Chapter: An Introduction to Parallel Programming : Why Parallel Computing?
Why we Need to Write Parallel Programs
WHY WE NEED TO WRITE PARALLEL PROGRAMS
Most programs that have been written for conventional, single-core systems cannot exploit the presence of multiple cores. We can run multiple instances of a program on a multicore system, but this is often of little help. For example, being able to run multiple instances of our favorite game program isn’t really what we want—we want the program to run faster with more realistic graphics. In order to do this, we need to either rewrite our serial programs so that they’re parallel, so that they can make use of multiple cores, or write translation programs, that is, programs that will automatically convert serial programs into parallel programs. The bad news is that researchers have had very limited success writing programs that convert serial programs in languages such as C and C++ into parallel programs.
This isn’t terribly surprising. While we can write programs that recognize com-mon constructs in serial programs, and automatically translate these constructs into efficient parallel constructs, the sequence of parallel constructs may be terribly inef-ficient. For example, we can view the multiplication of two n n matrices as a sequence of dot products, but parallelizing a matrix multiplication as a sequence of parallel dot products is likely to be very slow on many systems.
An efficient parallel implementation of a serial program may not be obtained by finding efficient parallelizations of each of its steps. Rather, the best parallelization may be obtained by stepping back and devising an entirely new algorithm.
As an example, suppose that we need to compute n values and add them together. We know that this can be done with the following serial code:
sum = 0;
for (i = 0; i < n; i++) {
x = Compute next value(. . .); sum += x;
}
Now suppose we also have p cores and p is much smaller than n. Then each core can form a partial sum of approximately n=pvalues:
my sum = 0;
my first i = . . . ; my last i = . . . ;
for (my i = my first i; my i < my last i; my i++){my x = Compute next value(. . .);
my sum += my x;
}
Here the prefix my indicates that each core is using its own, private variables, and each core can execute this block of code independently of the other cores.
After each core completes execution of this code, its variable my sum will store the sum of the values computed by its calls to Compute next value. For example, if there are eight cores, n = 24, and the 24 calls to Compute next value return the values
1, 4, 3, 9, 2, 8, 5, 1, 1, 6, 2, 7, 2, 5, 0, 4, 1, 8, 6, 5, 1, 2, 3, 9, then the values stored in my sum might be
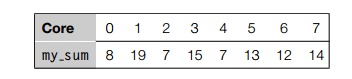
Here we’re assuming the cores are identified by nonnegative integers in the range 0, 1, .... , p 1, where p is the number of cores.
When the cores are done computing their values of my sum, they can form a global sum by sending their results to a designated “master” core, which can add their results:
if (I’m the master core){sum = my x;
for each core other than myself{receive value from core;
sum += value;
}
} else {
} send my x to the master;
In our example, if the master core is core 0, it would add the values 8 + 19 + 7 + 15 + 7 + 13 + 12 + 14 = 95.
But you can probably see a better way to do this—especially if the number of cores is large. Instead of making the master core do all the work of computing the final sum, we can pair the cores so that while core 0 adds in the result of core 1, core 2 can add in the result of core 3, core 4 can add in the result of core 5 and so on. Then we can repeat the process with only the even-ranked cores: 0 adds in the result of 2, 4 adds in the result of 6, and so on. Now cores divisible by 4 repeat the process, and so on. See Figure 1.1. The circles contain the current value of each core’s sum, and the lines with arrows indicate that one core is sending its sum to another core. The plus signs indicate that a core is receiving a sum from another core and adding the received sum into its own sum.
For both “global” sums, the master core (core 0) does more work than any other core, and the length of time it takes the program to complete the final sum should be the length of time it takes for the master to complete. However, with eight cores, the master will carry out seven receives and adds using the first method, while with the second method it will only carry out three. So the second method results in an improvement of more than a factor of two. The difference becomes much more
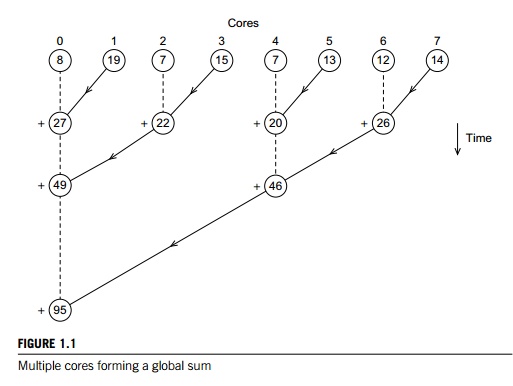
dramatic with large numbers of cores. With 1000 cores, the first method will require 999 receives and adds, while the second will only require 10, an improvement of almost a factor of 100!
The first global sum is a fairly obvious generalization of the serial global sum: divide the work of adding among the cores, and after each core has computed its part of the sum, the master core simply repeats the basic serial addition—if there are p cores, then it needs to add p values. The second global sum, on the other hand, bears little relation to the original serial addition.
The point here is that it’s unlikely that a translation program would “discover” the second global sum. Rather there would more likely be a predefined efficient global sum that the translation program would have access to. It could “recog-nize” the original serial loop and replace it with a precoded, efficient, parallel global sum.
We might expect that software could be written so that a large number of common serial constructs could be recognized and efficiently parallelized, that is, modified so that they can use multiple cores. However, as we apply this principle to ever more complex serial programs, it becomes more and more difficult to recognize the construct, and it becomes less and less likely that we’ll have a precoded, efficient parallelization.
Thus, we cannot simply continue to write serial programs, we must write parallel programs, programs that exploit the power of multiple processors.
Related Topics