Chapter: Fundamentals of Database Systems : Conceptual Modeling and Database Design : The Enhanced Entity-Relationship (EER) Model
Data Abstraction, Knowledge Representation, and Ontology Concepts
Data Abstraction, Knowledge Representation, and Ontology Concepts
In this section we discuss in general terms some of the modeling
concepts that we described quite specifically in our presentation of the ER and
EER models in Chapter 7 and earlier in this chapter. This terminology is not
only used in conceptual data modeling but also in artificial intelligence
literature when discussing knowledge
representation (KR). This
section discusses the similarities and differences between conceptual modeling
and knowledge representation, and introduces some of the alternative
terminology and a few additional concepts.
The goal of KR techniques is to develop concepts for accurately modeling
some domain of knowledge by creating
an ontology that describes the concepts of
the domain and how these concepts
are interrelated. Such an ontology is used to store and manipulate knowledge
for drawing inferences, making decisions, or answering questions. The goals of
KR are similar to those of semantic data models, but there are some important
similarities and differences between the two disciplines:
Both disciplines use an
abstraction process to identify common properties and important aspects of
objects in the miniworld (also known as domain
of discourse in KR) while
suppressing insignificant differences and unimportant details.
Both disciplines provide
concepts, relationships, constraints, operations, and languages for defining
data and representing knowledge.
KR is generally broader in scope
than semantic data models. Different forms of knowledge, such as rules (used in
inference, deduction, and search), incomplete and default knowledge, and
temporal and spatial knowledge, are represented in KR schemes. Database models
are being expanded to include some of these concepts (see Chapter 26).
KR schemes include reasoning mechanisms that deduce
additional facts from the facts stored in a database. Hence, whereas most
current database systems are limited to answering direct queries,
knowledge-based systems using KR schemes can answer queries that involve inferences over the stored data.
Database technology is being extended with inference mechanisms (see Section
26.5).
Whereas most data models concentrate on the representation of database
schemas, or meta-knowledge, KR schemes often mix up the schemas with the
instances themselves in order to provide flexibility in representing
exceptions. This often results in inefficiencies when these KR schemes are
implemented, especially when compared with databases and when a large amount
of data (facts) needs to be stored.
We now discuss four abstraction
concepts that are used in semantic data models, such as the EER model as
well as in KR schemes: (1) classification and instantiation,
(2) identification, (3) specialization and generalization, and (4)
aggregation and association. The paired concepts of classification and
instantiation are inverses of one another, as are generalization and
specialization. The concepts of aggregation and association are also related.
We discuss these abstract concepts and their relation to the concrete
representations used in the EER model to clarify the data abstraction process
and to improve our understanding of the related process of conceptual schema
design. We close the section with a brief discussion of ontology, which is being used widely in recent knowledge
representation research.
1. Classification and
Instantiation
The process of classification
involves systematically assigning similar objects/entities to object
classes/entity types. We can now describe (in DB) or reason about (in KR) the
classes rather than the individual objects. Collections of objects that share
the same types of attributes, relationships, and constraints are classified
into classes in order to simplify the process of discovering their properties. Instantiation is the inverse of
classification and refers to the generation and specific examination of
distinct objects of a class. An object instance is related to its object class
by the IS-AN-INSTANCE-OF or IS-A-MEMBER-OF relationship. Although
EER diagrams do not display
instances, the UML diagrams allow a form of instantiation by permit-ting the
display of individual objects. We did not
describe this feature in our introduction to UML class diagrams.
In general, the objects of a class should have a similar type structure.
However, some objects may display properties that differ in some respects from
the other objects of the class; these exception
objects also need to be modeled, and KR schemes allow more varied
exceptions than do database models. In addition, certain properties apply to
the class as a whole and not to the individual objects; KR schemes allow such class properties. UML diagrams also
allow specification of class properties.
In the EER model, entities are classified into entity types according to
their basic attributes and relationships. Entities are further classified into
subclasses and categories based on additional similarities and differences
(exceptions) among them. Relationship instances are classified into
relationship types. Hence, entity types, subclasses, categories, and
relationship types are the different concepts that are used for classification
in the EER model. The EER model does not provide explicitly for class
properties, but it may be extended to do so. In UML, objects are classified
into classes, and it is possible to display both class properties and
individual objects.
Knowledge representation models allow multiple classification schemes in
which one class is an instance of
another class (called a meta-class).
Notice that this cannot be
represented directly in the EER model, because we have only two levels—classes
and instances. The only relationship among classes in the EER model is a
super-class/subclass relationship, whereas in some KR schemes an additional
class/instance relationship can be represented directly in a class hierarchy.
An instance may itself be another class, allowing multiple-level classification
schemes.
2. Identification
Identification is the abstraction process whereby classes and objects are made uniquely identifiable by means of some
identifier. For example, a class
name uniquely identifies a whole class within a schema. An additional mechanism
is necessary for telling distinct object instances apart by means of object
identifiers. Moreover, it is necessary to identify multiple manifestations in
the database of the same real-world object. For example, we may have a tuple
<‘Matthew Clarke’, ‘610618’, ‘376-9821’> in a PERSON relation and another tuple <‘301-54-0836’, ‘CS’, 3.8> in a STUDENT relation that happen to represent the same real-world entity. There is
no way to identify the fact that these two database objects (tuples) represent
the same real-world entity unless we make a provision at design time for appropriate cross-referencing to supply this
identification. Hence, identification is needed at two levels:
To distinguish among database
objects and classes
To identify database objects and
to relate them to their real-world counter-parts
In the EER model, identification of schema constructs is based on a
system of unique names for the constructs in a schema. For example, every class
in an EER schema—whether it is an entity type, a subclass, a category, or a
relationship type— must have a distinct name. The names of attributes of a
particular class must also be distinct. Rules for unambiguously identifying
attribute name references in a special-ization or generalization lattice or
hierarchy are needed as well.
At the object level, the values of key attributes are used to
distinguish among entities of a particular entity type. For weak entity types,
entities are identified by a combination of their own partial key values and
the entities they are related to in the owner entity type(s). Relationship
instances are identified by some combination of the entities that they relate
to, depending on the cardinality ratio specified.
3. Specialization and
Generalization
Specialization is the process of classifying a class of objects into more specialized subclasses. Generalization is the inverse process of generalizing several
classes into a higher-level abstract class that includes the objects in all
these classes. Specialization is conceptual refinement, whereas generalization
is conceptual syn-thesis. Subclasses are used in the EER model to represent
specialization and general-ization. We call the relationship between a subclass
and its superclass an IS-A-SUBCLASS-OF relationship,
or simply an IS-A relationship. This
is the same as the IS-A relationship
discussed earlier in Section 8.5.3.
4. Aggregation and
Association
Aggregation is an abstraction concept for building composite objects from their component objects. There are three
cases where this concept can be related to the EER model. The first case is the
situation in which we aggregate attribute values of an object to form the whole
object. The second case is when we represent an aggregation relationship as an
ordinary relationship. The third case, which the EER model does not provide for
explicitly, involves the possibility of combining objects that are related by a
particular relationship instance into a higher-level
aggregate object. This is
sometimes useful when the higher-level aggregate object is itself to be related to another object. We call the
relationship between the primitive objects and their aggregate object IS-A-PART-OF; the inverse is called IS-A-COMPONENT-OF. UML provides for all
three types of aggregation.
The abstraction of association
is used to associate objects from several independent
classes. Hence, it is somewhat
similar to the second use of aggregation. It is represented in the EER model
by relationship types, and in UML by associations. This abstract relationship
is called IS-ASSOCIATED-WITH.
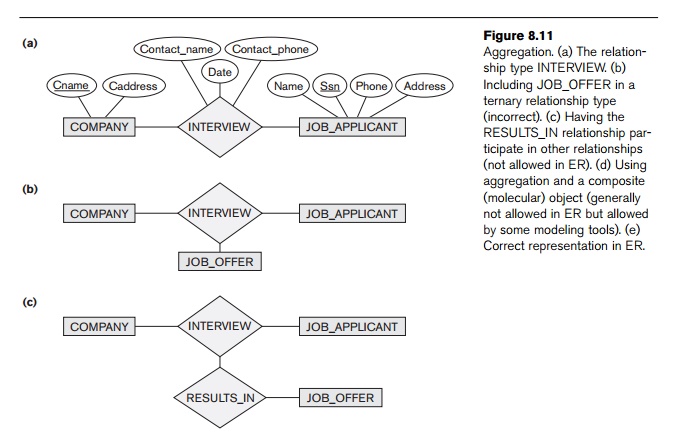
In order to understand the different uses of aggregation better,
consider the ER schema shown in Figure 8.11(a), which stores information about
interviews by job applicants to various companies. The class COMPANY is an aggregation of the attributes (or component objects) Cname (company name) and Caddress (company address), whereas JOB_APPLICANT is an aggregate of Ssn, Name, Address, and Phone. The relationship attributes Contact_name and Contact_phone represent the name and phone number of the person in the company who is
responsible for the inter-view. Suppose that some interviews result in job
offers, whereas others do not. We would like to treat INTERVIEW as a class to associate it with JOB_OFFER. The
schema shown in Figure 8.11(b) is incorrect
because it requires each interview rela-tionship instance to have a job offer.
The schema shown in Figure 8.11(c) is not
allowed because the ER model does not
allow relationships among relationships.
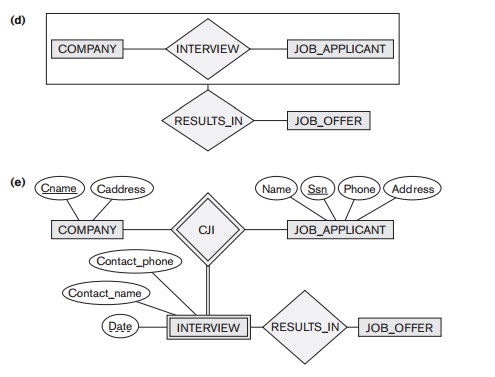
One way to represent this situation is to create a higher-level
aggregate class com-posed of COMPANY, JOB_APPLICANT, and INTERVIEW and to relate this class to JOB_OFFER, as
shown in Figure 8.11(d). Although the EER model as described in this book does not have this facility, some semantic data models do
allow it and call the resulting object a composite
or molecular object. Other models
treat entity types and relationship types uniformly and hence permit
relationships among relationships, as illustrated in Figure 8.11(c).
To represent this situation correctly in the ER model as described here,
we need to create a new weak entity type INTERVIEW, as
shown in Figure 8.11(e), and relate it to JOB_OFFER. Hence,
we can always represent these situations correctly in the ER model by creating additional entity types, although it may be
conceptually more desirable to allow direct representation of aggregation, as
in Figure 8.11(d), or to allow relationships among relationships, as in Figure
8.11(c).
The main structural distinction between aggregation and association is
that when an association instance is deleted, the participating objects may
continue to exist. However, if we support the notion of an aggregate object—for
example, a CAR that is made up of objects ENGINE, CHASSIS, and TIRES—then deleting the aggregate CAR object
amounts to deleting all its component objects.
5. Ontologies and the
Semantic Web
In recent years, the amount of computerized data and information
available on the Web has spiraled out of control. Many different models and
formats are used. In addition to the database models that we present in this
book, much information is stored in the form of documents, which have considerably less structure than data-base
information does. One ongoing project that is attempting to allow information
exchange among computers on the Web is called the Semantic Web, which attempts to create knowledge representation
models that are quite general in order to allow meaningful information exchange
and search among machines. The concept of ontology
is considered to be the most promising basis for achieving the goals of the Semantic Web and is closely related to
knowledge representation. In this section, we give a brief introduction to what
ontology is and how it can be used as a basis to automate information
understanding, search, and exchange.
The study of ontologies attempts to describe the structures and relationships that are possible in reality through some common vocabulary; therefore, it can be considered as a way to describe the knowledge of a certain community about reality. Ontology originated in the fields of philosophy and metaphysics. One commonly used definition of ontology is a specification of a conceptualization.
In this definition, a conceptualization
is the set of concepts that are used to represent the part of reality or
knowledge that is of interest to a community of users. Specification refers to the language and vocabulary terms that are
used to specify the
conceptualization. The ontology includes both specification and conceptualization.
For example, the same conceptualization may be specified in two different languages, giving two
separate ontologies. Based on this quite general definition, there is no consensus
on what an ontology is exactly. Some possible ways to describe ontologies are
as follows:
A thesaurus (or even a dictionary
or a glossary of terms) describes
the rela-tionships between words (vocabulary) that represent various concepts.
A taxonomy describes how concepts of a particular area of knowledge
are related using structures similar to those used in a specialization or
general-ization.
A detailed database schema is considered by some to be an ontology that
describes the concepts (entities and attributes) and relationships of a
mini-world from reality.
A logical theory uses concepts from mathematical logic to try to
define concepts and their interrelationships.
Usually the concepts used to describe ontologies are quite similar to
the concepts we discussed in conceptual modeling, such as entities, attributes,
relationships, specializations, and so on. The main difference between an
ontology and, say, a database schema, is that the schema is usually limited to
describing a small subset of a mini world from reality in order to store and
manage data. An ontology is usually consid-ered to be more general in that it
attempts to describe a part of reality or a domain of interest (for example,
medical terms, electronic-commerce applications, sports, and so on) as
completely as possible.
Related Topics