Chapter: Fundamentals of Database Systems : Databases and Database Users
Characteristics of the Database Approach
Characteristics of the Database Approach
A number of characteristics distinguish the database approach from the
much older approach of programming with files. In traditional file processing, each user defines and
implements the files needed for a specific software application as part of
programming the application. For example, one user, the grade reporting office, may keep files on students and their
grades. Programs to print a student’s transcript and to enter new grades are
implemented as part of the application. A second user, the accounting office, may keep track of students’ fees and their
payments. Although both users are
interested in data about students, each user maintains separate files— and
programs to manipulate these files—because each requires some data not available
from the other user’s files. This redundancy in defining and storing data
results in wasted storage space and in redundant efforts to maintain common
up-to-date data.
In the database approach, a single repository maintains data that is
defined once and then accessed by various users. In file systems, each
application is free to name data elements independently. In contrast, in a
database, the names or labels of data are defined once, and used repeatedly by
queries, transactions, and applications. The main characteristics of the
database approach versus the file-processing approach are the following:
Self-describing nature of a
database system
Insulation between programs and
data, and data abstraction
Support of multiple views of the
data
Sharing of data and multiuser
transaction processing
We describe each of these characteristics in a separate section. We will
discuss addi-tional characteristics of database systems in Sections 1.6 through
1.8.
1. Self-Describing
Nature of a Database System
A fundamental characteristic of the database approach is that the
database system contains not only the database itself but also a complete
definition or description of the database structure and constraints. This
definition is stored in the DBMS catalog, which contains information such as
the structure of each file, the type and storage format of each data item, and
various constraints on the data. The information stored in the catalog is
called meta-data, and it describes
the structure of the primary database (Figure 1.1).
The catalog is used by the DBMS software and also by database users who
need information about the database structure. A general-purpose DBMS software
pack-age is not written for a specific database application. Therefore, it must
refer to the catalog to know the structure of the files in a specific database,
such as the type and format of data it will access. The DBMS software must work
equally well with any number of database applications—for
example, a university database, a banking
database, or a company database—as long as the database definition is
stored in the catalog.
In traditional file processing, data definition is typically part of the
application pro-grams themselves. Hence, these programs are constrained to work
with only one specific database, whose structure is declared in the application
programs. For example, an application
program written in C++ may have struct or class declarations, and a COBOL
program has data division statements to define its files. Whereas
file-processing software can access only specific databases, DBMS software can
access diverse databases by extracting the database definitions from the
catalog and using these definitions.
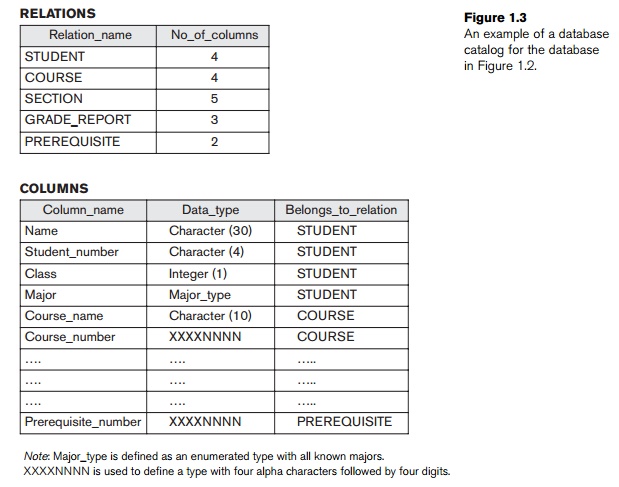
For the example shown in Figure 1.2, the DBMS catalog will store the
definitions of all the files shown. Figure 1.3 shows some sample entries in a
database catalog.
These definitions are specified by the database designer prior to
creating the actual database and are stored in the catalog. Whenever a request
is made to access, say, the Name of a STUDENT record, the DBMS software refers to the catalog to determine the structure of the STUDENT file and the position and size
of the Name data item within a STUDENT record. By contrast, in a
typical file-processing application, the file structure and, in the extreme
case, the exact location of Name within a STUDENT record are already coded within each program that accesses this data
item.
2. Insulation between
Programs and Data, and Data Abstraction
In traditional file processing, the structure of data files is embedded
in the applica-tion programs, so any changes to the structure of a file may
require changing all pro-grams that
access that file. By contrast, DBMS access programs do not require such changes in most cases. The structure of
data files is stored in the DBMS catalog sepa-rately from the access programs. We
call this property program-data
independence.
For example, a file access program may be written in such a way that it
can access only STUDENT records of the structure shown in Figure 1.4. If we want to add another
piece of data to each STUDENT record, say the Birth_date, such a program will no longer work and must be changed. By contrast,
in a DBMS environment, we only need to change the description of STUDENT records in the catalog (Figure 1.3) to reflect the inclusion of the new
data item Birth_date; no programs are changed. The next time a DBMS program refers to the
catalog, the new structure of STUDENT records will be accessed and
used.
In some types of database systems, such as object-oriented and
object-relational systems (see Chapter 11), users can define operations on data
as part of the database definitions. An operation
(also called a function or method) is specified in two parts. The interface (or signature) of an operation includes the operation name and the data
types of its arguments (or parameters). The implementation
(or method) of the operation is
specified separately and can be changed without affecting the interface. User
application programs can operate on the data by invoking these operations
through their names and arguments, regardless of how the operations are
imple-mented. This may be termed program-operation
independence.
The characteristic that allows program-data independence and
program-operation independence is called data
abstraction. A DBMS provides users with a conceptual representation of
data that does not include many of the details of how the data is stored or how the operations are
implemented. Informally, a data model
is a type of data abstraction that is used to provide this conceptual
representation. The data model uses logical concepts, such as objects, their
properties, and their interrela-tionships, that may be easier for most users to
understand than computer storage concepts. Hence, the data model hides storage and implementation details
that are not of interest to most database users.
For example, reconsider Figures 1.2 and 1.3. The internal implementation
of a file may be defined by its record length—the number of characters (bytes)
in each record—and each data item may be specified by its starting byte within
a record and its length in bytes. The STUDENT record
would thus be represented as shown in Figure 1.4. But a typical database user
is not concerned with the location of each data item within a record or its
length; rather, the user is concerned that when a ref-erence is made to Name of STUDENT, the correct value is returned. A conceptual rep-resentation of the STUDENT records is shown in Figure 1.2. Many other details of file storage
organization—such as the access paths specified on a file—can be hidden from
database users by the DBMS; we discuss storage details in Chapters 17 and 18.

In the database approach, the detailed structure and organization of
each file are stored in the catalog. Database users and application programs
refer to the concep-tual representation of the files, and the DBMS extracts the
details of file storage from the catalog when these are needed by the DBMS file
access modules. Many data models can be used to provide this data abstraction
to database users. A major part of this book is devoted to presenting various
data models and the concepts they use to abstract the representation of data.
In object-oriented and object-relational databases, the abstraction
process includes not only the data structure but also the operations on the
data. These operations provide an abstraction of miniworld activities commonly
understood by the users. For example, an operation CALCULATE_GPA can be applied to a STUDENT object to calculate the grade
point average. Such operations can be invoked by the user queries or
application programs without having to know the details of how the operations
are implemented. In that sense, an abstraction of the miniworld activity is
made available to the user as an abstract
operation.
3. Support of Multiple
Views of the Data
A database typically has many users, each of whom may require a
different perspective or view of
the database. A view may be a subset of the database or it may contain virtual data that is derived from the
database files but is not explicitly stored. Some users may not need to be
aware of whether the data they refer to is stored or derived. A multiuser DBMS
whose users have a variety of distinct applications must provide facilities for
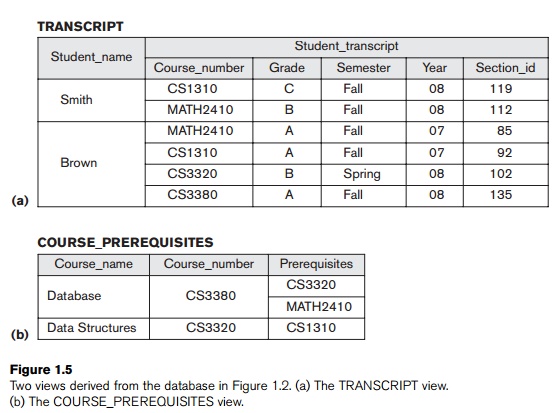
defining multiple views. For example, one user of the database of Figure 1.2
may be interested only in accessing and printing the transcript of each
student; the view for this user is shown in Figure 1.5(a). A second user, who
is interested only in checking that students have taken all the prerequisites
of each course for which they register, may require the view shown in Figure
1.5(b).
4. Sharing of Data and
Multiuser Transaction Processing
A multiuser DBMS, as its name implies, must allow multiple users to
access the data-base at the same time. This is essential if data for multiple
applications is to be inte-grated and maintained in a single database. The DBMS
must include concurrency control software to ensure that several
users trying to update the same data do so in a controlled manner so that the result of the updates is correct.
For example, when several reservation agents try to assign a seat on an airline
flight, the DBMS should ensure that each seat can be accessed by only one agent
at a time for assignment to a passenger. These types of applications are generally
called online transaction pro-cessing
(OLTP) applications. A fundamental role of multiuser DBMS software is to ensure that concurrent transactions
operate correctly and efficiently.
The concept of a transaction
has become central to many database applications. A transaction is an executing program or process that includes one or more
database accesses, such as reading or updating of database records. Each
transaction is sup-posed to execute a logically correct database access if
executed in its entirety without interference from other transactions. The DBMS
must enforce several transaction
properties. The isolation
property ensures that each transaction appears to execute in isolation from
other transactions, even though hundreds of transactions may be executing
concurrently. The atomicity property
ensures that either all the database operations in a transaction are executed
or none are. We discuss transactions in detail in Part 9.
The preceding characteristics are important in distinguishing a DBMS
from tradi-tional file-processing software. In Section 1.6 we discuss
additional features that characterize a DBMS. First, however, we categorize the
different types of people who work in a database system environment.
Related Topics