Chapter: Civil : Remote Sensing Techniques and GIS : Image Interpretation And Analysis
Image Classification
IMAGE CLASSIFICATION
Image classification is a
procedure to automatically categorize all pixels in an image of a terrain into
land cover classes. Normally, multispectral data are used to perform the
classification of the spectral pattern present within the data for each pixel is
used as the numerical basis for
categorization. This concept is dealt under thebroad subject, namely, Pattern
Recognition. Spectral pattern recognition refers to the family of
classification procedures that utilizes this pixel-by-pixel spectral
information as the basis for automated land cover classification. Spatial
pattern recognition involves the categorization of image pixels on the basis of
the spatial relationship with pixels surrounding them. Image classification
techniques aregrouped into two types, namely supervised and unsupervised. The
classification process may also include features, such as, land surface
elevation and the soil type that are not derived from the image. A pattern is
thus a set of measurements on the chosen features for the individual to be
classified. The classification process may therefore be considered a form of
pattern recognition, that is, the identification of the pattern associated with
each pixel position in an image in terms of the characteristics of the objects
or on the earth's surface.
1 SUPERVISED CLASSIFICATION
A supervised
classification algorithm requires a training sample for each class, that
is, a collection of data points known to have come from the class of interest.
Theclassification is thus based on how "close" a point to be
classified is to each training sample. We shall not attempt to define the word "close"
other than to say that both geometric and statistical distance measures are
used in practical pattern recognition algorithms. The training samples are
representative of the known classes of interest to the analyst. Classification
methods that relay on use of training patterns are called supervised
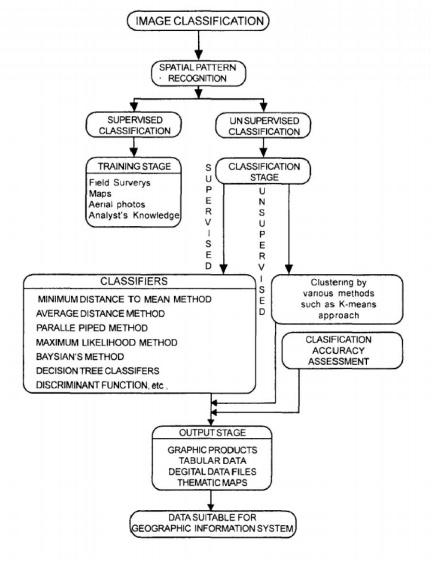
classification methods. The three basic steps (Fig. 6.23) involved in a typical
supervised classification procedure are as follows:
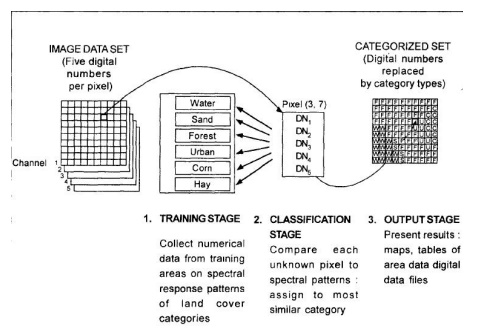
(i)
Training stage: The
analyst identifies representative training areas and develops numerical
descriptions of the spectral signatures of each land cover type of interest in
the scene.
(ii)
The classification stage: Each
pixel in the image data set IS categorised intothe land cover class it
most closely resembles. If the pixel is insufficientlysimilar to any training
data set it is usually labeled 'Unknown'.
(iii)
The output stage: The
results may be used in a number of different ways.Three typical forms of
output products are thematic maps, tables and digitaldata files which become
input data for GIS. The output of image classificationbecomes input for GIS for
spatial analysis of the terrain.
2 UNSUPERVISED CLASSIFICATION
Unsupervised classification algorithms
do not compare .points to be classified with training data. Rather,
unsupervised algorithms examine a large number of unknown data vectors and
divide them into classes based on properties inherent to the data themselves.
The classes that result stem from differences observed in the data. In
particular, use is made of the notion that data vectors within a class should
be in some sense mutually close together in the measurement space, whereas data
vectors in different classes should be comparatively well separated. If the
components of the data vectors represent the responses in different spectral
bands, the resulting classes might be referred to as spectral classes, as
opposed to information classes, which represent the ground cover types of
interest to the analyst. The two types of classes described above, information
classes and spectralclasses, may not exactly correspond to each other. For
instance, two information classes, corn and soyabeans, may look alike spectrally.
We would say that the two classes are not separable spectrally. At certain
times of the growing season corn and soyabeans are not spectrally distinct
while at other times they are. On the other hand a single information class may
be composed of two spectral classes. Differences in planting dates or seed
variety might result in the information class" corn" being
reflectance differences of tasseled and untasseled corn. To be useful, a class
must be of informational value and be separable from other classes in the data.
Related Topics