Chapter: Fundamentals of Database Systems : Conceptual Modeling and Database Design : The Enhanced Entity-Relationship (EER) Model
Constraints and Characteristics of Specialization and Generalization Hierarchies
Constraints and Characteristics of Specialization and Generalization
Hierarchies
First, we discuss constraints that apply to a single specialization or a
single generalization. For brevity, our discussion refers only to specialization even though it applies to
both specialization and generalization.
Then, we discuss differences between specialization/generalization lattices (multiple inheritance) and hierarchies
(single inheritance), and elaborate
on the differences between the specialization and generalization processes
during conceptual database schema design.
1. Constraints on
Specialization and Generalization
In general, we may have several specializations defined on the same
entity type (or superclass), as shown in Figure 8.1. In such a case, entities
may belong to subclasses in each of the specializations. However, a
specialization may also consist of a single
subclass only, such as the {MANAGER} specialization in Figure 8.1;
in such a case, we do not use the circle notation.
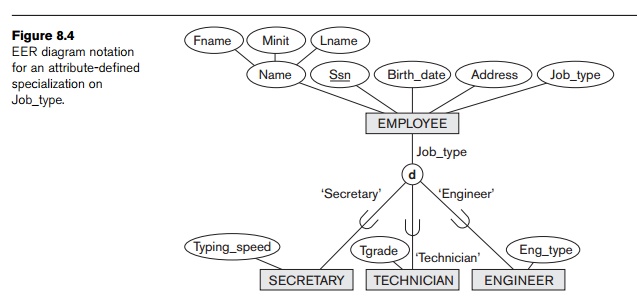
In some specializations we can determine exactly the entities that will
become members of each subclass by placing a condition on the value of some
attribute of the superclass. Such subclasses are called predicate-defined (or condition-defined)
subclasses. For example, if the EMPLOYEE entity
type has an attribute Job_type, as shown in Figure 8.4, we
can specify the condition of membership in the SECRETARY subclass
by the condition (Job_type
= ‘Secretary’), which we call the defining predicate of the subclass. This condition is a
constraint specifying that exactly
those entities of the EMPLOYEE entity type whose attribute
value for Job_type
is ‘Secretary’ belong to the subclass. We display a
predicate-defined subclass by writing the predicate
condition next to the line that connects the subclass to the specialization circle.
If all subclasses in a
specialization have their membership condition on the same attribute of the superclass, the specialization itself is
called an attribute-defined
specialization, and the attribute is called the defining attribute of the specialization. In this case, all the entities with the same value for the attribute
belong to the same sub-class. We display an attribute-defined specialization by
placing the defining attribute name next to the arc from the circle to the
superclass, as shown in Figure 8.4.
When we do not have a condition for determining membership in a
subclass, the subclass is called user-defined.
Membership in such a subclass is determined by the database users when they
apply the operation to add an entity to the subclass; hence, membership is specified individually for each entity by
the user, not by any condition that may be evaluated automatically.
Two other constraints may apply to a specialization. The first is the disjointness (or disjointedness) constraint, which specifies that the subclasses of
the specialization must be disjoint.
This means that an entity can be a member of at most one of the subclasses of the specialization. A
specialization that is attribute-defined implies the disjointness constraint
(if the attribute used to define the membership predicate is single-valued).
Figure 8.4 illustrates this case, where the d in the circle stands for disjoint.
The d notation also applies
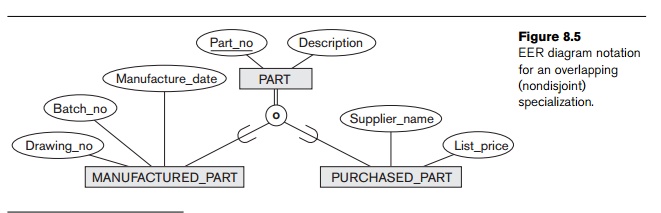
to user-defined subclasses of a specialization that must be disjoint, as illustrated by the specialization {HOURLY_EMPLOYEE, SALARIED_EMPLOYEE} in Figure 8.1. If the subclasses are not constrained to be dis-joint,
their sets of entities may be overlapping;
that is, the same (real-world) entity may be a member of more than one subclass
of the specialization. This case, which is the default, is displayed by placing
an o in the circle, as shown in
Figure 8.5.
The second constraint on specialization is called the completeness (or totalness) constraint,
which may be total or partial. A total
specialization constraint specifies that
every entity in the superclass must
be a member of at least one subclass in the specialization. For example, if
every EMPLOYEE must be either an
HOURLY_EMPLOYEE or a
SALARIED_EMPLOYEE, then the specialization {HOURLY_EMPLOYEE, SALARIED_EMPLOYEE} in Figure 8.1 is a total specialization of EMPLOYEE. This is shown in EER diagrams by using a double line to connect the
superclass to the circle. A single line is used to display a partial specialization, which allows an
entity not to belong to any of the subclasses. For example, if some EMPLOYEE entities do not belong to any of the subclasses {SECRETARY,
ENGINEER, TECHNICIAN} in
Figures 8.1 and 8.4, then that specialization is partial.
Notice that the disjointness and completeness constraints are independent. Hence, we have the
following four possible constraints on specialization:
Disjoint, total
Disjoint, partial
Overlapping, total
Overlapping, partial
Of course, the correct constraint is determined from the real-world
meaning that applies to each specialization. In general, a superclass that was
identified through the generalization
process usually is total, because
the superclass is derived from the
subclasses and hence contains only the entities that are in the subclasses.
Certain insertion and deletion rules apply to specialization (and
generalization) as a consequence of the constraints specified earlier. Some of
these rules are as follows:
Deleting an entity from a superclass
implies that it is automatically deleted from all the subclasses to which it
belongs.
Inserting an entity in a
superclass implies that the entity is mandatorily inserted in all predicate-defined (or attribute-defined) subclasses for which
the entity satisfies the defining predicate.
Inserting an entity in a
superclass of a total specialization
implies that the entity is mandatorily inserted in at least one of the
subclasses of the specialization.
The reader is encouraged to make a complete list of rules for insertions
and dele-tions for the various types of specializations.
2. Specialization and Generalization Hierarchies and Lattices
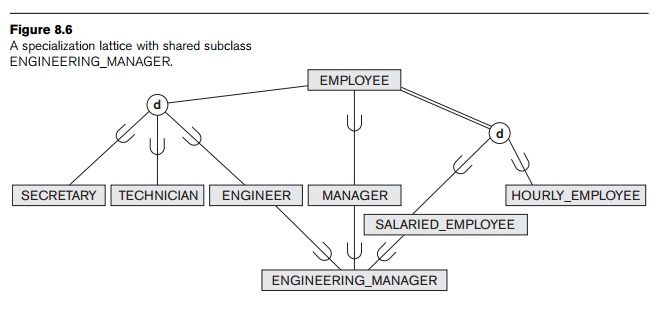
A subclass itself may have further subclasses specified on it, forming a
hierarchy or a lattice of specializations. For example, in Figure 8.6 ENGINEER is a subclass of EMPLOYEE and is also a superclass of ENGINEERING_MANAGER; this represents the real-world constraint that
every engineering manager is required to be an engineer. A specialization hierarchy has the constraint
that every subclass participates as a
subclass in only one class/subclass
relationship; that is, each subclass has only
one parent, which results in a tree
structure or strict hierarchy.
In contrast, for a specialization lattice,
a subclass can be a subclass in more than one class/subclass relationship.
Hence, Figure 8.6 is a lattice.
Figure 8.7 shows another specialization lattice of more than one level.
This may be part of a conceptual schema for a UNIVERSITY
database. Notice that this arrange-ment would have been a hierarchy except for
the STUDENT_ASSISTANT subclass, which is a subclass in two distinct class/subclass
relationships.
The requirements for the part of the UNIVERSITY database
shown in Figure 8.7 are the following:
The database keeps track of three
types of persons: employees, alumni, and students. A person can belong to one,
two, or all three of these types. Each person has a name, SSN, sex, address,
and birth date.
Every employee has a salary, and there are three types of employees:
faculty, staff, and student assistants. Each employee belongs to exactly one of
these types. For each alumnus, a record of the degree or degrees that he or she
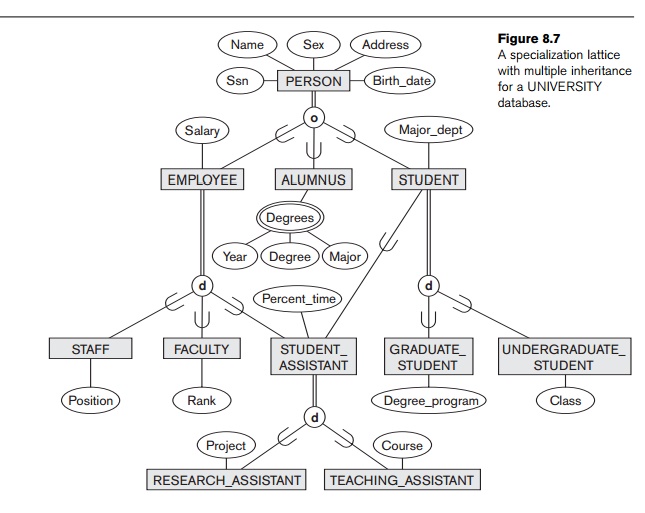
earned at the university is kept, including the name of the degree, the
year granted, and the major department. Each student has a major department.
Each faculty has a rank, whereas
each staff member has a staff position. Student assistants are classified
further as either research assistants or teach-ing assistants, and the percent
of time that they work is recorded in the data-base. Research assistants have
their research project stored, whereas teaching assistants have the current
course they work on.
Students are further classified
as either graduate or undergraduate, with the specific attributes degree
program (M.S., Ph.D., M.B.A., and so on) for graduate students and class
(freshman, sophomore, and so on) for under-graduates.
In Figure 8.7, all person entities represented in the database are
members of the PERSON
entity type, which is specialized into the
subclasses {EMPLOYEE,
ALUMNUS, STUDENT}. This
specialization is overlapping; for example, an alumnus may also be an employee and may also be a student pursuing an advanced
degree. The subclass STUDENT is the superclass for the
specialization {GRADUATE_STUDENT, UNDERGRADUATE_STUDENT}, while EMPLOYEE is the superclass for the specialization {STUDENT_ASSISTANT, FACULTY, STAFF}. Notice that STUDENT_ASSISTANT is also a subclass of STUDENT. Finally, STUDENT_ASSISTANT
is the superclass for the specialization into
{RESEARCH_ASSISTANT, TEACHING_ASSISTANT}.
In such a specialization lattice or hierarchy, a subclass inherits the
attributes not only of its direct superclass, but also of all its predecessor
superclasses all the way to the root of the hierarchy or lattice if
necessary. For example, an entity in GRADUATE_STUDENT inherits all the attributes of that entity as a STUDENT and as
a PERSON. Notice that an entity may exist
in several leaf nodes of the
hierarchy, where a leaf node is a
class that has no subclasses of its own.
For example, a member of GRADUATE_STUDENT may also be a member of RESEARCH_ASSISTANT.
A subclass with more than one
superclass is called a shared subclass,
such as ENGINEERING_MANAGER
in Figure 8.6. This leads to the concept known as multiple inheritance, where the shared subclass ENGINEERING_MANAGER directly inherits attributes
and relationships from multiple classes. Notice that the existence of at least
one shared subclass leads to a lattice (and hence to multiple inheritance); if no shared subclasses existed, we would
have a hierarchy rather than a lattice and only single inheritance would exist. An important rule related to
multiple inheri-tance can be illustrated by the example of the shared subclass STUDENT_ASSISTANT in Figure 8.7, which inherits attributes from both EMPLOYEE and STUDENT. Here, both EMPLOYEE and STUDENT inherit the same attributes
from PERSON. The rule states that if an attribute (or relationship) originating in
the same superclass (PERSON) is inherited more than once via different paths (EMPLOYEE and STUDENT) in the lattice, then it should be included only once in the shared
subclass
(STUDENT_ASSISTANT). Hence, the attributes of PERSON are inherited only once in
the STUDENT_ASSISTANT subclass in Figure 8.7.
It is important to note here that some models and languages are limited
to single inheritance and do not allow multiple inheritance (shared subclasses). It is also important to note that some models do
not allow an entity to have multiple types, and hence an entity can be a member
of only one leaf class.8 In such a model, it is necessary
to create additional subclasses as leaf nodes to cover all possible
combina-tions of classes that may have some entity that belongs to all these
classes simultane-ously. For example, in the overlapping specialization of PERSON into {EMPLOYEE, ALUMNUS,
STUDENT} (or {E,
A, S} for short), it would be
necessary to create seven subclasses of PERSON in order to cover all possible types of entities: E, A, S, E_A, E_S,
A_S, and E_A_S.
Obviously, this can lead to extra complexity.
Although we have used specialization to illustrate our discussion,
similar concepts apply equally to
generalization, as we mentioned at the beginning of this section. Hence, we can also speak of generalization hierarchies and generalization lattices.
3. Utilizing Specialization and Generalization in Refining Conceptual
Schemas
Now we elaborate on the differences between the specialization and
generalization processes, and how they are used to refine conceptual schemas
during conceptual database design. In the specialization process, we typically
start with an entity type and then define subclasses of the entity type by
successive specialization; that is, we repeatedly define more specific
groupings of the entity type. For example, when designing the specialization
lattice in Figure 8.7, we may first specify an entity type PERSON for a university database. Then we discover that three types of persons
will be represented in the database: university employees, alumni, and
students. We cre-ate the specialization {EMPLOYEE, ALUMNUS, STUDENT} for this purpose and choose the overlapping constraint, because a
person may belong to more than one of the subclasses. We specialize EMPLOYEE further into {STAFF, FACULTY,
STUDENT_ASSISTANT}, and specialize STUDENT into {GRADUATE_STUDENT,
UNDERGRADUATE_STUDENT}. Finally, we specialize STUDENT_ASSISTANT into
{RESEARCH_ASSISTANT, TEACHING_ASSISTANT}. This
successive specialization corresponds to a top-down
conceptual refinement process during conceptual schema design. So far, we
have a hierarchy; then we realize that STUDENT_ASSISTANT is a
shared subclass, since it is also a subclass of STUDENT, leading to the lattice.
It is possible to arrive at the same hierarchy or lattice from the other
direction. In such a case, the process involves generalization rather than
specialization and corresponds to a bottom-up
conceptual synthesis. For example, the database designers may first
discover entity types such as STAFF, FACULTY, ALUMNUS,
GRADUATE_STUDENT,
UNDERGRADUATE_STUDENT, RESEARCH_ASSISTANT,
TEACHING_ASSISTANT, and so on; then they generalize
{GRADUATE_STUDENT, UNDERGRADUATE_STUDENT} into
STUDENT; then they generalize {RESEARCH_ASSISTANT, TEACHING_ASSISTANT} into STUDENT_ASSISTANT; then they generalize {STAFF, FACULTY, STUDENT_ASSISTANT} into EMPLOYEE; and finally they generalize {EMPLOYEE, ALUMNUS, STUDENT} into PERSON.
In structural terms, hierarchies or lattices resulting from either
process may be identical; the only difference relates to the manner or order
in which the schema super-classes and subclasses were created during the design
process. In practice, it is likely that neither the generalization process nor
the specialization process is followed strictly, but that a combination of the
two processes is employed. New classes are continually incorporated into a
hierarchy or lattice as they become apparent to users and designers. Notice
that the notion of representing data and knowledge by using superclass/subclass
hierarchies and lattices is quite common in knowledge-based systems and expert
systems, which combine database technology with artificial intelligence
techniques. For example, frame-based knowledge representation schemes closely
resemble class hierarchies. Specialization is also common in software
engineering design methodologies that are based on the object-oriented
paradigm.
Related Topics