Chapter: Computer Networks : Data Communication
Network Layer
NETWORK LAYER
1. TRANSPORT LAYER
·
provide logical communication between app processes
running on different hosts
·
transport protocols run in end systems
o send
side: breaks app messages into segments, passes to network layer
o rcv side:
reassembles segments into messages, passes to app layer
·
more than one transport protocol available to apps
o Internet: TCP and UDP
·
network layer: logical communication between hosts
·
transport layer: logical communication between
processes
o relies on, enhances, network
layer services
·
reliable, in-order delivery (TCP)
o congestion
control (distributed control)
o flow
control
o connection setup
·
unreliable, unordered delivery: UDP
o no-frills extension of
“best-effort” IP
·
services not available:
o delay guarantees
o bandwidth guarantees
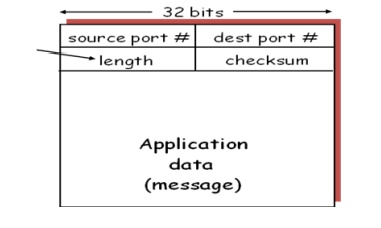
2. USER DATAGRAM PROTOCOL (UDP)
“no
frills,” “bare bones” Internet transport protocol
best effort” service, UDP segments may be:
o lost
o delivered out of order to app
connectionless:
o no handshaking between UDP
sender, receiver
o each UDP
segment handled independently of others
o no
connection establishment (which can add delay)
o simple:
no connection state at sender, receiver
o small segment header
o no congestion control: UDP can blast away as fast as desired
often
used for streaming multimedia apps
o loss
tolerant
o rate
sensitive
other UDP uses
o DNS
·
SNMP
reliable
transfer over UDP: add reliability at application layer
o application-specific error recovery!
3. TRANSMISSION CONTROL PROTOCOL
point-to-point:
o one sender, one receiver reliable,
in-order byte steam:
o no “message boundaries”
pipelined:
o TCP congestion and flow control set window size
send
& receive buffers
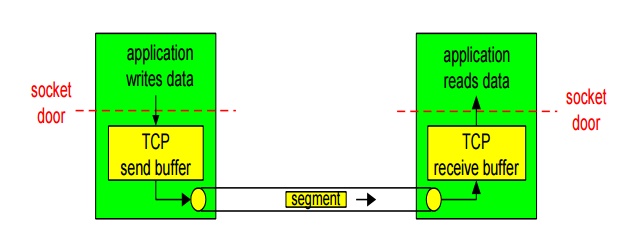
full
duplex data:
bi-directional
data flow in same connection
MSS:
maximum segment size
connection-oriented:
handshaking
(exchange of control msgs) init’s sender, receiver state before data exchange
flow
controlled:
sender will not overwhelm receiver
3.1.TCP segment structure
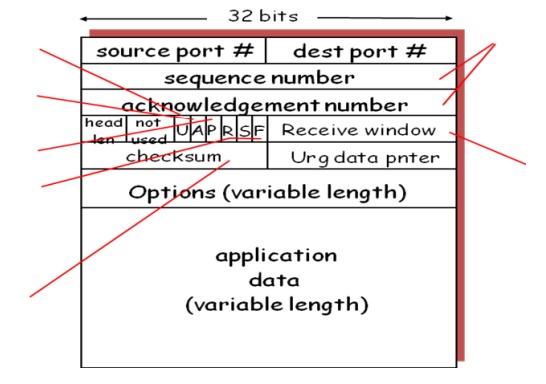
3.2. TCP seq. #’s and ACKs
Seq. #’s:
byte
stream “number” of first byte in segment’s data
ACKs:
seq # of
next byte expected from other side cumulative ACK
how receiver handles out-of-order segments
· TCP spec
doesn’t say, - up to implementor longer than RTT
but RTT
varies
too short: premature timeout unnecessary
retransmissions
too long:
slow reaction to segment loss
SampleRTT: measured time from segment transmission
until ACK receipt ignore retransmissions
SampleRTT
will vary, want estimated RTT “smoother”
average
several recent measurements, not just current SampleRTT TCP Round Trip Time and
Timeout
EstimatedRTT
= (1-a )*EstimatedRTT +a *SampleRTT Exponential weighted moving average
influence
of past sample decreases exponentially fast
typical
value: a =0.125
4. CONGESTION CONTROL
Congestion:
·
informally: “too many sources sending too much data
too fast for network to handle” different from flow control!
·
manifestations:
o
lost packets (buffer overflow at routers)
o
long delays (queueing in router buffers)
·
a top-10 problem!
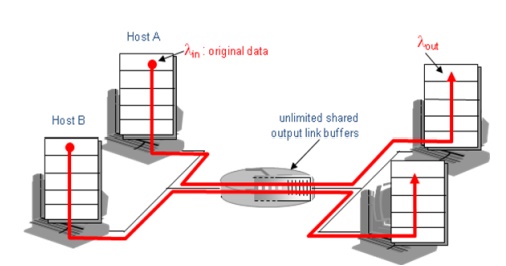
Causes/costs of congestion: scenario 1
·
two senders, two receivers
·
one router, infinite buffers
·
no retransmission
Causes/costs of congestion: scenario 2
·
one router, finite buffers
·
sender retransmission of lost packet
·
always: (goodput)
·
“perfect” retransmission only when loss:
·
retransmission of delayed (not lost) packet makes larger (than perfect case) for same
·
“costs” of congestion:
·
more work (retrans) for given “goodput”
·
unneeded retransmissions: link carries multiple
copies of pkt Causes/costs of congestion: scenario 3
·
four senders multihop paths timeout/retransmit
·
Another “cost” of congestion:
·
when packet dropped, any “upstream transmission
capacity used for that packet was wasted!
·
Approaches towards congestion control End-end
congestion control:
·
no explicit feedback from network
·
congestion inferred from end-system observed loss,
delay
·
approach taken by TCP
·
Network-assisted congestion control:
·
routers provide feedback to end systems
o
single bit indicating congestion (SNA, DECbit,
TCP/IP ECN, ATM)
o
explicit rate sender
5. FLOW CONTROL
receive
side of TCP connection has a receive buffer:
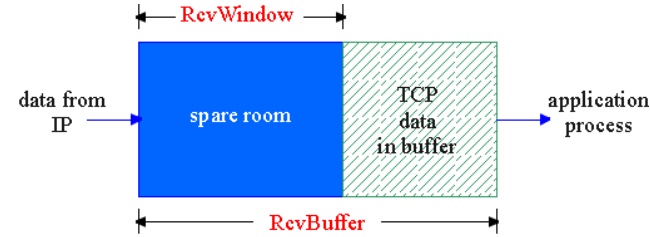
app
process may be slow at reading from buffer
speed-matching
service: matching the send rate to the receiving app’s drain rate
(Suppose
TCP receiver discards out-of-order segments) spare room in buffer
RcvWindow
RcvBuffer-[LastByteRcvd -
LastByteRead]
Rcvr
advertises spare room by including value of RcvWindow in segments Sender limits
unACKed data to RcvWindow
guarantees receive buffer doesn’t
overflow
6. QUEUING DISCIPLINES
·
Each router must implement some queuing discipline
– Scheduling discipline
– Drop policy
·
Queuing allocates both bandwidth and buffer space:
– Bandwidth: which packet to serve (transmit)
next
– Buffer space: which packet to drop next
(when required)
·
Queuing also affects latency
·
FIFO + drop-tail
– Simplest choice
– Used widely in the Internet
– FIFO: scheduling discipline
– Drop-tail: drop policy
·
FIFO (first-in-first-out)
–
Implies single class of traffic, no priority
Drop-tail
– Arriving packets get dropped when queue is
full regardless of flow or importance
Lock-out problem
– Allows a few flows to monopolize the queue
space
– Send more, get more -
> No implicit policing
Full queues
– TCP detects congestion from loss
– Forces network to have long standing queues
in steady-state
– Queueing delays – bad for time sensitive
traffic
– Synchronization: end hosts react to same
events
Full queue - >
empty - >
Full - >
empty…
·
Poor support for bursty traffic
·
Maintain running average of queue length
If avg < minth do nothing
– Low queuing, send packets through
If avg > maxth, drop packet
– Protection from misbehaving sources
Else mark packet in a manner
proportional to queue length
– Notify sources of incipient congestion
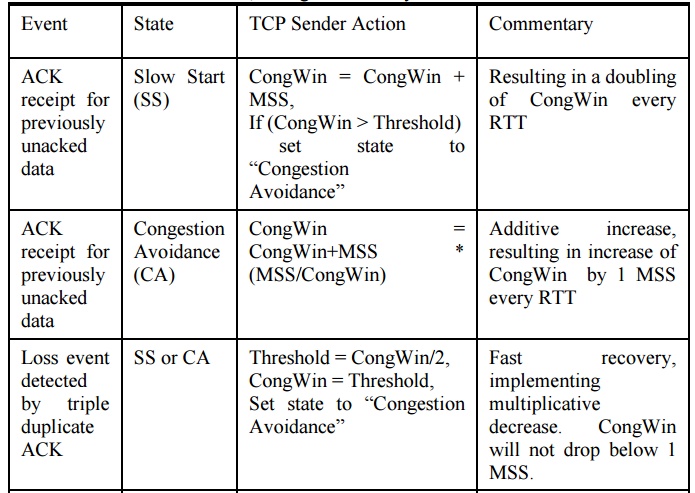
7. CONGESTION AVOIDANCE
MECHANISMS
·
end-end control (no network assistance)
·
sender limits transmission: LastByteSent-LastByteAcked
·
< = CongWin
·
Roughly,
·
CongWin is dynamic, function of perceived network
congestion loss event = timeout or 3 duplicate acks
·
TCP sender reduces rate (CongWin) after loss event
·
three mechanisms:
o
AIMD
o
slow start
o
conservative after timeout events
·
multiplicative decrease: cut CongWin in half after
loss event Priority queueing can solve some problems
·
Starvation
·
Determining priorities is hard
·
Simpler techniques: Random drop
·
Packet arriving when queue is full causes some
random packet to be dropped
·
Drop front
·
On full queue, drop packet at head of queue
·
Random drop and drop front solve the lock-out
problem but not the full-queues problem
·
Drop packets before queue becomes full (early drop)
Detect incipient congestion
o
Avoid window synchronization
o Randomly mark packets
o
Random drop helps avoid bias against bursty traffic
·
additive increase: increase CongWin by 1 MSS every
RTT in the absence of loss events: probing
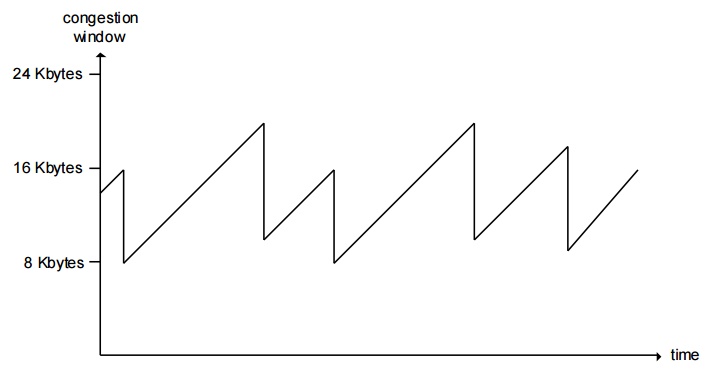
Tcp slow start
When connection begins, CongWin = 1 MSS Example:
MSS = 500 bytes & RTT = 200 msec initial rate = 20 kbps
available
bandwidth may be >> MSS/RTT
desirable
to quickly ramp up to respectable rate
When
connection begins, increase rate exponentially fast until first loss event When
connection begins, increase rate exponentially until first loss event:
double
CongWin every RTT
done by
incrementing CongWin for every ACK received
Refinement
After 3
dup ACKs:
CongWin
is cut in half window then grows linearly
But after
timeout event:
CongWin instead set
to 1 MSS;
window then grows
exponentially
to a threshold,
then grows linearly
After 3
dup ACKs:
CongWin is cut in
half
window then grows
linearly
But after
timeout event:
CongWin instead set
to 1 MSS;
window then grows
exponentially
to a threshold,
then grows linearly

Related Topics