Chapter: Operating Systems : File Systems
Disk Scheduling and Management
DISK
SCHEDULING AND MANAGEMENT
1. Disk
scheduling
1.1 FCFS Scheduling
1.2 SSTF
(shortest-seek-time-first)Scheduling
Service all the requests close to
the current head position, before moving the head far away to service other
requests. That is selects the request with the minimum seek time from the
current
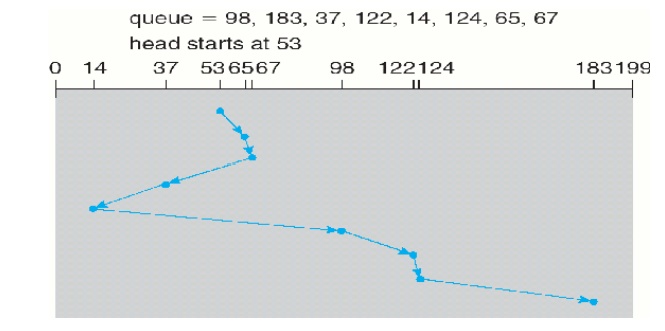
head position.
1.3 SCAN Scheduling
The disk head starts at one end of the disk, and moves toward
the other end, servicing requests as it reaches each cylinder, until it gets to
the other end of the disk. At the other end, the direction of head movement is
reversed, and servicing continues. The head continuously scans back and forth
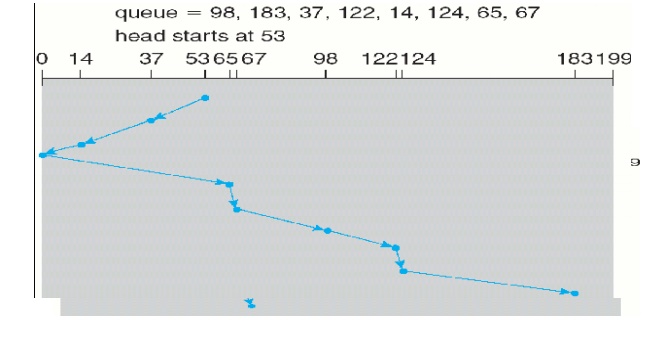
Elevator algorithm: Sometimes
the SCAN algorithm is called as the elevator algorithm, since the disk
arm behaves just like an elevator in a building, first servicing all the
requests going up, and then reversing to service requests the other way.
1.4 C-SCAN Scheduling
Variant of SCAN designed to
provide a more uniform wait time. It moves the head from one end of the disk to
the other, servicing requests along the way. When the head reaches the other
end, however, it immediately returns to the beginning of the disk, without
servicing any requests on the return trip.
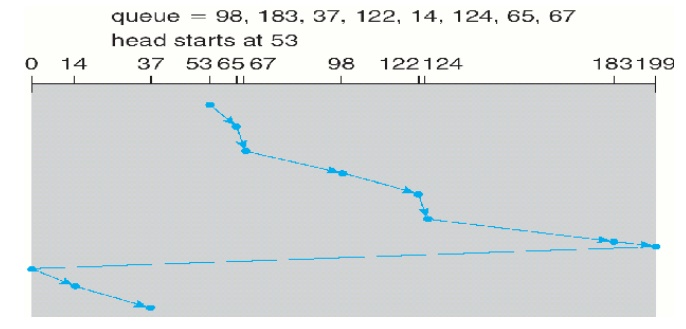
1.5 LOOK Scheduling
Both SCAN and C-SCAN move the disk arm across the full width
of the disk. In this, the arm goes only as far as the final request in each
direction. Then, it reverses direction immediately, without going all the way
to the end of the disk.
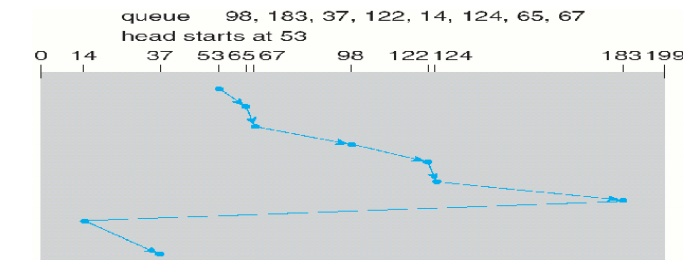
2. Disk Management
Disk Formatting:
Low-level formatting or physical formatting:
ü Before a
disk can store data, the sector is divided into various partitions. This
process is called low-level formatting or physical formatting. It fills the
disk with a special data structure for each sector.
ü The data
structure for a sector consists of
o Header,
o Data area (usually 512 bytes in
size), and
Ø
Trailer.
v The
header and trailer contain information used by the disk controller, such as a
sector number and an error-correcting code (ECC).
v This
formatting enables the manufacturer to
Ø
Test the disk and
To initialize the mapping from logical block numbers
· To use a
disk to hold files, the operating system still needs to record its own data
structures on the disk. It does so in two steps.
(a)
The first step is Partition the disk into one or
more groups of cylinders. Among the partitions, one partition can hold a copy
of the OS‘s executable code, while another holds user
files.
(b) The
second step is logical formatting .The operating system stores the initial
file-system data structures onto the disk. These data structures may include
maps of free and allocated space and an initial empty directory.
Boot Block:
1 For a
computer to start running-for instance, when it is powered up or rebooted-it
needs to have an initial program to run. This initial progr am is called
bootstrap program & it should be simple. It initializes all aspects of the
system, from CPU registers to device controllers and the contents of main
memory, and then starts the operating system.
1 To do its
job, the bootstrap program
ü Finds the
operating system kernel on disk,
ü Loads
that kernel into memory, and
ü Jumps to
an initial address to begin the operating-system execution.
Advantages:
ü ROM needs
no initialization.
ü It is at
a fixed location that the processor can start executing when powered up or
reset.
3. It cannot be
infected by a computer virus. Since, ROM is read only.
ü The full
bootstrap program is stored in a partition called the boot blocks, at a fixed
location on the disk. A disk that has a boot partition is called a boot disk or
system disk.
ü The code
in the boot ROM instructs the disk controller to read the boot blocks into
memory and then starts executing that code.
ü Bootstrap
loader: load the entire operating system from a non-fixed location on disk, and
to start the operating system running.
Bad Blocks:
1 The disk
with defected sector is called as bad block.
1Depending
on the disk and controller in use, these blocks are handled in a variety of
ways;
Method 1:
“Handled
manually
§ If blocks
go bad during normal operation, a special program must be run manually to
search for the bad blocks and to lock them away as before. Data that resided on
the bad blocks usually are lost.
Method 2:
“sector
sparing or forwarding”
The
controller maintains a list of bad blocks on the disk. Then the controller can
be told to replace each bad sector logically with one of the spare sectors.
This scheme is known as sector sparing or forwarding.
ü A typical
bad-sector transaction might be as follows:
ü The oper
ating system tries to read logical block 87.
ü The
controller calculates the ECC and finds that the sector is bad.
ü It
reports this finding to the operating system.
ü
The next time that the system is rebooted, a
special command is run to tell the controller to replace the bad sector with a
spare.
ü After
that, whenever the system requests logical block 87, the request is translated
into the
replacement
sector's address by the controller.
Method 3: “sector
slipping”
ü For an
example, suppose that logical block 17 becomes defective, and the first
available spare follows sector 202. Then, sector slipping would remap all the
sectors from 17 to 202,moving them all down one spot. That is, sector 202 would
be copied into the spare, then sector 201 into 202, and then 200 into 201, and
so on, until sector 18 is copied into sector 19. Slipping the sectors in this
way frees up the space of sector 18, so sector 17 can be mapped to it.
Related Topics