Chapter: XML and Web Services : XML Technology Family
XML - Structuring with schemas
Structuring with schemas
A Simple XML Document:
We‘ll talk about a shirt. There‘s actually a lot we can talk about with regard to a shirt: size, color, fabric, price, brand, and condition, among other properties. The Following example shows one possi- ble XML rendition of a document describing a shirt. Of course, there are many other possible ways to describe a shirt, but this example provides a foundation for our further discussions.
<?xml version=‖1.0‖?>
<shirt>
<model>Zippy Tee</model>
<brand>Tommy Hilbunger</brand>
<price currency=‖USD‖>14.99</price>
<on_sale/>
<fabric content=‖60%‖>cotton</fabric> <fabric content=‖40%‖>polyester</fabric> <options>
<colorOptions>
<color>red</color>
<color>white</color>
</colorOptions>
<sizeOptions>
<size>Medium</size>
<size>Large</size>
</sizeOptions>
</options>
<description> This is a <b>funky</b> Tee shirt similar to the Floppy Tee shirt </description>
</shirt>
XML Declaration:
The XML declaration is a processing instruction of the form <?xml ...?>. Although it is not required, the presence of the declaration explicitly identifies the document as an XML document and indicates the version of XML to which it was authored. In addition, the XML declaration indicates the presence of external markup declarations and character encoding. Because a number of document formats use markup similar to XML, the declaration is useful in establishing the document as being compliant with a specific version of XML without any doubt or ambiguity. In general, every XML document should use an XML declaration. As documents increase in size and complexity, this importance likewise grows.
Components of the XML Declaration:

ValidXMLDeclarations
<?xmlversion=‖1.0‖standalone=‖yes‖?>
<?xmlversion=‖1.0‖standalone=‖no‖?>
<?xmlversion=‖1.0‖encoding=‖UTF-8‖standalone=‖no‖?>
Document Type Declaration
A Document Type Declaration names the document type and identifies the internal con- tent by specifying the root element, in essence the first XML tag that the XML-process- ing tools will encounter in the document. A DOCTYPE can identify the constraints on the validity of the document by making a reference to an external DTD subset and/or include the DTD internally within the document by means of an internal DTD subset.
General Forms of the Document Type Declarations:
<!DOCTYPENAMESYSTEM―file‖>
<!DOCTYPENAME[]> <!DOCTYPENAMESYSTEM―file‖[]>

Document Type declaration.

Markup and Content:
In general, six kinds of markup can occur in an XML document: elements, entity references, comments, processing instructions,marked sections, and Document Type Declarations.
XML BASED STANDARDS:
1) XPATH
XPath is a syntax for defining parts of an XML
document. XPath uses path expressions to navigate in XML documents. XPath
contains a library of standard functions. XPath is a major element in XSLT.
XPath is a W3C Standard
2) XSD
It defines elements that can appear in a
document. defines attributes that can appear in a document. It defines which
elements are child elements. defines the order of child elements. It defines
the number of child elements. It defines whether an element is empty or can
include text. It defines data types for elements and attributes. It defines
default and fixed values for elements and attributes
3) XSL
XSL describes how the XML document should be
displayed! XSL consists of three parts:XSLT - a language for transforming XML
documents, XPath - a language for navigating in XML documents, XSL-FO - a
language for formatting XML documents
4) XSLT
A common way to describe the transformation process
is to say that XSLT transforms an XML source-tree into an XML result-tree.XSLT
stands for XSL Transformations. XSLT is the most important part of XSL. XSLT
transforms an XML document into another XML document. XSLT uses XPath to
navigate in XML documents. XSLT is a W3C Recommendation.
XML
DOCUMENT STRUCTURE:
XML document includes the following
•
The xml
declaration
•
The
document type declaration
•
The
element data
•
The
attribute data
•
The
character data or XML content
STRUCTURING
WITH SCHEMAS:
– TWO
TYPES OF SCHEMAS : SIMPLE TYPE, COMPLEX TYPE
SIMPLE TYPE: A simple element is an XML element
that can contain only text. It cannot contain any other elements or attributes.
RULES
FOR XML STRUCTURE:
All XML elements must have a closing tag. XML
tags are case sensitive, All XML elements must have a proper nesting, All XML
Documents must contain a single root element, Attribute values must be quoted,
Attributes may only appear once in the same start tag, Attribute values cannot
contain references to external entities, All entities except amp,lt,gt,apos,and
quot must be declared before they are used.
SIMPLE
TYPE:
XML Schema has a lot of built-in data types.
The most common types are:
– xs:string
– xs:decimal
– xs:integer
– xs:boolean
– xs:date
– xs:time
Example:
Here are some XML elements:
<lastname>Refsnes</lastname>
<age>36</age>
<dateborn>1970-03-27</dateborn>
And here are the corresponding simple element
definitions:
<xs:element name="lastname"
type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
<xs:element name="dateborn"
type="xs:date"/>
COMPLEX
TYPE:
A complex element is an XML element that
contains other elements and/or attributes. Look at this simple XML document
called "note.xml":
<?xml version="1.0"?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget to submit the
assignment this monday!</body>
</note>
The following example is a DTD file called
"note.dtd" that defines the elements of the XML document above
("note.xml"):
<!ELEMENT note (to, from, heading,
body)><!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
The following example is an XML Schema file
called "note.xsd" that defines the elements of the XML document above
("note.xml"):
<?xml version="1.0"?>
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3schools.com"
xmlns="http://www.w3schools.com"
elementFormDefault="qualified">
<xs:element name="note">
<xs:complexType> <xs:sequence>
<xs:element name="to"
type="xs:string"/>
<xs:element name="from"
type="xs:string"/>
<xs:element name="heading"
type="xs:string"/>
<xs:element name="body"
type="xs:string"/> </xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
DTD:
A Document Type Definition (DTD) defines the
legal building blocks of an XML document. It defines the document structure
with a list of legal elements and attributes.
TWO TYPES OF DTD
–
INTERNAL DTD
–
EXTERNAL DTD
INTERNAL
DTD:
If the DTD is declared inside the XML file, it
should be wrapped in a DOCTYPE definition with the following syntax:
<!DOCTYPE root-element
[element-declarations]> Example XML document with an internal DTD: <?xml
version="1.0"?>
<!DOCTYPE note [ <!ELEMENT note
(to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)> ]>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget to prepare for the
UNIT TEST this weekend</body>
</note>
EXTERNAL
DTD:
If the DTD is declared in an external file, it
should be wrapped in a DOCTYPE definition with the following syntax:
<!DOCTYPE root-element SYSTEM
"filename">
This is the same XML document as above, but
with an external DTD <?xml version="1.0"?>
<!DOCTYPE note SYSTEM
"note.dtd">
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget to prepare for the
UNIT TEST this weekend!</body>
</note>
And this is the file "note.dtd" which
contains the DTD: <!ELEMENT note (to,from,heading,body)> <!ELEMENT to
(#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
XML
SCHEMAS:
XML Schema is an XML-based alternative to DTDs.
An XML Schema describes the structure of an XML document. The XML Schema
language is also referred to as XML Schema Definition (XSD).The purpose of an
XML Schema is to define the legal building blocks of an XML document, just like
a DTD.
An XML Schema defines elements that can appear
in a document, defines attributes that can appear in a document, defines which
elements are child elements , defines the order of child elements, defines the
number of child elements, defines whether an element is empty or can include
text, defines data types for elements and attributes, defines default and fixed
values for elements and attributes.
XML
PROCESSING:
The JavaTM API for XML Processing (JAXP)
includes the basic facilities for working with XML documents through the
following standardized set of Java Platform APIs. There are two types of XML
Parsers namely Document Object Model (DOM), Simple API For XML Parsing (SAX).
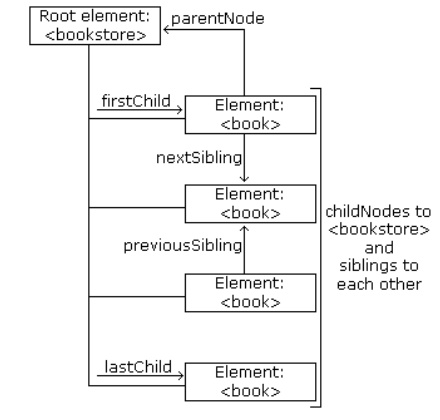
DOM:
The XML DOM views an XML document as a
tree-structure. The tree structure is called a node-tree. All nodes can be
accessed through the tree. Their contents can be modified or deleted, and new
elements can be created. The nodes in the node tree have a hierarchical
relationship to each other. The terms parent, child, and sibling are used to
describe the relationships. Parent nodes have children. Children on the same
level are called siblings (brothers or sisters). In a node tree, the top node
is called the root. Every node, except the root, has exactly one parent node. A
node can have any number of children. A leaf is a node with no children.
Siblings are nodes with the same parent.
SAX:
SAX (Simple API for XML) is an event-driven
model for processing XML. Most XML processing models (for example: DOM and
XPath) build an internal, tree-shaped representation of the XML document. The
developer then uses that model's API (getElementsByTagName in the case of the
DOM or findnodes using XPath, for example) to access the contents of the
document tree. The SAX model is quite different. Rather than building a
complete representation of the document, a SAX parser fires off a series of
events as it reads the document from beginning to end. Those events are passed
to event handlers, which provide access to the contents of the document.
Event
Handlers:
There are three classes of event handlers: DTDHandlers,
for accessing the contents of XML Document-Type Definitions; ErrorHandlers, for
low-level access to parsing errors; and, by far the most often used,
DocumentHandlers, for accessing the contents of the document. A SAX processor
will pass the following events to a DocumentHandler:
1)
The
start of the document.
2)
A
processing instruction element.
3)
A
comment element.
4)
The
beginning of an element, including that element's attributes.
5)
The text
contained within an element.
6)
The end
of an element.
7)
The end
of the document.
EXAMPLE
FOR SAX:
<html><body>
<script type="text/javascript">
try //Internet Explorer
{
xmlDoc=new
ActiveXObject("Microsoft.XMLDOM");
} catch(e) { try
//Firefox, Mozilla, Opera, etc.
{
xmlDoc=document.implementation.createDocument("","",null);
} catch(e)
{
alert(e.message)
}
} try
{ xmlDoc.async=false;
xmlDoc.load("books.xml"); document.write("xmlDoc is loaded,
ready for use"); } catch(e)
{alert(e.message)}
</script>
</body>
</html>

PRESENTATION
TECHNOLOGIES:
1)
XSL
2) XFORMS
3)
XHTML
XSL
& XSLT:
XSL stands for EXtensible Stylesheet Language.
What is XSLT?
XSLT stands for XSL Transformations. XSLT is
the most important part of XSL. XSLT transforms an XML document into another
XML document. XSLT uses XPath to navigate in XML documents. XSLT is a W3C
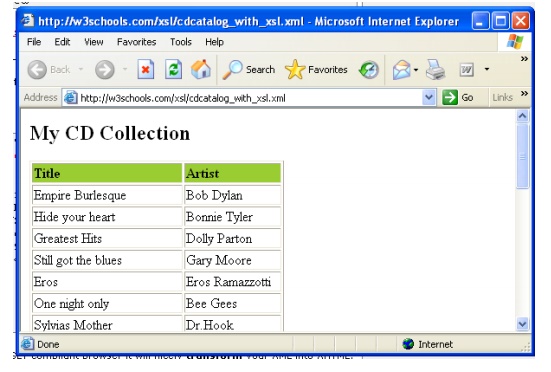
Recommendation. We want to transform
the following XML document ("cdcatalog.xml") into XHTML:
<?xml version="1.0"
encoding="ISO-8859-1"?> <catalog>
<cd>
<title>Empire Burlesque</title>
<artist>Bob
Dylan</artist><country>USA</country><company>Columbia</company><price>
10.90</price>
<year>1985</year> </cd> . . .
</catalog>
Then you create an XSL Style Sheet
("cdcatalog.xsl") with a transformation template: <?xml
version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>My CD Collection</h2> <table
border="1">
<tr bgcolor="#9acd32"> <th
align="left">Title</th> <th
align="left">Artist</th> </tr>
<xsl:for-each select="catalog/cd">
<tr>
<td><xsl:value-of
select="title"/></td> <td><xsl:value-of
select="artist"/></td>
</tr> </xsl:for-each>
</table> </body> </html> </xsl:template>
</xsl:stylesheet>
The result is:
XFORMS:
XForms is the next generation of HTML forms.
XForms is richer and more flexible than HTML forms. XForms will be the forms
standard in XHTML 2.0. XForms is platform and device independent. XForms
separates data and logic from presentation. XForms uses XML to define form
data. XForms stores and transports data in XML documents. XForms contains
features like calculations and validations of forms. XForms reduces or
eliminates the need for scripting. XForms is a W3C Recommendation. The XForms
Model. The XForms model is used to describe the data. The data model is an
instance (a template) of an XML document. The XForms model defines a data model
inside a <model> element:
<model>
<instance>
<person>
<fname/>
<lname/>
</person>
</instance>
<submission id="form1"
action="submit.asp" method="get"/> </model>
The
XForms Model
The XForms model
is used to describe the data. The
data model is an instance (a template) of an XML document. The XForms model
defines a data model inside a <model> element:
<model>
<instance>
<person>
<fname/>
<lname/>
</person>
</instance>
<submission id="form1"
action="submit.asp" method="get"/> </model>
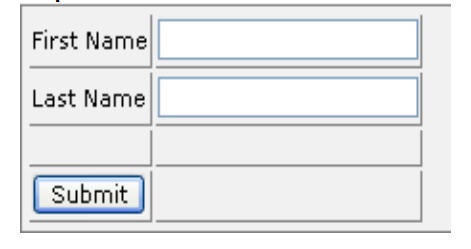
All together it looks as below <xforms>
<model>
<instance>
<person><fname/><lname/></person>
</instance> <submission
id="form1" action="submit.asp" method="get"/>
</model>
<input
ref="fname"><label>First
Name</label></input><input ref="lname">
<label>Last
Name</label></input>
<submit submission="form1">
<label>Submit</label>
</submit>
</xforms>
Output
seems like:
XHTML:
XHTML stands for EXtensible HyperText Markup
Language. XHTML is aimed to replace HTML. XHTML is almost identical to HTML
4.01. XHTML is a stricter and cleaner version of HTML. XHTML is HTML defined as
an XML application. XHTML is a W3C Recommendation. XHTML elements must be
properly nested. XHTML elements must always be closed. XHTML elements must be
in lowercase. XHTML documents must have one root element.
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>simple document</title>
</head>
<body><p>a simple
paragraph</p></body>
</html>
The 3 Document Type Definitions :
1)
DTD
specifies the syntax of a web page in SGML.
2)
DTD is
used by SGML applications, such as HTML, to specify rules that apply to the
markup of documents of a particular type, including a set of element and entity
declarations.
3)
XHTML is
specified in an SGML document type definition or 'DTD'.
An XHTML DTD describes in precise,
computer-readable language, the allowed syntax and grammar of XHTML markup.
There are currently 3 XHTML document types:
i.
STRICT
ii.
TRANSITIONAL
iii.
FRAMESET
XHTML 1.0 specifies three XML document types
that correspond to three DTDs:
i.
Strict
ii.
Transitional
iii.
Frameset
XHTML
1.0 Strict:
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
We can use this when you want really clean
markup, free of presentational clutter. We can use this together with Cascading
Style Sheets.
XHTML
1.0 Transitional:
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
We can use this when you need to take advantage
of HTML's presentational features and when you want to support browsers that
don't understand Cascading Style Sheets.
XHTML
1.0 Frameset:
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Frameset//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
We can use this when you want to use HTML
Frames to partition the browser window into two or more frames.
Why XHTML
Modularization?
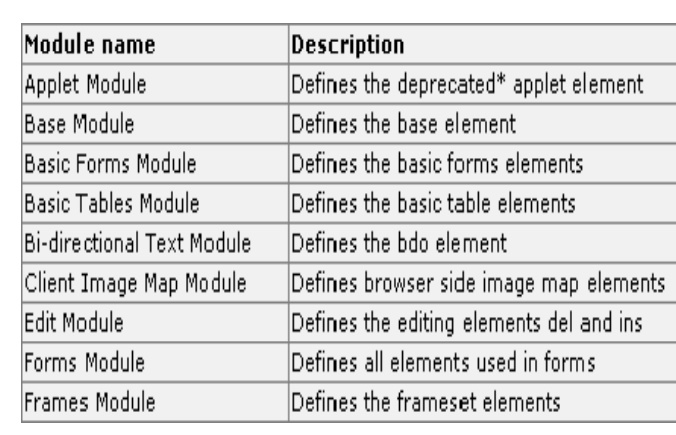
By splitting XHTML into modules, the W3C (World
Wide web Consortium) has created small and well-defined sets of XHTML elements
that can be used separately for small devices, or combined with other XML
standards into larger and more complex applications.
Some of
the modules are as below:
TRANSFORMATION:
•
XSLT
•
XLINK
•
XPATH
•
XQuery
XLINK:
XLink
Syntax:
In HTML, we know (and all the browsers know!)
that the <a> element defines a hyperlink. However, this is not how it
works with XML. In XML documents, you can use whatever element names you want -
therefore it is impossible for browsers to predict what hyperlink elements will
be called in XML documents.The solution for creating links in XML documents was
to put a marker on elements that should act as hyperlinks.
Example:
<?xml version="1.0"?>
<homepages
xmlns:xlink="http://www.w3.org/1999/xlink">
<homepage xlink:type="simple"
xlink:href="http://www.w3schools.com">Visit
W3Schools</homepage><homepage xlink:type="simple" xlink:href="http://www.w3.org">Visit
W3C</homepage>
</homepages>

XPATH:
XPath is a syntax for defining parts of an XML
document. XPath uses path expressions to navigate in XML documents. XPath
contains a library of standard functions
XPath is a major element in XSLT. XPath is a
W3C Standard.
XPath
Terminology
Nodes:
In XPath, there are seven kinds of nodes:
element, attribute, text, namespace, processing-instruction, comment, and
document (root) nodes. XML documents are treated as trees of nodes. The root of
the tree is called the document node (or root node).
Relationship
of Nodes
i.
Parent
ii.
Children
iii.
Siblings
iv.
Ancestors
v.
Descendants
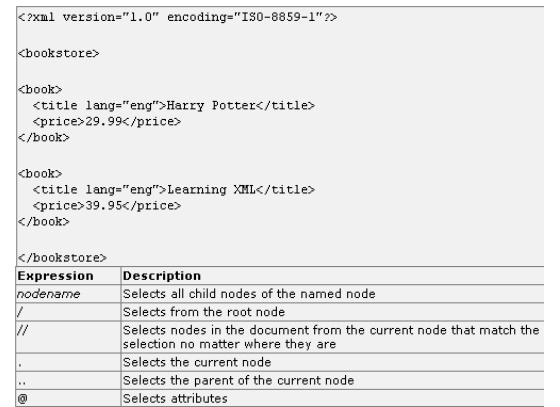

Predicates:
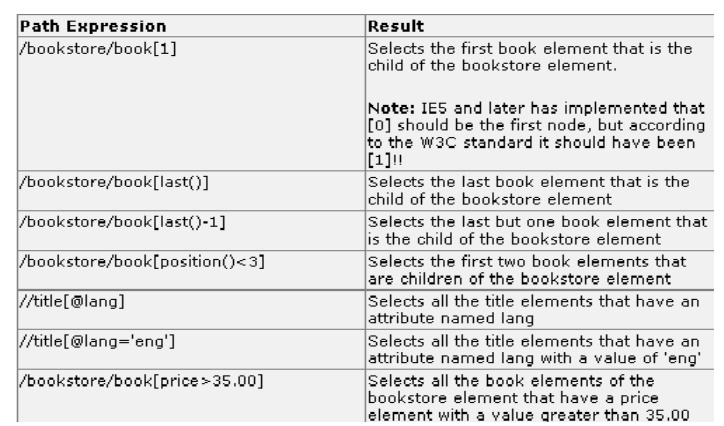
Selecting
Unknown Nodes:
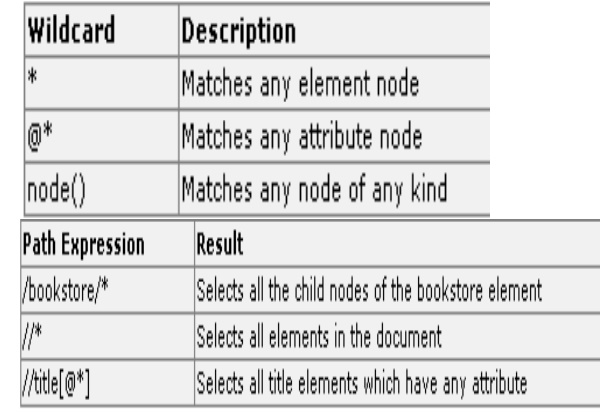
Selecting
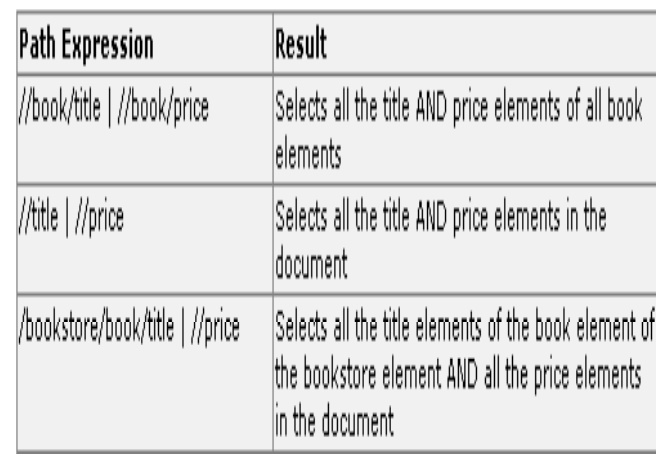
several paths:
XQuery:
XQuery is the language for querying XML data.
XQuery for XML is like SQL for databases. XQuery is built on XPath expressions.
XQuery is supported by all the major database engines (IBM, Oracle, Microsoft,
etc.). XQuery is a W3C Recommendation .
<title lang="en">XQuery Kick
Start</title>
<author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year>
<price>49.99</price> </book>
- <book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
Functions:
XQuery uses functions to extract data from XML
documents. The doc() function is used to open the "books.xml" file:
doc("books.xml"), Path Expressions
XQuery uses path expressions to navigate
through elements in an XML document.The following path expression is used to
select all the title elements in the "books.xml" file: doc("books.xml")/bookstore/book/title(/bookstore
selects the bookstore element, /book selects all the book elements under the
bookstore element, and /title selects all the title elements under each book
element), The XQuery above will extract the following:
<title lang="en">Everyday
Italian</title> <title lang="en">Harry
Potter</title>
<title lang="en">XQuery Kick
Start</title> <title lang="en">Learning XML</title>
Predicates:
XQuery uses predicates to limit the extracted
data from XML documents. The following predicate is used to select all the book
elements under the bookstore element that have a price element with a value
that is less than 30: doc("books.xml")/bookstore/book[price<30]The
XQuery above will extract the following:
<book category="CHILDREN">
<title lang="en">Harry Potter</title> <author>J K.
Rowling</author> <year>2005</year>
<price>29.99</price>
</book>
With
FLWOR:
FLWOR is an acronym for "For, Let, Where, Order by, Return". The for clause selects all book elements
under the bookstore element into a variable called $x.The where clause selects only book elements with a price element with a
value greater than 30.The order by
clause defines the sort-order. Will be sort by the title element.The return clause specifies what should be
returned. Here it returns the title elements.
Example:
doc("books.xml")/bookstore/book[price>30]/title
The following FLWOR expression will select
exactly the same as the path expression
above:
for $x in
doc("books.xml")/bookstore/book where $x/price>30 return $x/title
The result will be:
<title lang="en">XQuery Kick
Start</title> <title lang="en">Learning XML</title>
With FLWOR you can sort the result:
for $x in
doc("books.xml")/bookstore/book where $x/price>30 order by
$x/title return
$x/title
Related Topics