Chapter: Fundamentals of Database Systems : Transaction Processing, Concurrency Control, and Recovery : Database Recovery Techniques
NO-UNDO/REDO Recovery Based on Deferred Update
NO-UNDO/REDO Recovery Based on Deferred Update
The idea behind deferred update is to defer or postpone any actual
updates to the database on disk until the transaction completes its execution
successfully and reaches its commit point.
During transaction execution, the updates are recorded only in the log
and in the cache buffers. After the transaction reaches its commit point and
the log is force-written to disk, the updates are recorded in the database. If
a transaction fails before reaching its commit point, there is no need to undo
any operations because the transaction has not affected the database on disk in
any way. Therefore, only REDO-type log entries are needed in the log, which
include the new value (AFIM) of the item written by a write operation. The
UNDO-type log entries are not needed since no undoing of operations will be required during
recovery. Although this may sim-plify the recovery process, it cannot be used
in practice unless transactions are short and each transaction changes few
items. For other types of transactions, there is the potential for running out
of buffer space because transaction changes must be held in the cache buffers
until the commit point.
We can state a typical deferred update protocol as follows:
1. A transaction cannot change the
database on disk until it reaches its commit point.
2. A transaction does not reach its
commit point until all its REDO-type log entries are recorded in
the log and the log buffer is
force-written to disk.
Notice that step 2 of this protocol is a restatement of the write-ahead
logging (WAL) protocol. Because the database is never updated on disk until
after the transaction commits, there is never a need to UNDO any operations. REDO is needed in case the system
fails after a transaction commits but before all its changes are recorded in
the database on disk. In this case, the transaction operations are redone from
the log entries during recovery.
For multiuser systems with concurrency control, the concurrency control
and recovery processes are interrelated. Consider a system in which concurrency
control uses strict two-phase locking, so the locks on items remain in effect until the trans-action reaches its commit
point. After that, the locks can be released. This ensures strict and serializable schedules.
Assuming that [checkpoint] entries are included in the log, a possible recovery algorithm for this
case, which we call RDU_M (Recovery using Deferred Update
in a Multiuser environment), is given next.
Procedure RDU_M (NO-UNDO/REDO with checkpoints). Use two lists of transactions
maintained by the system: the committed transactions T since the last checkpoint (commit
list), and the active transactions T
(active list). REDO all the
WRITE operations of the committed
transactions from the log, in the order in which they were
written into the log. The transactions that are active and did not commit are effectively
canceled and must be resubmitted.
The REDO procedure is defined as follows:
Procedure REDO
(WRITE_OP). Redoing a write_item operation WRITE_OP consists of examining its log
entry [write_item, T, X,
new_value] and setting the value of item X
in the database to new_value, which
is the after image (AFIM).
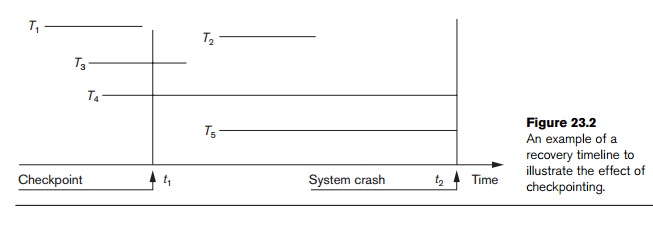
Figure
23.2 illustrates a timeline for a possible schedule of executing transactions.
When the checkpoint was taken at time t1,
transaction T1 had
committed, whereas transactions T3
and T4 had not. Before the
system crash at time t2, T3 and T2 were committed but not T4 and T5.
According to the RDU_M method,
there is no need to redo the write_item
operations of transaction T1—or
any transactions committed before the last checkpoint time t1. The write_item
operations of T2 and T3 must be redone, however,
because both transactions reached their commit points after the last
checkpoint. Recall that the log is force-written before committing a
transaction. Transactions T4
and T5 are ignored: They
are effectively canceled or rolled back because none of their write_item operations were recorded in the
database on disk under the deferred update protocol.
We can
make the NO-UNDO/REDO recovery
algorithm more efficient by noting
that, if a data item X has been
updated—as indicated in the log entries—more than once by committed
transactions since the last checkpoint, it is only necessary to REDO the last update of X from the log during recovery because the other
updates would be overwritten by this
last REDO. In this case, we start from the end of the log; then, whenever an
item is redone, it is added to a list of redone items. Before REDO is applied to an item, the list
is checked; if the item appears on the list, it is not redone again, since its
last value has already been recovered.
If a
transaction is aborted for any reason (say, by the deadlock detection method),
it is simply resubmitted, since it has not changed the database on disk. A
drawback of the method described here is that it limits the concurrent
execution of transactions because all
write-locked items remain locked until the transaction reaches its commit point. Additionally, it may require
excessive buffer space to hold all updated items until the transactions commit. The method’s main benefit is that
transaction operations never need to be
undone, for two reasons:
1. A transaction does not record any changes in the
database on disk until after it reaches its commit point—that is, until it
completes its execution success-fully. Hence, a transaction is never rolled
back because of failure during transaction execution.
2. A transaction will never read the value of an item
that is written by an uncommitted transaction, because items remain locked
until a transaction reaches its commit point. Hence, no cascading rollback will
occur.
Figure
23.3 shows an example of recovery for a multiuser system that utilizes the
recovery and concurrency control method just described.
Related Topics