Chapter: Pharmaceutical Biotechnology: Fundamentals and Applications : Genomics, Other “Omics” Technologies, Personalized Medicine, and Additional Biotechnology Related Techniques
An Introduction to “Omics” Technologies
AN INTRODUCTION TO “OMICS” TECHNOLOGIES
Since the discovery of DNA’s overall structure in 1953, the world’s
scientific community has continued to gain a better understanding of the
genetic information encoded by DNA and the genetic information carried by a
cell or organism. In the 1980s and 1990s,biotechnology techniques produced
novel therapeutics and a wealth of information about the mechanisms of various
diseases such as cancer. Yet the etiology of many other diseases, including
obesity and heart disease, remained unknown at the genetic and the molecular
level, presenting no obvious target to attack with a small molecule drug or
biotechnology-produced therapeutic agent. The answers were hidden in what was
unknown about the human genome. Despite the increasing knowledge of DNA
structure and function in the 1990s, the genome, the entire collection of genes
and all other functional and non-functional DNA sequences in the nucleus of an
organism, had yet to be sequenced. DNA may well be the largest, naturally
occurring molecule known. Successfully meeting the challenge of sequencing the
entire human genome is one of history’s great milestones and heralds enormous
potential (Venter et al., 2001; The Genome International Sequencing Consortium,
2001). While the genetic code for transcription and translation has been known
for years, sequencing the human genome provides a blueprint for all human
proteins and the sequences of all regulatory elements that govern the
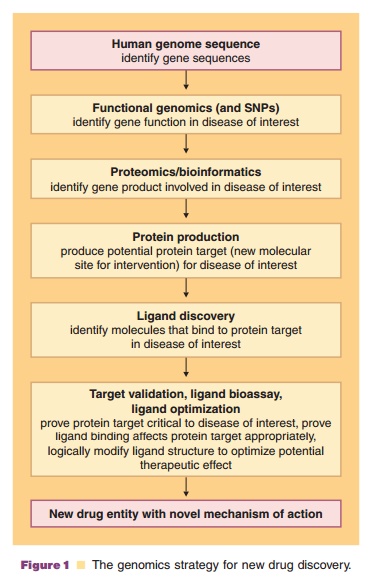
developmental interpretation of the genome. The potential significance includes
identifying genetic determinants of common and rare diseases, providing a
methodology for their diagnosis, suggesting interesting new molecular sites for
intervention (Fig. 1), and the development of new biotechnologies to bring
about their eradication. Unlocking the secrets of the human genome may lead to
a paradigm shift in clinical practice toward true targeted molecular medicine
and patient-specific therapy.
Related Topics