Chapter: Fundamentals of Database Systems : Advanced Database Models, Systems, and Applications : Data Mining Concepts
Commercial Data Mining Tools
Commercial Data Mining Tools
Currently, commercial data mining tools use several common techniques to
extract knowledge. These include association rules, clustering, neural
networks, sequencing, and statistical analysis. We discussed these earlier.
Also used are decision trees, which are a representation of the rules used in
classification or clustering, and statistical analyses, which may include
regression and many other techniques. Other commercial products use advanced
techniques such as genetic algorithms, case-based reasoning, Bayesian networks,
nonlinear regression, combinatorial optimization, pattern matching, and fuzzy
logic. In this chapter we have already discussed some of these.
Most data mining tools use the ODBC (Open Database Connectivity)
interface. ODBC is an industry standard that works with databases; it enables
access to data in most of the popular database programs such as Access, dBASE,
Informix, Oracle, and SQL Server. Some of these software packages provide
interfaces to specific data-base programs; the most common are Oracle, Access,
and SQL Server. Most of the tools work in the Microsoft Windows environment and
a few work in the UNIX operating system. The trend is for all products to
operate under the Microsoft Windows environment. One tool, Data Surveyor,
mentions ODMG compliance; see Chapter 11 where we discuss the ODMG
object-oriented standard.
In general, these programs perform sequential processing in a single
machine. Many of these products work in the client-server mode. Some products
incorporate parallel processing in parallel computer architectures and work as
a part of online analytical processing (OLAP) tools.
1. User Interface
Most of the tools run in a graphical user interface (GUI) environment.
Some products include sophisticated visualization techniques to view data and
rules (for example, SGI’s MineSet), and are even able to manipulate data this
way interactively. Text interfaces are rare and are more common in tools
available for UNIX, such as IBM’s Intelligent Miner.
2. Application
Programming Interface
Usually, the application programming interface (API) is an optional
tool. Most products do not permit using their internal functions. However, some
of them allow the application programmer to reuse their code. The most common
interfaces are C libraries and Dynamic Link Libraries (DLLs). Some tools
include proprietary data-base command languages.
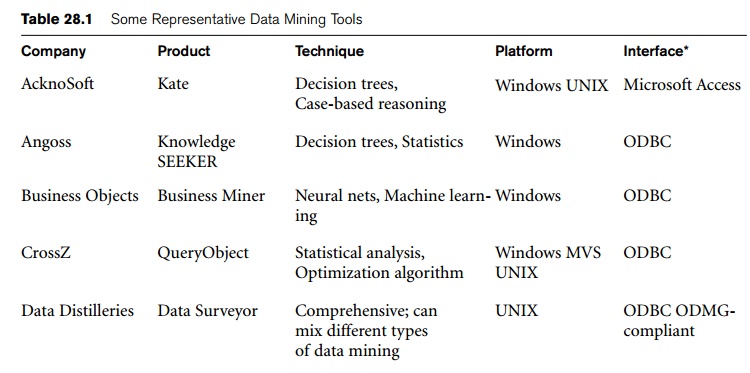
In Table 28.1 we list 11 representative data mining tools. To date,
there are almost one hundred commercial data mining products available
worldwide. Non-U.S. products include Data Surveyor from the Netherlands and
PolyAnalyst from Russia.
3. Future Directions
Data mining tools are continually evolving, building on ideas from the
latest scientific research. Many of these tools incorporate the latest
algorithms taken from artificial intelligence (AI), statistics, and
optimization.
Currently, fast processing is done using modern database techniques—such
as distributed processing—in client-server architectures, in parallel
databases, and in data warehousing. For the future, the trend is toward
developing Internet capabilities more fully. Additionally, hybrid approaches
will become commonplace, and processing will be done using all resources
available. Processing will take advantage of both parallel and distributed
computing environments. This shift is especially important because modern
databases contain very large amounts of information. Not only are multimedia
databases growing, but also image storage and retrieval are slow operations.
Also, the cost of secondary storage is decreasing, so massive information
storage will be feasible, even for small companies. Thus, data mining pro-grams
will have to deal with larger sets of data of more companies.
Most of data mining software will use the ODBC standard to extract data
from business databases; proprietary input formats can be expected to
disappear. There is a definite need to include nonstandard data, including
images and other multimedia data, as source data for data mining.

Related Topics