Chapter: Fundamentals of Database Systems : Advanced Database Models, Systems, and Applications : Introduction to Information Retrieval and Web Search
Inverted Indexing
Inverted Indexing
The simplest way to search for occurrences of query terms in text
collections can be performed by sequentially scanning the text. This kind of
online searching is only appropriate when text collections are quite small.
Most information retrieval systems process the text collections to create
indexes and operate upon the inverted index data structure (refer to the
indexing task in Figure 27.1). An inverted index structure comprises vocabulary
and document information. Vocabulary
is a set of distinct query terms in the document set. Each term in a vocabulary
set has an associated collection of information about the documents that
contain the term, such as document id, occurrence count, and offsets within the
document where the term occurs. The simplest form of vocabulary terms consists
of words or individual tokens of the documents. In some cases, these vocabulary
terms also consist of phrases, n-grams, entities, links, names, dates, or
manually assigned descriptor terms from documents and/or Web pages. For each
term in the vocabulary, the cor-responding document ids, occurrence locations
of the term in each document, number of occurrences of the term in each
document, and other relevant information may be stored in the document
information section.
Weights are assigned to document terms to represent an estimate of the
usefulness of the given term as a descriptor for distinguishing the given
document from other documents in the same collection. A term may be a better
descriptor of one document than of another by the weighting process (see
Section 27.2).
An inverted index of a
document collection is a data structure that attaches distinct terms with a
list of all documents that contains the term. The process of inverted index
construction involves the extraction and processing steps shown in Figure 27.2.
Acquired text is first preprocessed and the documents are represented with the
vocabulary terms. Documents’ statistics are collected in document lookup
tables. Statistics generally include counts of vocabulary terms in individual
documents as well as different collections, their positions of occurrence
within the documents, and the lengths of the documents. The vocabulary terms
are weighted at indexing time according to different criteria for collections.
For example, in some cases terms in the titles of the documents may be weighted
more heavily than terms that occur in other parts of the documents.
One of the most popular weighting schemes is the TF-IDF (term
frequency-inverse document frequency) metric that we described in Section 27.2.
For a given term this weighting scheme distinguishes to some extent the
documents in which the term occurs more often from those in which the term
occurs very little or never. These weights are normalized to account for
varying document lengths, further ensuring that longer documents with proportionately
more occurrences of a word are not favored for retrieval over shorter documents
with proportionately fewer occurrences. These processed document-term streams
(matrices) are then inverted into term-document streams (matrices) for further
IR steps.
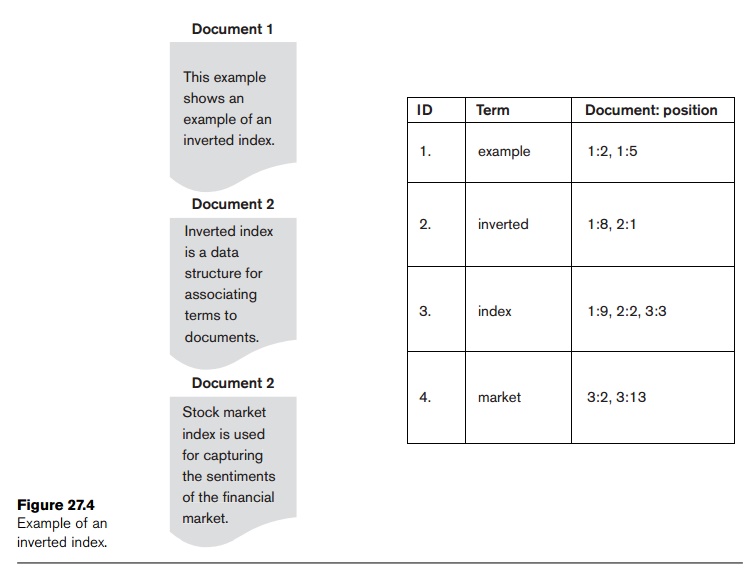
Figure 27.4 shows an illustration of term-document-position vectors for
the four illustrative terms—example, inverted, index, and market—which
refer to the three documents and the position where they occur in those
documents.
The different steps involved in inverted index construction can be
summarized as follows:
1.
Break the documents into
vocabulary terms by tokenizing, cleansing, stopword removal, stemming, and/or
use of an additional thesaurus as vocabulary.
2.
Collect document statistics and
store the statistics in a document lookup table.
3.
Invert the document-term stream
into a term-document stream along with additional information such as term
frequencies, term positions, and term weights.
Searching for relevant documents from the inverted index, given a set of
query terms, is generally a three-step process.
Vocabulary search. If the query comprises multiple
terms, they are separated and treated as independent terms. Each term is
searched in the vocabulary. Various data structures, like variations of B+-tree or hashing, may be
used to optimize the search process. Query terms may also be ordered in
lexicographic order to improve space efficiency.
Document information retrieval. The
document information for each term is
retrieved.
Manipulation of retrieved information. The document information vector for
each term obtained in step 2 is now processed further to incorporate various
forms of query logic. Various kinds of queries like prefix, range, context, and
proximity queries are processed in this step to construct the final result
based on the document collections returned in step 2.
Related Topics