Chapter: Security in Computing : Privacy in Computing
Data Mining
Data Mining
In Chapter 6 we described the process and some of the security
and privacy issues of data mining. Here we consider how to maintain privacy in
the context of data mining.
Private sector data mining is
a lucrative and rapidly growing industry. The more data collected, the more
opportunities for learning from various aggregations. Determining trends,
market preferences, and characteristics may be good because they lead to an
efficient and effective market. But people become sensitive if the private
information becomes known without permission.
Government Data Mining
Especially troubling to some
people is the prospect of government data mining. We believe we can stop
excesses and intrusive behavior of private companies by the courts, unwanted
publicity, or other forms of pressure. It is much more difficult to stop the
government. In many examples governments or rulers have taken retribution
against citizens deemed to be enemies, and some of those examples come from
presumably responsible democracies. Much government data collection and
analysis occurs without publicity; some programs are just not announced and
others are intentionally kept secret. Thus, citizens have a fear of what
unchecked government can do. Citizens' fears are increased because data mining
is not perfect or exact, and as many people know, correcting erroneous data
held by the government is next to impossible.
Privacy-Preserving Data Mining
Because data mining does
threaten privacy, researchers have looked into ways to protect privacy during
data mining operations. A naïve and ineffective approach is trying to remove
all identifying information from databases being mined. Sometimes, however, the
identifying information is precisely the goal of data mining. More importantly,
as the preceding example from Sweeney showed, identification may be possible
even when the overt identifying information is removed from a database.
Data mining has two
approachescorrelation and aggregation. We examine techniques to preserve
privacy with each of those approaches.
Privacy for Correlation
Correlation involves joining
databases on common fields. As in a previous example, the facts that someone is
named Erin and someone has diabetes have privacy significance only if the link
between Erin and diabetes exists. Privacy preservation for correlation attempts
to control that linkage.
Vaidya and Clifton [VAI04] discuss data perturbation as a way to
prevent privacy-endangering correlation. As a simplistic example, assume two
databases contain only three records, as shown in Table
10-1. The ID field linking these databases makes it easy to see that
Erin has diabetes.
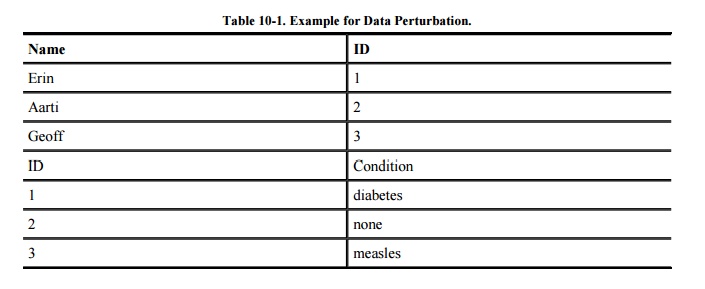
One form of data perturbation
involves swapping data fields to prevent linking of records. Swapping the
values Erin and Geoff (but not the ID values) breaks the linkage of Erin to
diabetes. Other properties of the databases are preserved: Three patients have
actual names and three conditions accurately describe the patients. Swapping
all data values can prevent useful analysis, but limited swapping balances
privacy and accuracy. With our example of swapping just Erin and Geoff, you
still know that one of the participants has diabetes, but you cannot know if
Geoff (who now has ID=1) has been swapped or not. Because you cannot know if a
value has been swapped, you cannot assume any such correlation you derive is
true.
Our example of three data points
is, of course, too small for a realistic data mining application, but we
constructed it just to show how value swapping would be done. Consider a more
realistic example on larger databases. Instead of names we might have
addresses, and the purpose of the data mining would be to determine if there is
a correlation between a neighborhood and an illness, such as measles. Swapping
all addresses would defeat the ability to draw any correct conclusions
regarding neighborhood. Swapping a small but significant number of addresses
would introduce uncertainty to preserve privacy. Some measles patients might be
swapped out of the high-incidence neighborhoods, but other measles patients
would also be swapped in. If the neighborhood has a higher incidence than the general
population, random swapping would cause more losses than gains, thereby
reducing the strength of the correlation. After value swapping an already weak
correlation might become so weak as to be statistically insignificant. But a
previously strong correlation would still be significant, just not as strong.
Thus value-swapping is a
technique that can help to achieve some degrees of privacy and accuracy under
data mining.
Privacy for Aggregation
Aggregation need not directly
threaten privacy. As demonstrated in Chapter 6,
an aggregate (such as sum, median, or count) often depends on so many data
items that the sensitivity of any single contributing item is hidden.
Government statistics show this well: Census data, labor statistics, and school
results show trends and patterns for groups (such as a neighborhood or school
district) but do not violate the privacy of any single person.
As we explained in Chapter 6, inference and aggregation attacks work
better nearer the ends of the distribution. If there are very few or very many
points in a database subset, a small number of equations may disclose private
data. The mean of one data value is that value exactly. With three data values,
the means of each pair yield three equations in three unknowns, which you know
can be solved easily with linear algebra. A similar approach works for very
large subsets, such as (n-3) values. Mid-sized subsets preserve privacy quite
well. So privacy is maintained with the rule of n items, over k percent, as
described in Chapter 6.
Data perturbation works for
aggregation, as well. With perturbation you add a small positive or negative
error term to each data value. Agrawal and Srikant [AGR00]
show that given the distribution of data after perturbation and given the
distribution of added errors, it is possible to determine the distribution (not
the values) of the underlying data. The underlying distribution is often what
researchers want. This result demonstrates that data perturbation can help
protect privacy without sacrificing the accuracy of results.
Vaidya and Clifton [VAI04) also describe a method by which databases
can be partitioned to preserve privacy. Our trivial example in Table 10-1 could be an example of a
database that was partitioned vertically to separate the sensitive association
of name and condition.
Summary of Data Mining and Privacy
As we have described in this
section, data mining and privacy are not mutually exclusive: We can derive
results from data mining without sacrificing privacy. True, some accuracy is
lost with perturbation. A counterargument is that the weakening of confidence
in conclusions most seriously affects weak results; strong conclusions become
only marginally less strong. Additional research will likely produce additional
techniques for preserving privacy during data mining operations.
We can derive results without
sacrificing privacy, but privacy will not exist automatically. The techniques
described here must be applied by people who understand and respect privacy
implications. Left unchecked, data mining has the potential to undermine
privacy. Security professionals need to continue to press for privacy in data
mining applications.
Related Topics