Chapter: Fundamentals of Database Systems : Conceptual Modeling and Database Design : Relational Database Design by ER- and EER-to-Relational Mapping
Mapping EER Model Constructs to Relations
Mapping EER Model Constructs to Relations
Next, we discuss the mapping of EER model constructs to relations by
extending the ER-to-relational mapping algorithm that was presented in Section
9.1.1.
1. Mapping of Specialization or Generalization
There are
several options for mapping a number of subclasses that together form a
specialization (or alternatively, that are generalized into a superclass), such
as the {SECRETARY, TECHNICIAN, ENGINEER}
subclasses of EMPLOYEE in
Figure 8.4. We can add a further step to our ER-to-relational mapping algorithm
from Section 9.1.1, which has seven steps, to handle the mapping of
specialization. Step 8, which follows, gives the most common options; other
mappings are also possible. We dis-cuss the conditions under which each option
should be used. We use Attrs(R) to
denote the attributes of relation R,
and PK(R) to denote the primary key of R. First we describe the
mapping formally, then we illustrate it with examples.
Step 8: Options for Mapping Specialization or
Generalization. Convert each
specialization
with m subclasses {S1, S2, ..., Sm}
and (generalized) superclass C, where
the attributes of C are {k, a1,
...an} and k is the (primary) key, into relation
schemas using one of the following options:
Option
8A: Multiple relations—superclass and subclasses. Create a
relation L for C with attributes Attrs(L)
= {k, a1, ..., an}
and PK(L) = k. Create a relation Li
for each subclass Si, 1 ≤ i ≤ m, with the attributes Attrs(Li) = {k} ∪
{attributes of Si} and PK(Li) = k. This option works for any specialization (total or partial,
disjoint or overlapping).
Option
8B: Multiple relations—subclass relations only. Create a
relation
Li for each subclass Si, 1 ≤ i ≤ m, with
the attributes Attrs(Li) =
{attributes of Si} ∪ {k,
a1, ..., an}
and PK(Li) = k. This option only works for a
specialization whose subclasses are total (every entity in the superclass
must belong to (at least) one of the subclasses). Additionally, it is only
recommended if the specialization has the disjointedness
constraint (see Section 8.3.1).If the specialization is overlapping, the same entity may be
duplicated in several relations.
Option
8C: Single relation with one type attribute. Create a single relation
L with attributes Attrs(L) = {k, a1, ..., an} ∪ {attributes of S1} ∪ ... ∪ {attributes of Sm} ∪ {t} and
PK(L) = k. The attribute t is
called a type (or discriminating) attribute whose value
indicates the subclass to which each tuple
belongs, if any. This option works only for a specialization whose sub-classes
are disjoint, and has the potential
for generating many NULL values
if many specific attributes exist in the subclasses.
Option
8D: Single relation with multiple type attributes. Create a
single relation schema L with attributes Attrs(L) = {k, a1, ..., an} ∪ {attributes of S1}
∪ ... ∪
{attributes of Sm} ∪ {t1,
t2, ..., tm} and PK(L) = k.
Each ti, 1 ≤ i ≤ m, is
a Boolean type attribute indicating
whether a tuple belongs to subclass Si.
This option is used for a specialization whose subclasses are overlapping (but will also work for a
disjoint specialization).
Options
8A and 8B can be called the multiple-relation
options, whereas options 8C and 8D can be called the single-relation options. Option 8A creates a relation L for the superclass C and its attributes, plus a relation Li for each subclass Si; each Li includes the specific (or local) attributes of Si, plus the primary key of
the superclass C, which is propagated
to Li and becomes its
primary key. It also becomes a foreign key
to the superclass relation. An EQUIJOIN
operation on the primary key between any Li
and L produces all the specific and
inherited attributes of the entities in Si.
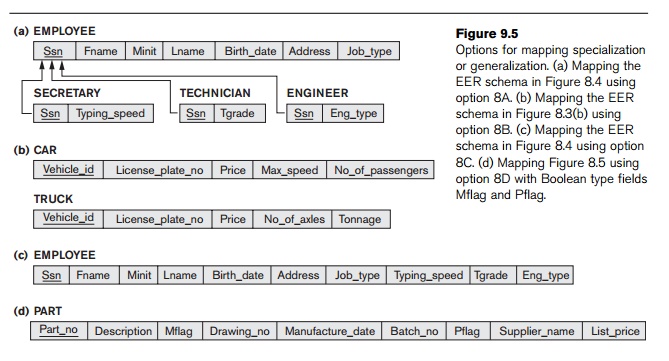
This option is illustrated in Figure 9.5(a) for the EER schema in Figure 8.4.
Option 8A works for any constraints on the specialization: disjoint or
overlapping, total or partial. Notice that the constraint
π<k>(Li) ⊆ ð<k>(L)
must hold
for each Li. This
specifies a foreign key from each Li
to L, as well as an inclusion dependency Li.k < L.k (see Section 16.5).
In option
8B, the EQUIJOIN operation between each subclass
and the superclass is built into the
schema and the relation L is done
away with, as illustrated in Figure 9.5(b)
for the EER specialization in Figure 8.3(b). This option works well only when both the disjoint and total constraints
hold. If the specialization is not total, an
entity that does not belong to any of the subclasses Si is lost. If the specialization is not disjoint, an
entity belonging to more than one subclass will have its inherited attributes
from the superclass C stored
redundantly in more than one Li.
With option 8B, no relation holds all the entities in the superclass C; consequently, we must apply an OUTER UNION (or FULL OUTER JOIN) operation (see Section 6.4) to
the Li relations to
retrieve all the entities in C. The
result of the outer union will be similar to the relations under options 8C and
8D except that the type fields will be missing. Whenever we search for an
arbitrary entity in C, we must search
all the m relations Li.
Options
8C and 8D create a single relation to represent the superclass C and all its subclasses. An entity that
does not belong to some of the subclasses will have NULL values for the specific
attributes of these subclasses. These options are not recommended if many
specific attributes are defined for the subclasses. If few specific sub-class
attributes exist, however, these mappings are preferable to options 8A and 8B
because they do away with the need to specify EQUIJOIN and OUTER
UNION
operations; therefore, they can yield a more efficient implementation.
Option 8C
is used to handle disjoint subclasses by including a single type (or image or discriminating)
attribute t to indicate to which of the m
subclasses each tuple belongs; hence, the domain of t could be {1, 2, ..., m}.
If the specialization is partial, t can
have NULL values in
tuples that do not belong to any subclass. If the specialization is
attribute-defined, that attribute serves the purpose of t and t is not needed;
this option is illustrated in Figure 9.5(c) for the EER specialization in
Figure 8.4.
Option 8D
is designed to handle overlapping subclasses by including m Boolean type (or flag) fields, one for each subclass. It can also be used for
disjoint subclasses. Each type field
ti can have a domain {yes,
no}, where a value of yes indicates that the tuple is a member of subclass Si. If we use this option for
the EER specialization in Figure 8.4, we would include three types attributes—Is_a_secretary, Is_a_engineer, and Is_a_technician—instead
of the Job_type attribute in Figure 9.5(c).
Notice that it is also possible to create a single type attribute of m bits instead of the m type fields. Figure 9.5(d) shows the
mapping of the specialization from Figure 8.5 using option 8D.
When we
have a multilevel specialization (or generalization) hierarchy or lattice, we
do not have to follow the same mapping option for all the specializations.
Instead, we can use one mapping option for part of the hierarchy or lattice and
other options for other parts. Figure 9.6 shows one possible mapping into
relations for the EER lattice in Figure 8.6. Here we used option 8A for PERSON/{EMPLOYEE, ALUMNUS, STUDENT}, option 8C for EMPLOYEE/{STAFF, FACULTY, STUDENT_ASSISTANT} by
including
the type attribute Employee_type, and
option 8D for STUDENT_ASSISTANT/{RESEARCH_ASSISTANT, TEACHING_ ASSISTANT} by
including
the type attributes Ta_flag and Ra_flag in EMPLOYEE, STUDENT/

STUDENT_ASSISTANT by including the type attributes Student_assist_flag in STUDENT, and STUDENT/{GRADUATE_STUDENT,
UNDERGRADUATE_STUDENT} by
including the type attributes Grad_flag and Undergrad_flag in STUDENT. In Figure 9.6, all attributes
whose names end with type or flag are type fields.
2. Mapping of Shared
Subclasses (Multiple Inheritance)
A shared subclass, such as ENGINEERING_MANAGER in Figure 8.6, is a subclass of several superclasses, indicating
multiple inheritance. These classes must all have the same key attribute;
otherwise, the shared subclass would be modeled as a category (union type) as
we discussed in Section 8.4. We can apply any of the options dis-cussed in step
8 to a shared subclass, subject to the restrictions discussed in step 8 of the
mapping algorithm. In Figure 9.6, options 8C and 8D are used for the shared
subclass STUDENT_ASSISTANT. Option 8C is used in the EMPLOYEE relation
(Employee_type attribute) and option 8D is used in the STUDENT relation
(Student_assist_flag attribute).
3. Mapping of Categories
(Union Types)
We add
another step to the mapping procedure—step 9—to handle categories. A category
(or union type) is a subclass of the union
of two or more superclasses that can have different keys because they can be of
different entity types (see Section 8.4). An example is the OWNER category shown in Figure 8.8,
which is a subset of the union of three entity types PERSON, BANK, and COMPANY. The
other category in that figure, REGISTERED_VEHICLE, has two
superclasses that have the same key attribute.
Step 9: Mapping of Union Types (Categories). For
mapping a category whose defining
superclasses have different keys, it is customary to specify a new key
attribute, called a surrogate key,
when creating a relation to correspond to the category. The keys of the
defining classes are different, so we cannot use any one of them exclusively to
identify all entities in the category. In our example in Figure 8.8, we create
a relation OWNER to
correspond to the OWNER
category, as illustrated in Figure 9.7, and include any attributes of the
category in this relation. The primary key of the OWNER relation is the surrogate key,
which we called Owner_id. We also
include the surrogate key attribute Owner_id as
foreign key in each relation corresponding to a superclass of the category, to
specify the correspondence in values between the surrogate key and the key of
each superclass. Notice that if a particular PERSON (or BANK or COMPANY) entity is not a member of OWNER, it would have a NULL value for its Owner_id
attribute in its corresponding tuple in the PERSON (or BANK or COMPANY) relation, and it would not have a tuple in the OWNER relation. It is also recommended to add a
type attribute (not shown in Figure 9.7) to the OWNER relation to indicate the particular entity type to which each tuple
belongs (PERSON or BANK or COMPANY).
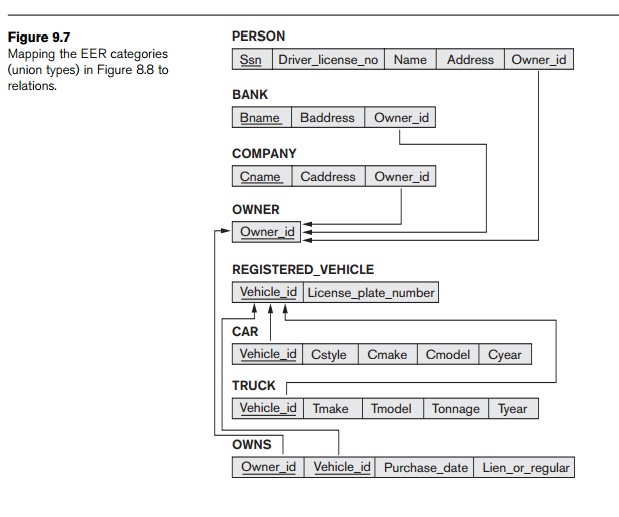
For a
category whose superclasses have the same key, such as VEHICLE in Figure 8.8,
REGISTERED_VEHICLE there is no need for a surrogate key. The mapping of the category,
which illustrates this case, is also shown in Figure 9.7.
Related Topics