Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Scaling with Multicore Processors
Cache Conflict and Capacity
Cache
Conflict and Capacity
One of the notable features of multicore processors is that threads will
share a single cache at some level. There are two issues that can occur with
shared caches: capacity misses and conflict misses.
A conflict cache miss is where one thread has
caused data needed by another thread to be evicted from the cache. The worst
example of this is thrashing where multiple threads each require an item of
data and that item of data maps to the same cache line for all the threads.
Shared caches usually have sufficient associativity to avoid this being a
significant issue. However, there are certain attributes of computer systems
that tend to make this likely to occur.
Data structures such as stacks tend to be aligned
on cache line boundaries, which increases the likelihood that structures from
different processes will map onto the same address. Consider the code shown in
Listing 9.22. This code creates a number of threads. Each thread prints the
address of the first item on its stack and then waits at a barrier for all the
threads to complete before exiting.
Listing 9.22 Code
to Print the Stack Address for Different Threads
#include <pthread.h> #include <stdio.h>
#include <stdlib.h>
pthread_barrier_t
barrier;
void*
threadcode( void* param )
{
int stack;
printf("Stack
base address = %x for thread %i\n", &stack, (int)param);
pthread_barrier_wait( &barrier );
}
int
main( int argc, char*argv[] )
{
pthread_t threads[20]; int nthreads = 8;
if ( argc > 1 ) { nthreads = atoi( argv[1] ); }
pthread_barrier_init( &barrier, 0, nthreads ); for( int i=0; i<nthreads;
i++ )
{
pthread_create( &threads[i], 0, threadcode, (void*)i );
}
for( int i=0; i<nthreads; i++ )
{
pthread_join( threads[i], 0 );
}
pthread_barrier_destroy( &barrier ); return 0;
}
The expected output when this code is run on 32-bit
Solaris indicates that threads are created with a 1MB offset between the start
of each stack. For a processor with a cache size that is a power of two and
smaller than 1MB, a stride of 1MB would ensure the base of the stack for all
threads is in the same set of cache lines. The associativity of the cache will
reduce the chance that this would be a problem. A cache with an associa-tivity
greater than the number of threads sharing is less likely to have a problem
with conflict misses.
It is tempting to imagine that this is a
theoretical problem, rather than one that can actually be encountered. However,
suppose an application has multiple threads, and they all execute common code,
spending the majority of the time performing calculations in the same routine.
If that routine performs a lot of stack accesses, there is a good chance that
the threads will conflict, causing thrashing and poor application performance.
This is because all stacks start at some multiple of the stack size. The same
variable, under the same call stack, will appear at the same offset from the
base of the stack for all threads. It is quite possible that the cache line
will be mapped onto the same cache line set for all threads. If all threads
make heavy use of this stack location, it will cause thrashing within the set
of cache lines.
It is for this reason that processors usually
implement some kind of hashing in hard-ware, which will cause addresses with a
strided access pattern to map onto different sets of cache lines. If this is
done, the variables will map onto different cache lines, and the threads should
not cause thrashing in the cache. Even under this kind of hardware fea-ture, it
is still possible to cause thrashing, but it is much less likely to happen
because the obvious causes of thrashing have been eliminated.
The other issue with shared caches is capacity
misses. This is the situation where the data set that a single thread uses fits
into the cache, but adding a second thread causes the total data footprint to
exceed the capacity of the cache.
Consider the code shown in Listing 9.23. In this code, each thread
allocates an 8KB array of integers. When the code is run with a single thread
on a core with at least 8KB of cache, the data the thread uses becomes cache
resident, and the code runs quickly. If a second thread is started on the same
core, the two threads would require a total 16KB of cache for the data required
by both threads to remain resident in cache.
Listing 9.23 Code
Where Each Thread Uses an 8KB Chunk of Data
#include <pthread.h> #include <stdio.h>
#include <sys/time.h> #include <stdlib.h> #include
<sys/types.h> #include <sys/processor.h> #include
<sys/procset.h>
void
* threadcode( void*id )
{
int *stack = calloc( sizeof(int), 2048 ); processor_bind( P_LWPID,
P_MYID, ((int)id*4) & 63, 0 ); for( int i=0; i<1000; i++ )
{
hrtime_t start = gethrtime(); double total = 0.0;
for( int h=0;
h<100; h++ )
for( int k=0;
k<256*1024; k++ )
total += stack[ ( (h*k) ^ 20393 ) & 2047 ]
*stack[ ( (h*k) ^ 12834 ) & 2047 ];
hrtime_t end = gethrtime();
if ( total == 0 ){ printf( "" ); }
printf( "Time %f ns %i\n", (double)end – (double)start,
(int)id );
}
}
int
main( int argc, char*argv[] )
{
pthread_t threads[20]; int nthreads = 8;
if ( argc > 1 ) { nthreads = atoi( argv[1] ); }
for( int i=0; i<nthreads; i++ )
{
pthread_create( &threads[i], 0, threadcode, (void*)i );
}
for( int i=0; i<nthreads; i++) { pthread_join( threads[i], 0 ); }
return 0;
}
Running this code on an UltraSPARC T2 processor with one thread reports
a time of about 0.7 seconds per iteration of the outermost loop. The 8KB data
structure fits into the 8KB cache. When run with two threads, this time nearly
doubles to 1.2 seconds per iteration, as might be expected, because the
required data exceeds the size of the first-level cache and needs to be fetched
from the shared second-level cache.
Note that this code contains a call to the Solaris function processor_bind(), which binds a thread to a particular CPU. This is used in the code to
ensure that two threads are placed on the same core. Binding will be discussed
in the section “Using Processor Binding to Improve Memory Locality.”
Obviously, when multiple threads are bound to the same processor core,
there are other reasons why the performance might not scale. To prove that the
problem we are observing is a cache capacity issue, we need to eliminate the
other options.
In this particular instance, the only other applicable reason is that of
instruction issue capacity. This would be the situation where the processor was
unable to issue the instruc-tions from both streams as fast as it could issue
the instructions from a single stream.
There are two ways to determine whether this was the problem. The first
way is to perform the experiment where the size of the data used by each thread
is reduced so that the combined footprint is much less than the size of the
cache. If this is done and there is no impact performance from adding a second
thread, it indicates that the prob-lem is a cache capacity issue and not
because of the two threads sharing instruction issue width.
However, modifying the data structures of an application is practical
only on test codes. It is much harder to perform the same experiments on real
programs. An alterna-tive way to identify the same issue is to look at cache
miss rates using the hardware per-formance counters available on most
processors.
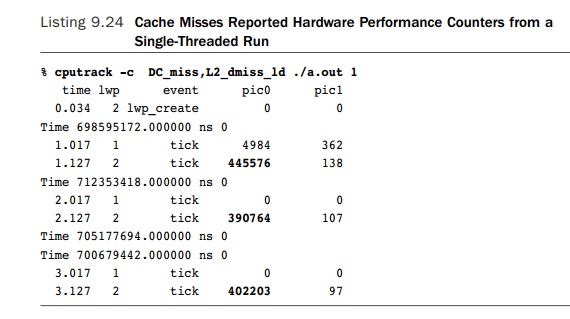
One tool to access the hardware performance counters on Solaris is cputrack. This tool reports the number of hardware performance counter events
triggered by a single process. Listing 9.24 shows the results of using cputrack to count the cache misses from a single-threaded version of the example
code. The tool reports that for the active thread there are about 450,000 L1
data cache misses per second and a few hundred L2 cache miss events per second.
This can be compared to the cache misses
encountered when two threads are run on the same core, as shown in Listing
9.25. In this instance, the L1 data cache miss rate increases to 26 million per
second for each of the two active threads. The L2 cache miss rate remains near
to zero.
Listing 9.25 Cache
Misses Reported When Two Threads Run on the Same Core

This indicates that when a single thread is running
on the core, it is cache resident and has few L1 cache misses. When a second
thread joins this one on the same core, the combined memory footprint of the
two threads exceeds the size of the L1 cache and causes both threads to have L1
cache misses. However, the combined memory footprint is still smaller than the
size of the L2 cache, so there is no increase in L2 cache misses.
Therefore, it is important to minimize the memory
footprint of the codes running on the system. Most memory footprint
optimizations will tend to appear to be common good programming practice and are
often automatically implemented by the compiler. For example, if there are
unused local variables within a function, then the compiler will not allocate
stack space to hold them.
Other issues might be less apparent. Consider an
application that manages its own memory. It would be better for this
application to return recently deallocated memory to the thread that
deallocated it rather than return memory that had not been used in a while. The
reason is that the recently deallocated memory might still be cache resident.
Reusing the same memory avoids the cache misses that would occur if the memory
manager returned an address that had not been recently used and the thread had
to fetch the cache line from memory.
Related Topics