject
RDF:Type
So far, we’ve been working
top-down from the RDF data model to the RDF XML syn-tax. Working bottom-up from
the formal grammar in the specification, we find the fol-lowing XML convenience
constructs:
rdf:about
rdf:Description
rdf:ID
rdf:li
rdf:resource
These utility constructs
comprise the scaffolding that is discarded when RDF XML syn-tax is processed
into an RDF graph. The details of this process are given in the next sec-tion,
“Constructing the RDF Graph from XML Syntax.”
Tables 23.1, 23.2, and 23.3
summarize the relationships just described between data model object types, XML
elements that map to these object types, and the utility XML constructs,
respectively.
Constructing
the RDF Graph from XML Syntax
This section provides
pictorial and XML serialization representations for all the state-ment constructions
specified in RDFMS.
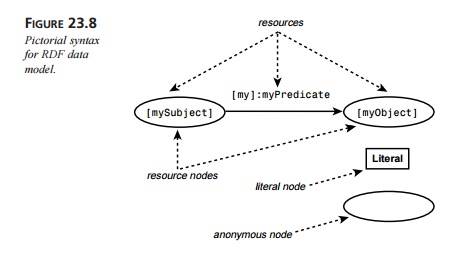
Figure 23.8 summarizes the
conventions we will use in the pictorial syntax for RDF. There are two kinds of
nodes: circles (for nodes that represent resources) and rectangles (for nodes
that represent literals). Nodes that do not represent resources (so-called anony-mous nodes) are empty circles.
Listing 23.2 is the XML
serialization of the pictorial statement in Figure 23.8. Notice the one-to-one
equivalence between the pictorial and XML representations of the model. The description element with the value of its about attribute is equivalent to
the subject node. The tag name my:myPredicate is equivalent to the predicate label on the arc that connects
subject to object (when the namespace prefix is not expanded). The value of the
rdf:resource
attribute, [myObject], is equivalent to the object
node.
LISTING 23.2 Pictorial
Syntax for RDF Data Model Serialized as XML
<rdf:Description about=”[mySubject]” xmlns:my=”[NS]”>
<my:myPredicate rdf:resource=”[myObject]”/>
The XML serialization
examples use three conventions, in addition to the conventions for showing URIs
introduced earlier in this chapter. First, XML IDs and string literals are
bold. Second, XML covered previously in the table and not repeated will be
indicated with a bold ellipsis (...).
Finally, in the pictorial
examples, namespace prefixes are replaced by the URIs to which they map when
processed—in this instance, my to [NS]. This underscores the fact that namespaces are resources too.
Figure 23.9 shows the RDF
statements that are reconstituted from the serialized children of rdf:Description. At the left, we see the RDF
graph that is created by XML markup on the right.
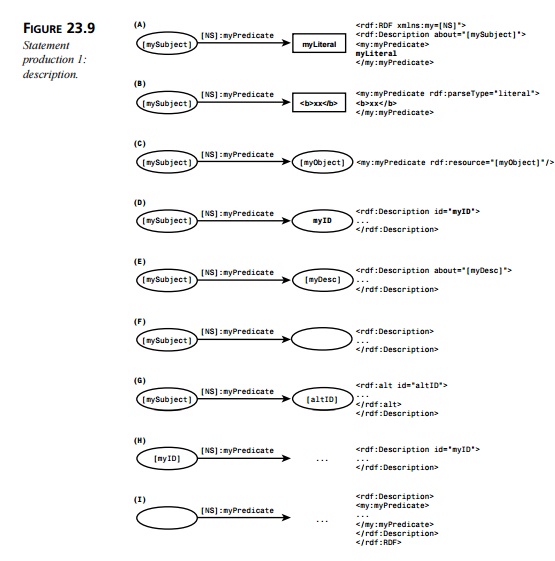
The subjects of the
statements are created in three ways: as a node whose resource is identified by
the URI in the value of the rdf:Description element’s about attribute (statements A
through G), as a node whose resource
is identified by the value of the rdf:Description element’s id attribute (statement I), and as an anonymous node, because the rdf:Description element has neither an about nor an id attribute.
The predicates of all the
statements are created by expanding the namespace-qualified tag name (generic
identifier) of the child element of rdf:Description, as in statements A through C. In the
examples, the namespace prefix my in the markup is replaced by
its namespace name [NS] in the graph, as given in
the xmlns:my namespace declaration on the
rdf:RDF element in production A. (The predicates for statements D through J are cre-ated as described earlier and are replaced in the markup
by ellipses on the right side.)
When the child element of rdf:Description is not an RDF element, the
objects for all the statements are created as nodes either from the #PCDATA contained in the predicate
element (in the example, my:myPredicate), as in statement A;
from XML markup con-tained in the predicate element when the predicate’s rdf:parseType attribute has a value of literal, as in statement B; or from the resource identified by
the URI in the value of the predicate element’s rdf:resource attribute, as in statement C.
When the child element is an
RDF element, it may be another rdf:Description element, as in statements D
through F. As mentioned earlier, the
resource of the object node may be identified with an ID (statement D), with the about attribute (statement E), or as anonymous (statement F).
The child element may also be
an RDF container element; the object of the statement becomes the resource
identified by the value of the id attribute of that container, as in statement G.
The objects and predicates in
statements H and I are created as described earlier and are therefore replaced by
ellipses on both the graph and markup sides.
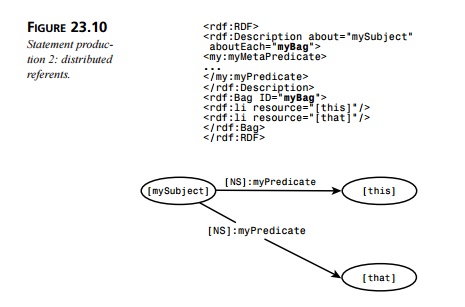
Figure 23.10 shows how a
single subject can be distributed over several objects in the graph using the aboutEach attribute.
There are two statements in
Figure 23.10, although they both have the same subject ([mySubject]) and predicate ([myPredicate]), derived respectively from
the rdf:Description
and my:myPredicate elements, as shown previously
in Figure 23.9.
The objects in the statements
are created as nodes from the children of the RDF con-tainer element whose ID
is the value of the aboutEach attribute on the containing rdf:Description element.
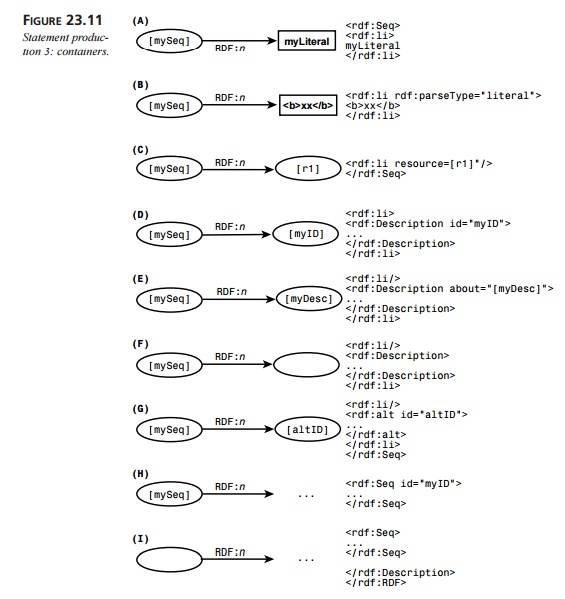
Figure 23.11 shows the RDF
statements that are created in the graph when a serialized RDF container is
reconstituted (rdf:Seq is used, but the same applies to rdf:Alt and rdf:Bag). The productions are parallel to Figure 23.9,
with the container in place of rdf:Description and the list items in place of the predicate elements.
The subject of each statement
is a node whose resource is the container element itself, identified by the
value of its id attribute.
The predicates of each
statement are nodes whose resources are the rdf:li elements, identified by their sequence within
the XML markup, in the form RDF:_1, RDF:_2, up to RDF:_n, where n the number of list items, as
generated by the RDF processor.
When the child element of the
container element is not an RDF element, the objects for all the statements are
created as nodes either from the #PCDATA contained in the predicate element (in the
example, rdf:li), as in statement A;
from XML markup contained in the predicate element when the predicate’s rdf:parseType attribute has a value of literal, as in statement B; or from the resource identified by
the URI in the value of the predicate element’s rdf:resource attribute, as in statement C.
When the child element is an
RDF element, it may be an rdf:Description element, as in statements D
through F. As mentioned earlier, the
resource of the object node may be identified with an ID (statement D), with the about attribute (statement E), or as anony-mous (statement F).
The child element may also be
an RDF container element; the object of the statement becomes the resource
identified by the value of the id attribute of that container, as in statement G.
The objects and predicates in
statements H and I are created as described earlier and are therefore replaced by
ellipses on both the graph and markup sides.
Figure
23.12 shows the RDF statements that are created in the graph when the aboutEachPrefix feature is used on an rdf:Description element in the markup.
The subject of the statements
is reconstituted from a serialized rdf:Description ele-ment, as shown previously in Figure 23.9.
The predicate of the statements is reconsti-tuted as for any serialized rdf:Description element, again as in Figure
23.9.

The objects of the statements
are created as nodes from resources whose identifiers begin with the character
string that is the value of the aboutEachPrefix prefix on the rdf:Description element. In Figure 23.12, the prefix is [my]. Therefore, the resources [my]/foo.xml, [my]/bar.xml, and [my]/baz.xml are objects of the
statements, and the resources [other]/foo.xml and [other]/bar.xml are not objects.
Figure 23.13 shows how the
same graph can be reconstituted from serialized rdf:Description elements that use attributes rather than
element content for their sub-ject and object resources.
Compare statement A with statement C in Figure 23.9. Whereas Figure 23.9 uses an ele-ment, my:myPredicate, for its predicate and the
attribute value of its rdf:resource attribute for its object; statement A in Figure 23.13 uses the my:myPredicate attribute right in the rdf:Description element for the predicate
and uses the value of that attribute for its object.

Now compare statement B with statement A in Figure 23.9. Here again, the predicate serialized from a my:myPredicate element in Figure 23.9 is
reconstituted from the serial-ized attribute of the same name in statement B in Figure 23.13. Also, the
reconstituted object is not the value of an rdf:resource attribute but rather the value of the my:myPredicate attribute.
Finally, compare statement C with the distributed referent in
Figure 23.10. Again, whereas Figure 23.10 uses an element (my:myPredicate) for the predicate,
statement C in Figure 23.13 uses an attribute (my:myPredicate) on rdf:Description. Also, whereas Figure 23.10 uses the value of
an rdf:resource attribute for the object,
statement C uses the value of an
attribute (my:myPredicate).
Figure 23.14 shows the graph
that is constructed by embedding a namespace-qualified XML element inside an rdf:Description element. The subject is
taken from the value of the rdf:Description element’s about attribute. The predicate is RDF:type, and the object is the embedded XML element.
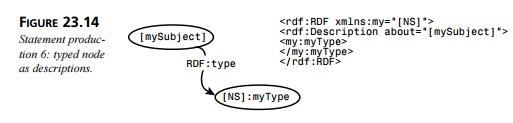
Figure 23.15 shows the graph
reconstituted from ordinary XML elements and attributes, where the tag and
attribute names are “namespace qualified” within an RDF description element.
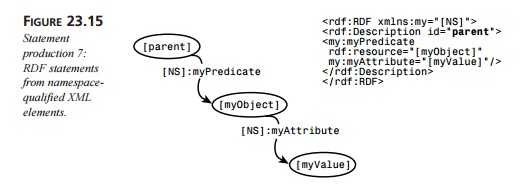
The subject of statement A is the node reconstituted from the
serialized parent rdf:Description element. The predicate of the statement is reconstituted from the namespace-qualified tag name
of the child element. The object is reconstituted from the value of the rdf:resource attribute on that child
element.
Statement B is a complete statement reconstituted
from the child element itself. The sub-ject of the statement is reconstituted
from the value of the rdf:resource attribute. The predicate of the statement is reconstituted from
another qualified attribute name on the child element (here, my:myAttribute). The object of the
statement is reconstituted from the value of that attribute name (my:myAttribute).
In effect, then, any XML
element can be caused to constitute RDF statements, as long as it uses
namespace-qualified names in its element and attribute names.
Reification
Figure 23.16 shows the
process of RDF reification: making a statement about a model of a statement.
Why would we make a statement
about a model of a statement instead of a statement about a statement? First,
we avoid problems of recursion. Second, we avoid problems with data integrity
in any store of RDF statements we might have. Suppose that we have a store of
RDF statements, all of which are true. We then wish to make this statement:
“The statement ‘blue is the same as green’ is false.” If we kept the statement
“blue is the same as green” in our store of true statements, we lose our data
integrity. We could, of course, make a separate store for statements that are
false, but who would want to main-tain such a system? The upshot is that we
want to be able to make statements about hypothetical
statements—statements that would act just like statements if only we made them. That way, our store of true
statements remains uncorrupted.
The answer, as mentioned
previously, is to make statements about models of statements (that is, hypothetical
statements). Figure 23.16 shows how to do this. In Figure 23.16, Statement A is a statement about a model of
statement C. Again, when we build a
model of statement C, we say that we
“reify” it. (Statement C has a dotted
line around it to show that a reified statement may be purely hypothetical,
such as “blue is the same as green.”)
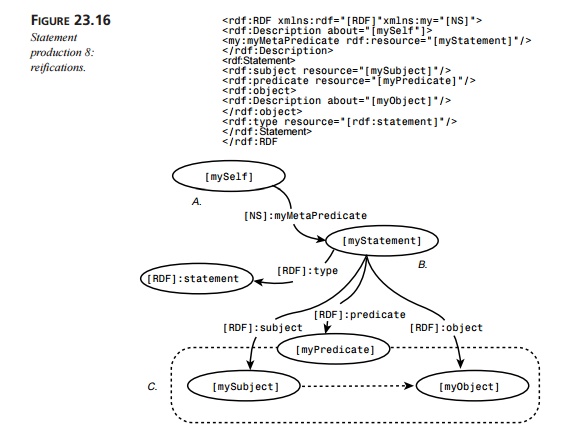
First, we construct a normal
RDF statement using a description element, as detailed in Figure 23.9.
The subject of statement A is a node from the [myself] resource, which is the value
of the about attribute of the rdf:Description element. ([mySelf] is the “reifier” of the hypothetical statement B.)
The predicate of statement A takes the expanded namespace-qualified
tag name (here, my:myMetaPredicate).
The object of statement A (here, [myStatement]) is constituted by the value of the rdf:resource attribute on the predicate
element.
The object of statement A—the resource [myStatement] (at B)—represents our state-ment
model. Now, let’s build that model. We know that statements have subjects,
predi-cates, and objects. Therefore, we need to say that one predicate of [myStatement] is that it is a type of
statement, a second predicate is that it has a subject, a third that it has an
object, and a fourth that it has a predicate.
Therefore, one predicate of [myStatement] is that its [RDF]:type is [RDF]:Statement. A second predicate of [myStatement] is that it has an [RDF]:subject, the resource [mySubject].
A third predicate of [myStatement] is that it has an [RDF]:predicate, the resource [myPredicate], and a fourth predicate of [myStatement] is that it has an [RDF]:object, the resource [myObject].
Because statement B has all the predicates that a
nonhypothetical statement has, RDF can treat it as a statement. (If it walks
like a duck....)
RDF
XML Syntax Summary
Tables 23.4 and 23.5 supply
what is missing from the RDF specification—something approaching a DTD. Table
23.4 gives the attributes that RDF elements may have; Table 23.5 lists their
content models.
In Table 23.4, the RDF
elements label rows, and the RDF attributes label columns. An element that may
have an attribute has a bullet (•) in its cell. For example, rdf:Description may have an id attribute or an rdf:about attribute.

In Table 23.5, the RDF
elements are on the left and their permitted content are on the right. For
example, an rdf:Seq element can contain rdf:li elements.
TABLE 23.5 RDF XML
Syntax: Permitted Content
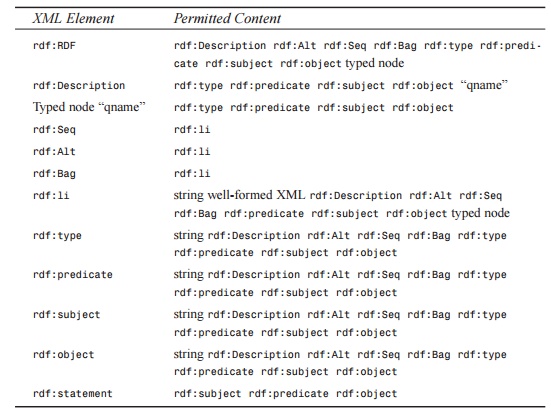
XML Element Permitted
Content
rdf:RDF rdf:Description rdf:Alt
rdf:Seq rdf:Bag rdf:type
rdf:predi-cate rdf:subject rdf:object typed node
rdf:Description rdf:type
rdf:predicate rdf:subject rdf:object
“qname”
Typed node “qname” rdf:type
rdf:predicate rdf:subject rdf:object
rdf:Seq rdf:li
rdf:Alt rdf:li
rdf:Bag rdf:li
rdf:li string well-formed XML rdf:Description rdf:Alt
rdf:Seq rdf:Bag rdf:predicate
rdf:subject rdf:object typed node
rdf:type string rdf:Description rdf:Alt
rdf:Seq rdf:Bag rdf:type
rdf:predicate
rdf:subject rdf:object
rdf:predicate string rdf:Description rdf:Alt
rdf:Seq rdf:Bag rdf:type
rdf:predicate
rdf:subject rdf:object
rdf:subject string rdf:Description rdf:Alt
rdf:Seq rdf:Bag rdf:type
rdf:predicate
rdf:subject rdf:object
rdf:object string rdf:Description rdf:Alt
rdf:Seq rdf:Bag rdf:type
rdf:predicate
rdf:subject rdf:object
rdf:statement rdf:subject rdf:predicate
rdf:object
Here are
the XML namespace declarations for RDF:
rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#
rdfs: http://www.w3.org/2000/01/rdf-schema#
In this
chapter, for readability, we show the first namespace as [RDF], and
the second as [RDFS] when expanding these URIs.
Related Topics