Chapter: XML and Web Services : Building XML-Based Applications : Parsing XML Using Document Object Model
DOM Core
DOM Core
The DOM core is available in DOM Level 1 and beyond. It permits you to
create and manipulate XML documents in memory. As mentioned earlier, DOM is a
tree structure that represents elements, attributes, and content. As an
example, let’s consider a simple XML document, as shown in Listing 7.1.
LISTING 7.1 Simple XML Document
<purchase-order>
<customer>James Bond</customer>
<merchant>Spies R Us</merchant>
<items>
<item>Night vision camera</item>
<item>Vibrating
massager</item>
</items>
</purchase-order>
Figure 7.1 shows a diagram of the tree structure representing the XML
document from Listing 7.1.
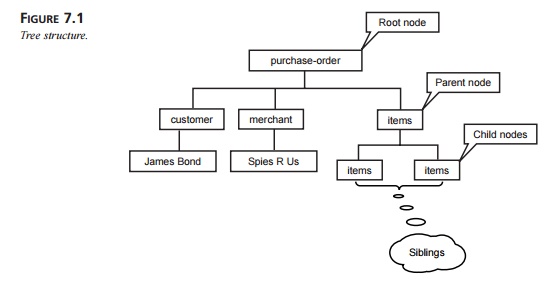
As you can see, elements and text in the XML
document are represented by nodes in the tree structure. A node is an abstract concept that can take the form of an element,
attribute, text, or some other information.
Parents, Children, and Siblings
In formal computer science literature, lots of
different terms are used to describe the parts of a tree structure. You may
have run into words such as root, branches, and leaves. This is a bit abstract and doesn’t describe relationships
very well, so the DOM specifica-tion uses the words parents, children, and siblings to represent nodes and their
relation-ships to one another.
Parent nodes may have zero or more child nodes. Parent nodes themselves
may be the child nodes of another parent node. The ultimate parent of all nodes
is, of course, the root node.
Siblings represent the child nodes of the same parent. These abstract
descrip-tions of nodes are mapped to elements, attributes, text, and other
information in an XML document.
DOM interfaces contain methods for obtaining the parent, children, and
siblings of any node. The root node has no parent, and there will be nodes that
have no children or sib-lings. After all, the tree has to start and end
somewhere!
DOM Interfaces
As mentioned earlier, the DOM interfaces are defined in IDL so that they
are language neutral. The DOM specification goes into excruciating detail with
respect to the inter-faces. Of course, it must—what good is a spec if it is
incomplete? A few fundamental interfaces are the most important. If you
understand how these interfaces work, you can solve most problems without
learning the entire spec inside and out.
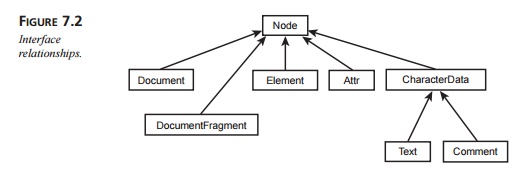
The fundamental interfaces are listed in Table 7.1, along with a brief
description of each.
TABLE 7.1 Fundamental Interfaces

The diagram in Figure 7.2 shows the relationships among the interfaces
described in Table 7.1.
A number of extended interfaces are not mandatory but may be available
in some imple-mentations. These interfaces are beyond DOM Level 1 and are
discussed later in this chapter. You can determine whether these interfaces are
supported by calling the hasFeature() method of the DOMImplementation interface. You can use the arguments “XML” and “2.0” for the feature and version parameters of the hasFeature() method. For a detailed
explanation, refer to the DOM specification on the W3C Web site.
The extended interfaces are listed in Table 7.2, along with a brief
description of each.
TABLE 7.2 Extended Interfaces
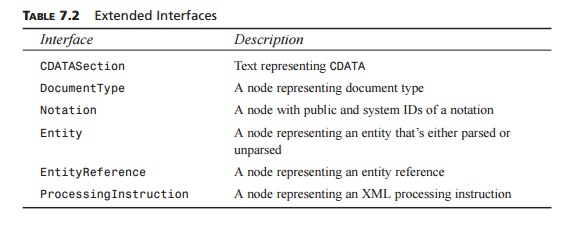
Interface : Description
CDATASection : Text representing CDATA
DocumentType : A node representing document type
Notation : A node with public and system IDs of a notation
Entity : A node representing an entity that’s either parsed or unparsed
EntityReference : A node representing an entity reference
ProcessingInstruction : A node representing an XML processing
instruction
Java Bindings
The DOM working group supplies Java language bindings as part of the DOM
specifica-tion. The specification and Java language bindings are available at
the W3C Web site. These bindings are sets of Java source files containing Java
interfaces, and they map exactly to the DOM interfaces described earlier. The
package org.w3c.dom contains the Java interfaces but does not include a usable
implementation. In order to make the inter-faces do something useful, you will
need an implementation, or a parser.
A number of DOM implementations are available for Java. Two of the most
popular are Java APIs for XML Processing (JAXP), developed by Sun Microsystems,
and Xerces, developed as part of the Apache XML project. Both JAXP and Xerces
are freely avail-able in source and binary (.class) form. JAXP is available on the Sun Web site at http://java.sun.com/xml/xml_jaxp.html, and
Xerces is available on the XML Apache
Web site at http://xml.apache.org/xerces2-j/index.html.
Walking Through an XML Document
Let’s look at an example in which we load an XML document from disk and
print out some of its contents. This example will help you understand how the
API works and how to traverse nodes in a number of ways. In the first example,
we will print out just the ele-ment names using getNodeName() from the Node interface. We will start from the root and recursively print all child
node names, indenting for clarity. The source code for SimpleWalker.java is shown in Listing 7.2.
LISTING 7.2 SimpleWalker.java
package
com.madhu.xml;
import
java.io.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public
class SimpleWalker {
protected DocumentBuilder docBuilder;
protected Element root;
public
SimpleWalker() throws Exception
{
DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance();
docBuilder = dbf.newDocumentBuilder();
DOMImplementation domImp = docBuilder.getDOMImplementation();
if (domImp.hasFeature(“XML”,
“2.0”)) {
System.out.println(“Parser supports
extended interfaces”);
}
}
public
void parse(String fileName)
throws Exception {
Document doc = docBuilder.parse(new FileInputStream(fileName)); root =
doc.getDocumentElement();
System.out.println(“Root
element is “
+ root.getNodeName());
}
public void printAllElements()
throws Exception { printElement(“”, root);
}
public void printElement(String
indent, Node aNode) {
System.out.println(indent +
“<” + aNode.getNodeName() + “>”);
Node child =
aNode.getFirstChild();
while (child != null) {
printElement(indent + “\t”, child);
child = child.getNextSibling();
}
System.out.println(indent + “</”
+ aNode.getNodeName() +
“>”);
}
public static void main(String
args[]) throws Exception {
SimpleWalker sw = new
SimpleWalker();
sw.parse(args[0]);
sw.printAllElements();
}
}
Looking at the code, the first thing we need to do is import the
necessary packages. We need the DOM package, which is in org.w3c.dom, and we also need the javax.xml. parsers package. The DOM package we know about, but the javax.xml.parsers pack-age is different. It’s not
part of the W3C DOM specification at all. It contains two critical classes for
DOM: DocumentBuilder and DocumentBuilderFactory. These classes are needed
because the DOM interfaces do not provide a way to load or create documents;
this is up to the implementation. The javax.xml.parsers package is part of Java API for XML Processing (JAXP) and is defined
through the Java Community Process (JCP JSR-005). Details on JSR-005 can be
found at http://jcp.org/jsr/detail/005.jsp. Apache Xerces includes this package as part of the distribution. The
classes in the javax.xml.parsers package are implementation independent, so it is possible to write application code that is
completely separate from a particular DOM implementation. If you find a better
implementation tomorrow, you can plug it in without changing your application
code.
Execution begins at the main method, which will create an instance of
our SimpleWalker class
and call a couple of its methods to do the work. There are several methods in
the DocumentBuilder class (javax.xml.parsers package) for loading and parsing
an
XML file. You can supply a java.io.File, an InputStream, or other source. We will use FileInputStream to load our file, but first we need to get an instance of DocumentBuilder, which is an abstract class, so
we can’t create an instance directly.
That’s the job of DocumentBuilderFactory, which is also abstract, but it has a static fac-tory method, newInstance(), that we can use to create a DocumentBuilder. From there we can use one of
the parse() methods
to give us a Document object. Now we are totally in the DOM world. We can also obtain a DOMImplementation to find out what features our
parser has. In this case, we are trying to find out whether extended interfaces
are supported.
Once we have a Document object, we can get the root element by calling the getDocumentElement() method. It turns out that the Document object itself is a node, but it’s not the root node. We must
call getDocumentElement() to get
the root.
The method printElement() in SimpleWalker does all the heavy lifting. It prints out the node name and then
iterates through the child nodes recursively. Indenting is added for clarity. A
sample XML file, library.xml, is used for testing and is shown in Listing 7.3.
LISTING 7.3 library.xml—Sample
XML File
<?xml version=”1.0” encoding=”UTF-8”?>
<library>
<fiction>
<book>Moby Dick</book>
<book>The Last Trail</book>
</fiction>
<biography>
<book>The Last Lion,
Winston Spencer Churchill</book>
</biography>
</library>
The example can be executed using the following command:
java SimpleWalker library.xml
The output is shown in Listing 7.4.
LISTING 7.4 Output from SimpleWalker
Parser supports extended interfaces Root element is library
<library>
<#text>
</#text>
<fiction>
<#text>
</#text>
<book>
<#text>
</#text>
</book>
<#text>
</#text>
<book>
<#text>
</#text>
</book>
<#text>
</#text>
</fiction>
<#text>
</#text>
<biography>
<#text>
</#text>
<book>
<#text>
</#text>
</book>
<#text>
</#text>
</biography>
<#text>
</#text>
</library>
The output is mostly what we expect—all the element names are indented
nicely to show contained elements. However, what are all those <#text> elements? As mentioned earlier,
any text in an XML document becomes a child node in DOM. If we call getNodeName() on a text node, we get #text, not the text itself. If we want
to get the text, we
must determine whether we have a text node and then call getNodeValue().
We need only make a minor modification to the printElement() method, as shown in Listing 7.5.
LISTING 7.5 Modified printElement() Method
public void printElement(String
indent, Node aNode) { if (aNode.getNodeType() == Node.TEXT_NODE) {
System.out.println(indent + aNode.getNodeValue());
} else {
System.out.println(indent + “<” +
aNode.getNodeName() + “>”);
Node child = aNode.getFirstChild();
while (child != null) {
printElement(indent + “\t”, child);
child = child.getNextSibling();
}
System.out.println(indent +
“</” + aNode.getNodeName() +
“>”);
}
}
As you can see, the modified method checks the node type and formats the
output as needed. The output after the modification is shown in Listing 7.6.
LISTING 7.6 Output After printElement() Modification
Parser supports extended interfaces Root element is library
<library>
<fiction>
<book>
Moby Dick
</book>
<book>
The
Last Trail
</book>
</fiction>
<biography>
<book>
The
Last Lion, Winston
Spencer Churchill
</book>
</biography>
</library>
Notice the extra blank lines before and after each element. That’s
because the DOM parser treats any whitespace between elements as text.
Depending on the type of node, we might need to use getNodeName(), getNodeValue(), or maybe getAttributes(). Table 7.3 summarizes what each of the methods gives you, depending on
the interface type.
TABLE 7.3 Node Method Result Summary
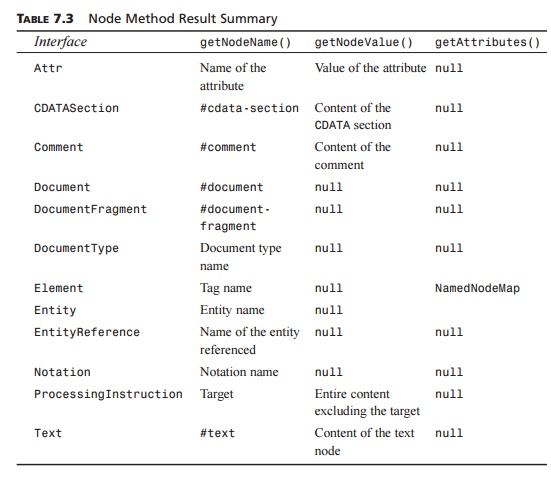
It’s important to note that attributes are not child nodes of elements.
You must explicitly call getAttributes() to obtain a NamedNodeMap containing the attributes. NamedNodeMap is convenient for attributes because you can easily get a specific
attribute by name or by index (starting from 0).
Something else to keep in mind is that many of the methods can throw a DOMException or some other exception. DOMException is a checked exception, meaning
it must be caught or thrown. In our simple example, we just throw all
exceptions to the caller. If an exception gets to main, the Java Virtual
Machine (JVM) will catch the exception, print out a stack trace, and terminate
the program. That’s okay for this simple case, but in production you might want
to handle exceptions yourself.
Creating an XML Document
In this example, we will create an XML document in memory, from scratch,
and then write it out to disk. You might do something like this if you have
data from a non-XML source, such as a database, and you want to create an XML
document based on the data. You could do this by just printing out raw tags and
avoid DOM altogether. This will work fine in many cases, but there are
potential maintenance problems. First, you might not generate well-formed XML
due to coding errors. Second, it’s a lot more work!
For the data source, we will use the directory of the local disk. The
XML document produced will be a directory listing in XML. The source code for DocBuilder.java is shown in Listing 7.7.
LISTING 7.7 DocBuilder.java
package com.madhu.xml;
import java.io.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class DocBuilder
{
protected DocumentBuilder docBuilder;
protected Element root;
protected Document doc;
protected PrintWriter writer;
public
DocBuilder() throws Exception
{
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
docBuilder = dbf.newDocumentBuilder();
}
public void buildDOM(String
startDir) throws Exception {
doc = docBuilder.newDocument();
root = doc.createElement(“directory-listing”);
appendFile(root, new File(startDir));
doc.appendChild(root);
}
public void appendFile(Node
parent, File aFile) throws Exception { if (aFile.isDirectory()) {
Element dirElement =
doc.createElement(“directory”);
dirElement.setAttribute(“name”, aFile.getName());
File[] files = aFile.listFiles();
int n =
files.length;
for (int i=0;
i<n; i+=1) {
appendFile(dirElement,
files[i]);
}
parent.appendChild(dirElement); }
else {
Element fileElement = doc.createElement(“file”);
Text fileName =
doc.createTextNode(aFile.getName());
fileElement.appendChild(fileName);
parent.appendChild(fileElement);
}
}
public void writeDOM(PrintWriter
bw) throws Exception {
writer = bw;
writer.println(“<?xml version=\”1.0\”
encoding=\”UTF-8\”?>”);
writeNode(“”, root);
}
public void writeNode(String
indent, Node aNode) {
switch (aNode.getNodeType()) {
case
Node.TEXT_NODE:
writer.println(indent + aNode.getNodeValue());
break;
case
Node.ELEMENT_NODE:
writer.print(indent + “<” +
aNode.getNodeName());
NamedNodeMap attrs = aNode.getAttributes();
int n = attrs.getLength(); for (int i=0; i<n;
i+=1) {
Node
attr = attrs.item(i);
writer.print(“ “ + attr.getNodeName() + “=\””);
writer.print(attr.getNodeValue() + “\””);
}
writer.println(“>”);
Node child = aNode.getFirstChild();
while (child != null) {
writeNode(indent + “\t”, child);
child = child.getNextSibling();
}
writer.println(indent + “</” +
aNode.getNodeName() + “>”);
break;
}
}
public static void main(String
args[]) throws Exception { DocBuilder db = new DocBuilder();
db.buildDOM(args[0]);
PrintWriter bw = new PrintWriter(
new FileWriter(args[1]));
db.writeDOM(bw);
bw.close();
}
}
To create an XML document, we use the DocumentBuilderFactory and the DocumentBuilder interfaces as before. However, instead of calling parse() in
DocumentBuilder to create a Document object, we will call the newDocument() method. This creates an empty Document object. Then we create elements
and attributes as needed and attach them appropriately.
The bulk of the work can be found in the methods buildDOM() and appendFile(). Directories and files are
treated as elements. The name of a directory becomes an attribute for a
directory element, whereas the name of a file is added as a text child node for
a file element. A portion of the output from the program is shown in Listing
7.8.
LISTING 7.8 Partial Output from
DocBuilder
<?xml version=”1.0” encoding=”UTF-8”?> <directory-listing>
<directory name=”..”>
<directory name=”com”>
<directory name=”madhu”>
<directory name=”xml”>
<file>
DocBuilder.class
</file>
<file>
SimpleWalker.class
</file>
</directory>
</directory>
</directory>
<directory name=”test”> <file>
Makefile
LISTING 7.8 continued
</file>
<file> personal-schema.xml
</file>
<file>
personal.dtd
</file>
<file>
personal.xml
</file>
...
The Document interface contains the methods needed for creating any type of node.
Element nodes contain a method called setAttribute() that conveniently creates and adds an attribute in one step. If an
attribute with the same name already exists, its value is replaced.
You’ll also notice that the code in the writeNode() method is improved over similar code in SimpleWalker. It handles elements, text nodes, and attributes as well.
Related Topics