Chapter: Fundamentals of Database Systems : Conceptual Modeling and Database Design : Practical Database Design Methodology and Use of UML Diagrams
The Database Design and Implementation Process
The Database Design and Implementation Process
Now, we focus on activities 2 and 3 of the database application system
life cycle, which are database design and implementation. The problem of
database design can be stated as follows:
Design the logical and physical
structure of one or more databases to accommodate the information needs of the
users in an organization for a defined set of applications.
The goals of database design are multiple:
Satisfy the information content
requirements of the specified users and applications.
Provide a natural and
easy-to-understand structuring of the information.
Support processing requirements
and any performance objectives, such as response time, processing time, and
storage space.
These goals are very hard to accomplish and measure and they involve an
inherent tradeoff: if one attempts to achieve more naturalness and understandability
of the model, it may be at the cost of performance. The problem is aggravated
because the database design process often begins with informal and incomplete requirements.
In contrast, the result of the design activity is a rigidly defined database
schema that cannot easily be modified once the database is implemented. We can
identify six main phases of the overall database design and implementation
process:
Requirements collection and
analysis
Conceptual database design
Choice of a DBMS
Data model mapping (also called logical database design)
Physical database design
Database system implementation
and tuning
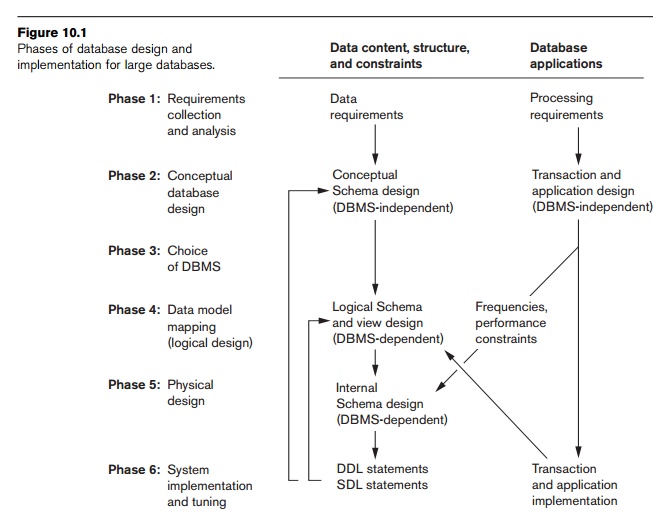
The design process consists of two parallel activities, as illustrated
in Figure 10.1. The first activity involves the design of the data content, structure, and constraints
of the database; the second relates to the design of database applications. To keep the figure simple, we have avoided
showing most of the interactions between these sides, but the two activities
are closely intertwined. For example, by analyzing data-base applications, we
can identify data items that will be stored in the database. In addition, the
physical database design phase, during which we choose the storage structures
and access paths of database files, depends on the applications that will use
these files for querying and updating. On the other hand, we usually specify
the design of database applications by referring to the database schema
constructs, which are specified during the first activity. Clearly, these two
activities strongly influence one another. Traditionally, database design
methodologies have primarily focused on the first of these activities whereas
software design has focused on the second; this may be called data-driven versus process-driven design. It now is rec-ognized by database designers
and software engineers that the two activities should proceed hand-in-hand, and
design tools are increasingly combining them.
The six phases mentioned previously do not typically progress strictly
in sequence. In many cases we may have to modify the design from an earlier
phase during a later phase. These feedback
loops among phases—and also within phases—are com-mon. We show only a
couple of feedback loops in Figure 10.1, but many more exist between various
phases. We have also shown some interaction between the data and the process
sides of the figure; many more interactions exist in reality. Phase 1 in Figure
10.1 involves collecting information about the intended use of the database,
and Phase 6 concerns database implementation and redesign. The heart of the
data-base design process comprises Phases 2, 4, and 5; we briefly summarize
these phases:
Conceptual database design (Phase 2). The goal
of this phase is to produce a
conceptual schema for the database that is independent of a specific DBMS. We
often use a high-level data model such as the ER or EER model (see Chapters 7
and 8) during this phase. Additionally, we specify as many of the known
database applications or transactions as possible, using a nota-tion that is
independent of any specific DBMS. Often, the DBMS choice is already made for
the organization; the intent of conceptual design is still to keep it as free
as possible from implementation considerations.
Data model mapping (Phase 4). During
this phase, which is also called logical
database design, we map (or transform) the conceptual schema from the high-level data model used in
Phase 2 into the data model of the chosen DBMS. We can start this phase after
choosing a specific type of DBMS—for example, if we decide to use some
relational DBMS but have not yet decided on which particular one. We call the
latter system-independent (but data model-dependent) logical design. In
terms of the three-level DBMS architecture discussed in Chapter 2, the result
of this phase is a conceptual schema in the chosen data model. In
addition, the design of external schemas (views)
for specific applications is often done during this phase.
Physical database design (Phase 5). During
this phase, we design the specifications for the stored database in terms of
physical file storage structures, record placement, and indexes. This
corresponds to designing the internal
schema in the terminology of the
three-level DBMS architecture.
Database system implementation and tuning (Phase 6). During this phase, the
database and application programs are implemented, tested, and eventually
deployed for service. Various transactions and applications are tested
individually and then in conjunction with each other. This typically reveals
opportunities for physical design changes, data indexing, reorganization, and
different placement of data—an activity referred to as database tuning. Tuning
is an ongoing activity—a part of system maintenance that continues for the life cycle of a database as long as the database
and applications keep evolving and performance problems are detected.
We discuss each of the six phases of database design in more detail in
the following subsections.
Related Topics