Chapter: Fundamentals of Database Systems : Transaction Processing, Concurrency Control, and Recovery : Introduction to Transaction Processing Concepts and Theory
Introduction to Transaction Processing
Introduction to Transaction Processing
In this section we discuss the concepts of concurrent execution of
transactions and recovery from transaction failures. Section 21.1.1 compares
single-user and multi-user database systems and demonstrates how concurrent
execution of transactions can take place in multiuser systems. Section 21.1.2
defines the concept of transaction and presents a simple model of transaction
execution based on read and write database operations. This model is used as
the basis for defining and formalizing concurrency control and recovery
concepts. Section 21.1.3 uses informal examples to show why concurrency control
techniques are needed in multiuser systems. Finally, Section 21.1.4 discusses
why techniques are needed to handle recovery from system and transaction
failures by discussing the different ways in which transactions can fail while
executing.
1. Single-User versus
Multiuser Systems
One criterion for classifying a database system is according to the
number of users who can use the system concurrently.
A DBMS is single-user if at most one
user at a time can use the system, and it is multiuser if many users can use the system—and hence access the
database—concurrently. Single-user DBMSs are mostly restricted to personal
computer systems; most other DBMSs are multiuser. For example, an airline
reservations system is used by hundreds of travel agents and reservation clerks
concurrently. Database systems used in banks, insurance agencies, stock
exchanges, supermarkets, and many other applications are multiuser systems. In
these systems, hundreds or thousands of users are typically operating on the
data-base by submitting transactions concurrently to the system.
Multiple users can access databases—and use computer
systems—simultaneously because of the concept of multiprogramming, which allows the operating system of the computer
to execute multiple programs—or processes—at
the same time. A single central processing unit (CPU) can only execute at most
one process at a time. However, multiprogramming
operating systems execute some commands from one process, then suspend that
process and execute some commands from the next
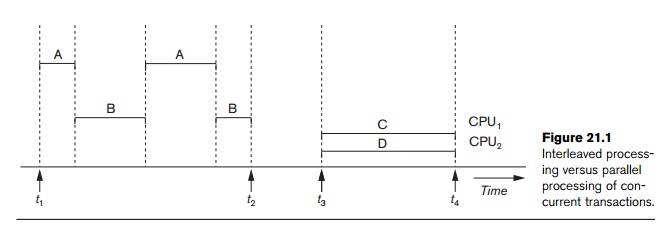
process, and so on. A process is resumed at the point where it was
suspended when-ever it gets its turn to use the CPU again. Hence, concurrent
execution of processes is actually interleaved,
as illustrated in Figure 21.1, which shows two processes, A and B, executing
concurrently in an interleaved fashion. Interleaving keeps the CPU busy when a
process requires an input or output (I/O) operation, such as reading a block
from disk. The CPU is switched to execute another process rather than remaining
idle during I/O time. Interleaving also prevents a long process from delaying
other processes.
If the computer system has multiple hardware processors (CPUs), parallel processing of multiple
processes is possible, as illustrated by processes C and D in Figure 21.1. Most of the theory concerning
concurrency control in databases is developed in terms of interleaved concurrency, so for the remainder of this chapter we
assume this model. In a multiuser DBMS, the stored data items are the primary
resources that may be accessed concurrently by interactive users or application
programs, which are constantly retrieving information from and modifying the
database.
2. Transactions, Database
Items, Read and Write Operations, and DBMS Buffers
A transaction is an executing
program that forms a logical unit of database processing. A transaction
includes one or more database access operations—these can include insertion,
deletion, modification, or retrieval operations. The database operations that
form a transaction can either be embedded within an application program or they
can be specified interactively via a high-level query language such as SQL. One
way of specifying the transaction boundaries is by specifying explicit begin transaction and end transaction statements in an
application program; in this case,
all database access operations between the two are considered as forming one
transaction. A single application program may contain more than one
transaction if it contains several transaction boundaries. If the database
operations in a transaction do not update the database but only retrieve data,
the transaction is called a read-only
transaction; otherwise it is known as a read-write transaction.
The database model that is
used to present transaction processing concepts is quite simple when compared
to the data models that we discussed earlier in the book, such as the
relational model or the object model. A database
is basically represented as a collection of named
data items. The size of a data item is called its granularity. A data item
can be a database record, but it can
also be a larger unit such as a whole disk
block, or even a smaller unit such as an individual field (attribute) value of some
record in the database. The transaction processing concepts we discuss are
inde-pendent of the data item granularity (size) and apply to data items in
general. Each data item has a unique name,
but this name is not typically used by the programmer; rather, it is just a
means to uniquely identify each data item.
For example, if the data item granularity is one disk block, then the disk
block address can be used as the data item name. Using this simplified database
model, the basic database access operations that a transaction can include are
as follows:
read_item(X). Reads a database item
named X into a program
variable. To simplify our notation,
we assume that the program variable is
also named X.
write_item(X). Writes the value of
program variable X
into the database item named X.
As we discussed in Chapter 17, the basic unit of data transfer from disk
to main memory is one block. Executing a read_item(X) command includes the following steps:
1.
Find the address of the disk
block that contains item X.
2.
Copy that disk block into a buffer
in main memory (if that disk block is not already in some main memory buffer).
3.
Copy item X from the buffer to the program variable named X.
Executing a write_item(X) command includes the following steps:
1.
Find the address of the disk
block that contains item X.
2.
Copy that disk block into a
buffer in main memory (if that disk block is not already in some main memory
buffer).
3.
Copy item X from the program variable named X into its correct location in the buffer.
4.
Store the updated block from the
buffer back to disk (either immediately or at some later point in time).
It is step 4 that actually updates the database on disk. In some cases
the buffer is not immediately stored to disk, in case additional changes are to
be made to the buffer. Usually, the decision about when to store a modified
disk block whose contents are in a main memory buffer is handled by the
recovery manager of the DBMS in cooperation with the underlying operating
system. The DBMS will maintain in the database
cache a number of data buffers in
main memory. Each buffer typically holds
the contents of one database disk block, which contains some of the database
items being processed. When these buffers are all occupied, and additional
database disk blocks must be copied into memory, some buffer replacement policy
is used to choose which of the current buffers is to be replaced. If the chosen
buffer has been modified, it must be written back to disk before it is reused.
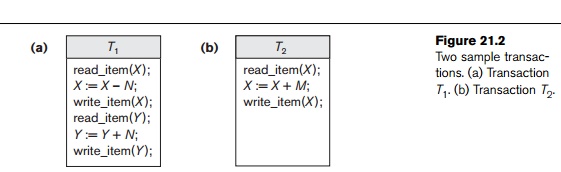
A transaction includes read_item and write_item operations to access and update the database. Figure 21.2 shows
examples of two very simple transactions. The read-set of a transaction is the set of all items that the
transaction reads, and the write-set
is the set of all items that the transaction writes. For example, the read-set
of T1 in Figure 21.2 is {X, Y}
and its write-set is also {X, Y}.
Concurrency control and recovery mechanisms are mainly concerned with
the database commands in a transaction. Transactions submitted by the various
users may execute concurrently and may access and update the same database
items. If this concurrent execution is uncontrolled,
it may lead to problems, such as an inconsistent database. In the next section
we informally introduce some of the problems that may occur.
3. Why Concurrency
Control Is Needed
Several
problems can occur when concurrent transactions execute in an uncontrolled
manner. We illustrate some of these problems by referring to a much simplified
airline reservations database in which a record is stored for each airline
flight. Each record includes the number
of reserved seats on that flight as a named
(uniquely identifiable) data item,
among other information. Figure 21.2(a) shows a transaction T1 that transfers N reservations from one flight whose number of reserved
seats is stored in the database item named X
to another flight whose number of reserved seats is stored in the database item
named Y. Figure 21.2(b) shows a
simpler trans-action T2
that just reserves M seats on the
first flight (X) referenced in
transaction T1.2 To simplify our example, we do not show
additional portions of the transactions, such as checking whether a flight has
enough seats available before reserving additional seats.
When a
database access program is written, it has the flight number, flight date, and
the number of seats to be booked as parameters; hence, the same program can be
used to execute many different
transactions, each with a different flight number, date, and number of
seats to be booked. For concurrency control purposes, a trans-action is a particular execution of a program on a
specific date, flight, and number of seats. In Figure 21.2(a) and (b), the
transactions T1 and T2 are specific executions of the programs that refer to the specific
flights whose numbers of seats are stored in data items X and Y in the database.
Next we discuss the types of problems we may encounter with these two simple
transactions if they run concurrently.
The Lost Update Problem. This
problem occurs when two transactions that
access
the same database items have their operations interleaved in a way that makes
the value of some database items incorrect. Suppose that transactions T1 and T2 are submitted at approximately the same time, and
suppose that their operations are interleaved as shown in Figure 21.3(a); then
the final value of item X is
incorrect because T2 reads
the value of X before T1
changes it in the database, and hence the updated value resulting from T1 is lost. For example, if X = 80 at the start (originally there
were 80 reservations on the flight), N
= 5 (T1 transfers 5 seat
reservations from the flight corresponding to X to the flight corresponding to Y), and M = 4 (T2 reserves 4 seats on X), the final result should be X = 79. However, in the interleaving of
operations shown in Figure 21.3(a), it is X
= 84 because the update in T1
that removed the five seats from X
was lost.
The Temporary Update (or Dirty Read) Problem. This
problem occurs when one
transaction updates a database item and then the transaction fails for some
rea-son (see Section 21.1.4). Meanwhile, the updated item is accessed (read) by
another transaction before it is changed back to its original value. Figure
21.3(b) shows an example where T1
updates item X and then fails before
completion, so the system must change X
back to its original value. Before it can do so, however, transaction T2 reads the temporary value of X, which will not be recorded permanently in the data-base because
of the failure of T1. The
value of item X that is read by T2 is called dirty data because it has been created by a transaction that has not
completed and committed yet; hence, this problem is also known as the dirty read problem.
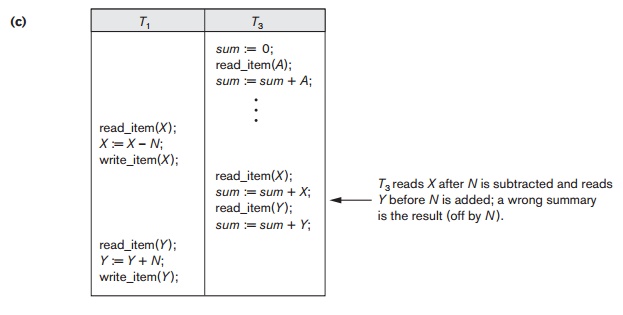
The Incorrect Summary Problem. If one
transaction is calculating an aggregate
summary
function on a number of database items while other transactions are updating
some of these items, the aggregate function may calculate some values before
they are updated and others after they are updated. For example, suppose that a
transaction T3 is
calculating the total number of reservations on all the flights; meanwhile,
transaction T1 is
executing. If the interleaving of operations shown in Figure 21.3(c) occurs, the
result of T3 will be off
by an amount N because T3 reads the value of X after N seats have been subtracted
from it but reads the value of Y before those N seats have been added to it.

The Unrepeatable Read Problem. Another
problem that may occur is called
unrepeatable read, where a
transaction T reads the same item
twice and the item is changed by
another transaction T between the two
reads. Hence, T receives different values for its two reads of
the same item. This may occur, for example, if during an airline reservation transaction, a customer inquires
about seat availability on several flights. When the customer decides on a
particular flight, the transaction then reads the number of seats on that
flight a second time before completing the reservation, and it may end up
reading a different value for the item.
4. Why Recovery Is
Needed
Whenever
a transaction is submitted to a DBMS for execution, the system is respon-sible
for making sure that either all the operations in the transaction are completed
successfully and their effect is recorded permanently in the database, or that
the transaction does not have any effect on the database or any other
transactions. In the first case, the transaction is said to be committed, whereas in the second case,
the transaction is aborted. The DBMS
must not permit some operations of a trans-action T to be applied to the database while other operations of T are not, because the whole transaction is a logical unit of database processing. If
a transaction fails after executing
some of its operations but before executing all of them, the opera-tions
already executed must be undone and have no lasting effect.
Types of Failures. Failures
are generally classified as transaction, system, and media failures. There are several
possible reasons for a transaction to fail in the mid-dle of execution:
A
computer failure (system crash). A hardware, software, or network
error occurs in the computer system
during transaction execution. Hardware crashes are usually media failures—for
example, main memory failure.
A transaction or system error. Some operation in the transaction may cause it to fail, such as integer overflow or division by zero. Transaction failure may also occur because of erroneous parameter values or because of a logical programming error.3 Additionally, the user may interrupt the transaction during its execution.
Local
errors or exception conditions detected by the transaction. During transaction execution, certain
conditions may occur that necessitate cancellation of the transaction. For
example, data for the transaction may not be found. An exception condition,
such as insufficient account balance in a banking database, may cause a
transaction, such as a fund withdrawal, to be canceled. This exception could be
programmed in the transaction itself, and in such a case would not be
considered as a transaction failure.
Concurrency
control enforcement. The concurrency control method (see Chapter 22) may decide to abort a
transaction because it violates serializability (see Section 21.5), or it may
abort one or more transactions to resolve a state of deadlock among several
transactions (see Section 22.1.3). Transactions aborted because of
serializability violations or deadlocks are typically restarted automatically
at a later time.
Disk
failure. Some disk blocks may lose their data because of a read or write malfunction or because of a disk
read/write head crash. This may happen during a read or a write operation of
the transaction.
Physical
problems and catastrophes. This refers to an endless list of problems that
includes power or air-conditioning failure, fire, theft, sabotage, overwriting
disks or tapes by mistake, and mounting of a wrong tape by the operator.
Failures
of types 1, 2, 3, and 4 are more common than those of types 5 or 6. Whenever a
failure of type 1 through 4 occurs, the system must keep sufficient information
to quickly recover from the failure. Disk failure or other catastrophic failures
of type 5 or 6 do not happen frequently; if they do occur, recovery is a major
task. We discuss recovery from failure in Chapter 23.
The
concept of transaction is fundamental to many techniques for concurrency
control and recovery from failures.
Related Topics