Chapter: Software Testing : Testing Basics
Origin of Defects
Origin of Defects
The term defect and its relationship to the terms
error and failure in the context of the software development domain. Defects have detrimental affects on software users, and
software engineers work very hard to produce high-quality software with a low
number of defects. But even under the best of development circumstances errors
are made, resulting in defects being injected in the software during the phases
of the software life cycle. Defects as shown in figure stem from the following
sources
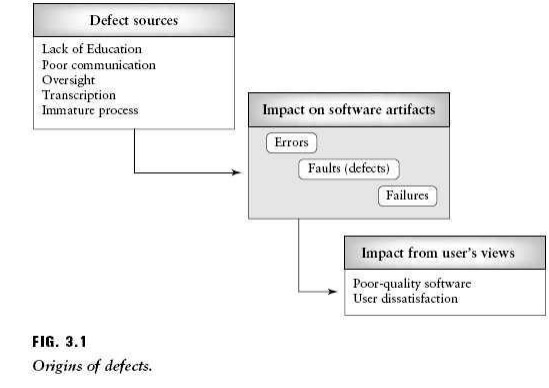
Education: The
software engineer did not have the proper educational background to prepare the software artifact. She did not
understand how to do something. For example, a software engineer who did not
understand the precedence order of operators in a particular programming
language could inject a defect in an equation that uses the operators for a
calculation.
Communication: The
software engineer was not informed about something by a colleague. For example, if engineer 1 and engineer
2 are working on interfacing modules, and engineer 1 does not inform engineer 2
that a no error checking code will appear in the interfacing module he is
developing, engineer 2 might make an incorrect assumption relating to the
presence/absence of an error check, and a defect will result.
Oversight: The
software engineer omitted to do something. For example, a software engineer might omit an initialization statement.
Transcription: The
software engineer knows what to do, but makes a mistake in doing it. A simple example is a variable name being
misspelled when entering the code.
Process: The
process used by the software engineer misdirected her actions. For example, a development process that did not allow
sufficient time for a detailed specification to be developed and reviewed could
lead to specification defects.
When defects
are present due to one or more of these circumstances, the software may fail,
and the impact on the user ranges from a minor inconvenience to rendering the
software unfit for use. Our goal as testers is to discover these defects
preferably before the software is in operation.One of the ways we do this is by
designing test cases that have a high probability of revealing defects. How do
we develop these test cases? One approach is to think of software testing as an
experimental activity. The results of the test experiment are analyzed to
determine whether the software has
behaved correctly. In this experimental scenario a tester develops hypotheses
about possible defects (see Principles 2 and 9). Test cases are then designed
based on the hypotheses. The tests are run and results analyzed to prove, or
disprove, the hypotheses.
Myers has
a similar approach to testing. He describes the successful test as one that
reveals the presence of a (hypothesized) defect. He compares the role of a
tester to that of a doctor who is in the process of constructing a diagnosis
for an ill patient. The doctor develops hypotheses about possible illnesses
using her knowledge of possible diseases, and the patientsŌĆś symptoms. Tests are
made in order to make the correct diagnosis. A successful test will reveal the
problem and the doctor can begin treatment. Completing the analogy of doctor
and ill patient, one could view defective software as the ill patient. Testers
as doctors need to have knowledge about possible defects (illnesses) in order
to develop defect hypotheses. They use the hypotheses to:
ŌĆó design
test cases;
ŌĆó design
test procedures;
ŌĆó assemble
test sets;
ŌĆó select
the testing levels (unit, integration, etc.)appropriate for the tests;
ŌĆó evaluate
the results of the tests.
7A
successful testing experiment will prove the hypothesis is trueŌĆöthat is, the
hypothesized defect was present. Then the software can be repaired (treated).A
very useful concept related to this discussion of defects, testing, and
diagnosis is that of a fault model.
A fault (defect) model can be described as a link
between the error made (e.g., a missing requirement, a misunderstood design
element, a typographical error), and the fault/defect in the software.
Digital
system engineers describe similar models that link physical defects in digital
components to electrical (logic) effects in the resulting digital system [4,5].
Physical defects in the digital world may be due to manufacturing errors,
component wear-out, and/or environmental effects.
The fault
models are often used to generate a fault list or dictionary. From that
dictionary faults can be selected, and test inputs developed for digital
components. The effectiveness of a test can be evaluated in the context of the
fault model, and is related to the number of faults as expressed in the model,
and those actually revealed by the test. This view of test effectiveness
(success) is similar to the view expressed by Myers stated above.
Although
software engineers are not concerned with physical defects, and the
relationships between software failures, software defects, and their origins
are not easily mapped, we often use the fault model concept and fault lists
accumulated in memory from years of experience to design tests and for
diagnosis tasks during fault localization (debugging) activities. A simple
example of a fault model a software engineer might have in memory is ŌĆĢan
incorrect value for a variable was observed because the precedence order for
the arithmetic operators used to calculate its value was incorrect.ŌĆ¢ This could be called ŌĆĢan
incorrect operator precedence orderŌĆ¢ fault.
An error was made on the part of the programmer who did not understand the
order in which the arithmetic operators would execute their operations. Some
incorrect assumptions about the order were made.
The
defect (fault) surfaced in the incorrect value of the variable. The probable
cause is a lack of education on the part of the programmer. Repairs include
changing the order of the operators or proper use of parentheses. The tester
with access to this fault model and the frequency of occurrence of this type of
fault could use this information as the basis for generating fault hypotheses
and test cases. This would ensure that adequate tests were performed to uncover
such faults.
In the
past, fault models and fault lists have often been used by developers/ testers
in an informal manner, since many organizations did not save or catalog
defect-related information in an easily accessible form. To increase the
effectiveness of their testing and debugging processes, software organizations
need to initiate the creation of a defect database, or defect repository. The
defect repository concept supports storage and retrieval of defect data from
all projects in a centrally accessible location. A defect classification scheme
is a necessary first step for developing the repository. The defect repository
can be organized by projects and for all projects defects of each class are
logged, along their frequency of occurrence, impact on operation, and any other
useful comments. Defects found both during reviews and execution-based testing
should be cataloged.
Related Topics