Chapter: Fundamentals of Database Systems : Introduction to Databases : Databases and Database Users
Advantages of Using the DBMS Approach
Advantages of Using the DBMS Approach
In this section we discuss some of the advantages of using a DBMS and
the capabilities that a good DBMS should possess. These capabilities are in
addition to the four main characteristics discussed in Section 1.3. The DBA
must utilize these capabilities to accomplish a variety of objectives related
to the design, administration, and use of a large multiuser database.
1. Controlling
Redundancy
In traditional software development utilizing file processing, every
user group maintains its own files for handling its dataprocessing
applications. For example, consider the UNIVERSITY database
example of Section 1.2; here, two groups of users might be the course
registration personnel and the accounting office. In the traditional approach,
each group independently keeps files on students. The accounting office keeps
data on registration and related billing information, whereas the registration
office keeps track of student courses and grades. Other groups may further
duplicate some or all of the same data in their own files.
This redundancy in storing
the same data multiple times leads to several problems. First, there is the
need to perform a single logical update—such as entering data on a new
student—multiple times: once for each file where student data is recorded. This
leads to duplication of effort.
Second, storage space is wasted when
the same data is stored repeatedly, and this problem may be serious for large
databases. Third, files that represent the same data may become inconsistent. This may happen because an
update is applied to some of the files but not to others. Even if an
update—such as adding a new student—is applied to all the appropriate files,
the data concerning the student may still be inconsistent because the updates are applied independently by each
user group. For example, one user group may enter a student’s birth date
erroneously as ‘JAN191988’, whereas the other user groups may enter the correct
value of ‘JAN-29-1988’.
In the database approach, the views of different user groups are
integrated during database design. Ideally, we should have a database design
that stores each logical data item—such as a student’s name or birth date—in only one place in the database. This is
known as data normalization, and it
ensures consistency and saves storage space (data normalization is described in
Part 6 of the book). However, in practice, it is sometimes necessary to use controlled redundancy to improve the
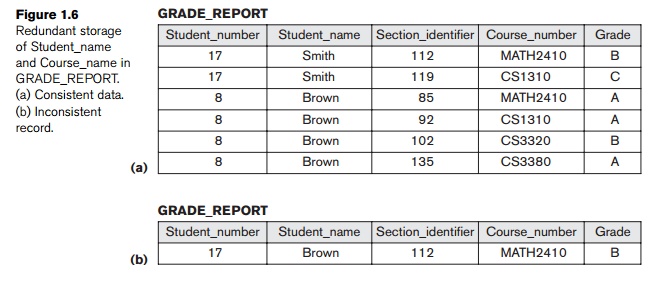
performance of queries. For example, we may store Student_name and Course_number redundantly in a GRADE_REPORT file (Figure 1.6(a)) because
whenever we retrieve a GRADE_REPORT record, we want to retrieve the
student name and course number along with the grade, student
number, and section identifier. By placing all the data together, we do not
have to search multiple files to collect this data. This is known as denormalization. In such cases, the
DBMS should have the capability to control this redundancy in
order to prohibit inconsistencies among the files. This may be done by
automatically checking that the Student_name–Student_number values in any GRADE_REPORT record in Figure 1.6(a) match one
of the
Name–Student_number val-ues of a STUDENT record (Figure 1.2). Similarly, the Section_identifier–Course_number values in GRADE_REPORT can be checked against SECTION records. Such checks can be
specified to the DBMS during database design and automatically enforced by the
DBMS whenever the GRADE_REPORT file is updated. Figure 1.6(b) shows a GRADE_REPORT record
that is inconsistent with the STUDENT file in Figure 1.2; this kind of error may be entered if the redundancy is not controlled. Can you tell which part is inconsistent?
2. Restricting
Unauthorized Access
When multiple users share a large database, it is likely that most users
will not be authorized to access all information in the database. For example,
financial data is often considered confidential, and only authorized persons
are allowed to access such data. In addition, some users may only be permitted
to retrieve data, whereas
others are allowed to retrieve and update. Hence, the type of access
operation— retrieval or update—must also be controlled. Typically, users or
user groups are given account numbers protected by passwords, which they can
use to gain access to the database. A DBMS should provide a security and authorization subsystem,
which the DBA uses to create accounts and to specify account restrictions.
Then, the DBMS should enforce these restrictions automatically. Notice that we
can apply similar controls to the DBMS software. For example, only the dba’s
staff may be allowed to use certain privileged
software, such as the software for creating new accounts. Similarly,
parametric users may be allowed to access the database only through the
predefined canned transactions developed for their use.
3. Providing Persistent
Storage for Program Objects
Databases can be used to provide persistent
storage for program objects and data structures. This is one of the main
reasons for object-oriented database
systems. Programming languages typically have complex data structures, such
as record types in Pascal or class definitions in C++ or Java. The values of program
variables or objects are discarded once a program terminates, unless the
programmer explic-itly stores them in permanent files, which often involves
converting these complex structures into a format suitable for file storage.
When the need arises to read this data once more, the programmer must convert
from the file format to the program variable or object structure.
Object-oriented database systems are compatible with programming languages such
as C++ and Java, and the DBMS software auto-matically performs any necessary
conversions. Hence, a complex object in C++ can be stored permanently in an
object-oriented DBMS. Such an object is said to be persistent, since it survives the termination of program execution
and can later be directly retrieved
by another C++ program.
The persistent storage of program objects and data structures is an
important func-tion of database systems. Traditional database systems often
suffered from the so-called impedance
mismatch problem, since the data structures provided by the DBMS were
incompatible with the programming language’s data structures. Object-oriented
database systems typically offer data structure compatibility with one or more object-oriented programming
languages.
4. Providing Storage
Structures and Search Techniques for Efficient Query Processing
Database systems must provide capabilities for efficiently executing queries and updates. Because the database is typically stored on disk, the DBMS
must provide specialized data
structures and search techniques to speed up disk search for the desired
records. Auxiliary files called indexes
are used for this purpose. Indexes are typically based on tree data structures
or hash data structures that are suitably modified for disk search. In order
to process the database records needed by a particular query, those records
must be copied from disk to main memory. Therefore, the DBMS often has a buffering or caching module that maintains parts of the data-base in main memory
buffers. In general, the operating system is responsible for disk-to-memory
buffering. However, because data buffering is crucial to the DBMS performance,
most DBMSs do their own data buffering.
The query processing and
optimization module of the DBMS is responsible for choosing an efficient
query execution plan for each query based on the existing storage structures.
The choice of which indexes to create and maintain is part of physical database design and tuning, which is one of the responsibilities of
the DBA staff. We discuss the query
processing, optimization, and tuning in Part 8 of the book.
5. Providing Backup and
Recovery
A DBMS must provide facilities for recovering from hardware or software
failures. The backup and recovery
subsystem of the DBMS is responsible for recovery. For example, if the
computer system fails in the middle of a complex update transaction, the
recovery subsystem is responsible for making sure that the database is restored
to the state it was in before the transaction started executing. Alternatively,
the recovery subsystem could ensure that the transaction is resumed from the
point at which it was interrupted so that its full effect is recorded in the
database. Disk backup is also necessary in case of a catastrophic disk failure.
We discuss recovery and backup in Chapter 23.
6. Providing Multiple
User Interfaces
Because many types of users with varying levels of technical knowledge
use a data-base, a DBMS should provide a variety of user interfaces. These
include query languages for casual users, programming language interfaces for
application programmers, forms and command codes for parametric users, and
menu-driven interfaces and natural language interfaces for standalone users.
Both forms-style interfaces and menu-driven interfaces are commonly known as graphical user interfaces (GUIs). Many specialized languages and environments
exist for specify-ing GUIs. Capabilities for providing Web GUI interfaces to a
database—or Web-enabling a database—are also quite common.
7. Representing Complex
Relationships among Data
A database may include numerous varieties of data that are interrelated
in many ways. Consider the example shown in Figure 1.2. The record for ‘Brown’
in the STUDENT
file is related to four records in the GRADE_REPORT file. Similarly, each section record is related to one
course record and to a number of GRADE_REPORT
records—one for each student who completed that section. A DBMS must have the
capability to represent a variety of complex relationships among the data, to
define new relationships as they arise, and to retrieve and update related data
easily and efficiently.
8. Enforcing Integrity
Constraints
Most database applications have certain integrity constraints that must hold for the data. A DBMS should
provide capabilities for defining and enforcing these constraints. The simplest
type of integrity constraint involves specifying a data type for each data
item. For example, in Figure 1.3, we specified that the value of the Class data item within each STUDENT record must be a one digit
integer and that the value of Name must be a string of no more than
30 alphabetic characters. To restrict the value of Class between 1 and 5 would be an additional constraint that is not shown in
the current catalog. A more complex type of constraint that frequently occurs
involves specifying that a record in one file must be related to records in
other files. For example, in Figure 1.2, we can specify that every section record must be related to a course record. This is
known as a referential integrity constraint. Another type of constraint specifies
uniqueness on data item values, such as every
course record must have a unique value
for Course_number. This is known as a key or uniqueness
constraint. These constraints are derived from the meaning or semantics of the data and of the
miniworld it represents. It is the responsibility of the database designers to identify integrity constraints during
database design. Some constraints can be specified to the DBMS and
automatically enforced. Other constraints may have to be checked by update
programs or at the time of data entry. For typical large applications, it is
customary to call such constraints business
rules.
A data item may be entered erroneously and still satisfy the specified
integrity con-straints. For example, if a student receives a grade of ‘A’ but a
grade of ‘C’ is entered in the database, the DBMS cannot discover this error automatically because ‘C’ is a valid
value for the Grade data type. Such data entry errors can only be discovered manually (when
the student receives the grade and complains) and corrected later by updating
the database. However, a grade of ‘Z’ would be rejected automatically by the
DBMS because ‘Z’ is not a valid value for the Grade data
type. When we dis-cuss each data model in subsequent chapters, we will
introduce rules that pertain to that model implicitly. For example, in the
Entity-Relationship model in Chapter 7, a relationship must involve at least
two entities. Such rules are inherent
rules of the data model and are automatically assumed to guarantee the
validity of the model.
9. Permitting
Inferencing and Actions Using Rules
Some database systems provide capabilities for defining deduction rules for inferencing new information from the stored database facts. Such systems
are called deductive database systems. For example, there may be complex rules
in the mini-world application for determining when a student is on probation.
These can be specified declaratively
as rules, which when compiled and
maintained by the DBMS can determine all students on probation. In a
traditional DBMS, an explicit procedural
program code would have to be written to support such applications. But if the miniworld rules change, it is
generally more convenient to change the declared deduction rules than to recode
procedural programs. In today’s relational database systems, it is possible to
associate triggers with tables. A
trigger is a form of a rule activated by updates to the table, which results in
performing some additional operations to some other tables, sending messages,
and so on. More involved procedures to enforce rules are popularly called stored procedures; they become a part
of the overall database definition and are invoked appropriately when certain
conditions are met. More powerful functionality is provided by active database systems, which provide
active rules that can automatically initiate actions when certain events and
conditions occur.
10. Additional Implications of Using the Database Approach
This section discusses some additional implications of using the
database approach that can benefit most organizations.
Potential for Enforcing
Standards. The database approach permits the
DBA to
define and enforce standards among database users
in a large organization. This facil-itates communication and cooperation among
various departments, projects, and users within the organization. Standards can
be defined for names and formats of data elements, display formats, report
structures, terminology, and so on. The DBA can enforce standards in a
centralized database environment more easily than in an environment where each
user group has control of its own data files and software.
Reduced Application
Development Time. A prime selling feature of the
data-base approach is that developing a new application—such as the retrieval
of certain data from the database for printing a new report—takes very little
time. Designing and implementing a large multiuser database from scratch may
take more time than writing a single specialized file application. However,
once a database is up and run-ning, substantially less time is generally
required to create new applications using DBMS facilities. Development time
using a DBMS is estimated to be one-sixth to one-fourth of that for a
traditional file system.
Flexibility. It may be necessary to change the structure of a database as
requirements change. For example, a new user group may emerge that needs
information not currently in the database. In response, it may be necessary to
add a file to the database or to extend the data elements in an existing file.
Modern DBMSs allow certain types of evolutionary changes to the structure of
the database without affecting the stored data and the existing application
programs.
Availability of Up-to-Date
Information. A DBMS makes the database
available
to all users. As soon as one user’s update is
applied to the database, all other users can immediately see this update. This
availability of up-to-date information is essential for many
transaction-processing applications, such as reservation systems or banking
databases, and it is made possible by the concurrency control and recov-ery
subsystems of a DBMS.
Economies of Scale. The DBMS approach permits consolidation of data and applications, thus reducing the amount of wasteful overlap between
activities of data-processing personnel in different projects or departments as
well as redundan-cies among applications. This enables the whole organization
to invest in more powerful processors, storage devices, or communication gear,
rather than having each department purchase its own (lower performance)
equipment. This reduces overall costs of operation and management.
Related Topics