Chapter: Operating Systems : File Systems
File System Structure
FILE
SYSTEM STRUCTURE
ü All disk
I/O is performed in units of one block (physical record) size which will
exactly match the length of the desired
logical record.
ü Logical
records may even vary in length. Packing a number of logical records into physical blocks is a common solution to this problem.
ü For
example, the UNIX operating system defines all files to be simply a tream of bytes. Each byte is individually addressable by its offset
from the beginning (or end) of the file. In this case, the logical records are
1 byte. The file system automatically packs and unpacks bytes into physical
disk blocks – say, 512 bytes per block – as
necessary.
The logical record size, physical block size, and
packing technique determine how many logical records are in each physical
block. The packing can be done either by the user’s application
program or by the operating system.
1. Access
Methods
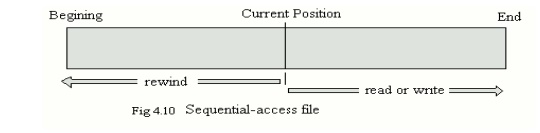
1. Sequential Access
The
simplest access method is sequential access. Information in the file is
processed in order, one record after the other. This mode of access is by far
the most common; for example, editors and compilers usually access files in
this fashion.
v The bulk
of the operations on a file is reads and writes. A read operation reads the
next portion of the file and automatically advances a file pointer, which
tracks the I/O location. Similarly, a write appends to the end of the file and
advances to the end of the newly written material (the new end of file). Such a
file can be reset to the beginning and, on some systems, a program may be able
to skip forward or back ward n records, for some integer n-perhaps only for
n=1. Sequential access is based on a tape model of a file, and works as well on
sequential-access devices as it does on random – access ones.
2. Direct Access
v Another
method is direct access (or relative access). A file is made up of fixed length
logical records that allow programs to read and write records rapidly in no
particular order. The direct- access methods is based on a disk model of a
file, since disks allow random access to any file block.
v For
direct access, the file is viewed as
a numbered sequence of blocks or records. A
direct-access file allows arbitrary blocks to be read or
written. Thus, we may read block 14, then read block 53, and then write block7.
There are no restrictions on the order of reading or writing for a
direct-access file.
Direct – access files are of great use
for immediate access to large amounts of information. Database is often of this
type. When a query concerning a particular subject arrives, we compute which
block contains the answer, and then read that block directly to provide the
desired information.
As a simple example, on an air line reservation
system, we might store all the (for information about a particular flight
example, flight 713) in the block identified by the flight number.
v Thus, the
number of available seats for flight 713 is stored in block 713 of the
reservation file. To store information about a larger set, such as people, we
might
compute a hash function on the people’s names,
or search a small in- memory index to determine a block to read and search.
3 Other Access methods
Other access methods can be built on top of a direct – access
method these methods generally involve the construction of an index for the
file. The index like an index in the back of a book contains pointers to the
various blocks in find a record in the file. We first search the index, and
then use the pointer to access the file directly and the find the desired
record.
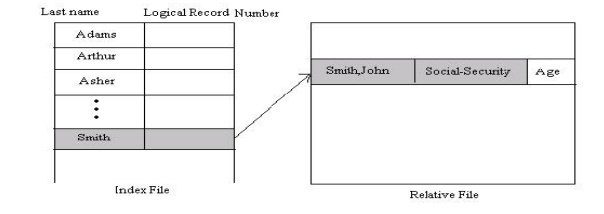
v With
large files, the index file itself may become too large to be kept in memory. One solution is to create an index for the index file.
The primary index file would contain pointers to secondary index tiles, which
would point to the actual data items.
Related Topics