Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Hand-Coded Synchronization and Sharing
Operating System–Provided Atomics
Operating
System–Provided Atomics
Using the information in this chapter, it should be possible for you to
write some fundamental atomic operations such as an atomic add. However, these
operations may already be provided by the operating system. The key advantage
of using the operating system–provided code is that it should be correct, although
the cost is typically a slight increase in call overhead. Hence, it is
recommended that this code be taken advantage of whenever possible.
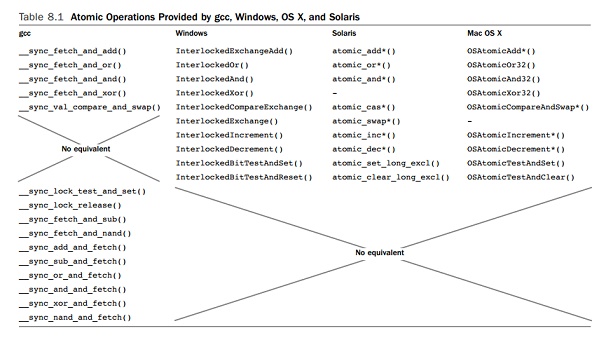
gcc provides the operations such as __sync_fetch_and_add(), which fetches a value from memory and adds an increment to it. The
return value is the value of the variable before the increment. Windows defines
InterlockedExchangeAdd(), which provides the same operation, and Solaris has a number of atomic_add() functions to handle different variable types. Table 8.1 on page 311
provides a mapping between the atomic operations provided by gcc, Windows, OS
X, and Solaris. An asterisk in the func-tion name indicates that it is
available for multiple different types.
The code in Listing 8.15 uses the gcc atomic
operations to enable multiple threads to increment a counter. The program
creates ten threads, each of which completes the function work(). The original program thread also executes the same code. Each thread
increments the variable counter 10
million times so that at the end of the program, the variable holds the value
110 million. If the atomic add operation is replaced with a nor-mal unprotected
increment operation, the output of the program is unpredictable because of the
data race that this introduces.
Listing 8.15 Using
Atomic Operations to Increment a Counter
#include <stdio.h> #include <pthread.h>
volatile
int counter=0;
void
*work( void* param )
{
int i;
for( i=0; i<1000000; i++ )
{
__sync_fetch_and_add(
&counter, 1 );
}
}
int
main()
{
int i;
pthread_t threads[10]; for( i=0; i<10; i++ )
{
pthread_create( &threads[i], 0, work, 0 );
}
work( 0 );
for( i=0; i<10; i++ )
{
pthread_join( threads[i], 0 );
}
printf( "Counter=%i\n", counter );
}
The main advantage of using these atomic operations
is that they avoid the overhead of using a mutex lock to protect the variable.
Although the mutex locks usually also have a compare and swap operation
included in their implementation, they also have overhead around that core
operation. The other difference is that the mutex lock operates at a dif-ferent
location in memory from the variable that needs to be updated. If both the lock
and variable are shared between threads, there would typically be cache misses
incurred for obtaining the lock and performing an operation on the variable.
These two factors combine to make the atomic operation more efficient.
Atomic operations are very
effective for situations where a single variable needs to be updated. They will
not work in situations where a coordinated update of variables is required.
Suppose an application needs to transfer money from one bank account to
another. Each account could be modified using an atomic operation, but there
would be a point during the entire transaction where the money had been removed
from one account and had not yet been added to the other. At this point, the
total value of all accounts would be reduced by the amount of money in
transition. Depending on the rules, this might be acceptable, but it would
result in the total amount of money held in the bank being impossible to know
exactly while transactions were occurring.
The alternative approach would be to lock both
accounts using mutex locks and then perform the transaction. The act of locking
the accounts would stop anyone else from reading the value of the money in
those accounts until the transaction had resolved.
Notice that there is the potential for a deadlock situation when
multiple transactions of this kind exist. Suppose an application needs to move
x pounds from account A to account B and at the same time another thread in the
application needs to move y pounds from account B to account A. If the first
thread acquires the lock account A and the second thread acquires the lock on
account B, then neither thread will be able to make progress. The simplest way
around this is to enforce an ordering (perhaps order of memory addresses, low
to high) on the acquisition of locks. In this instance, if all threads had to
acquire lock A before they would attempt to get the lock on B, only one of the
two threads would have succeeded in getting the lock on A, and consequently the
dead-lock would be avoided.
Related Topics