Chapter: Fundamentals of Database Systems : Transaction Processing, Concurrency Control, and Recovery : Concurrency Control Techniques
Granularity of Data Items and Multiple Granularity Locking
Granularity of Data Items and Multiple Granularity Locking
All concurrency control techniques assume that the database is formed of
a number of named data items. A database item could be chosen to be one of the
following:
1. A database record
2. A field value of a database record
3. A disk block
4. A whole file
5. The whole database
The granularity can affect the performance of concurrency control and
recovery. In Section 22.5.1, we discuss some of the tradeoffs with regard to
choosing the granularity level used for locking, and in Section 22.5.2 we
discuss a multiple granularity locking scheme, where the granularity level
(size of the data item) may be changed dynamically.
1. Granularity Level
Considerations for Locking
The size of data items is often called the data item granularity. Fine
granularity refers to small item sizes, whereas coarse granularity refers to large item sizes. Several tradeoffs
must be considered in choosing the data item size. We will discuss data item
size in the context of locking, although similar arguments can be made for
other concurrency control techniques.
First, notice that the larger the data item size is, the lower the
degree of concurrency permitted. For example, if the data item size is a disk
block, a transaction T that needs to
lock a record B must lock the whole
disk block X that contains B because a lock is associated with the
whole data item (block). Now, if another transaction S wants to lock a different record C that happens to reside in the same block X in a conflicting lock mode, it is forced to wait. If the data
item size was a single record, transaction S
would be able to proceed, because it would be locking a different data item
(record).
On the other hand, the smaller the data item size is, the more the
number of items in the database. Because every item is associated with a lock,
the system will have a larger number of active locks to be handled by the lock
manager. More lock and unlock operations will be performed, causing a higher
overhead. In addition, more storage space will be required for the lock table.
For timestamps, storage is required for the read_TS and write_TS for each data item, and there will be similar overhead for handling a
large number of items.
Given the above tradeoffs, an obvious question can be asked: What is the
best item size? The answer is that it depends
on the types of transactions involved. If a typical transaction accesses a
small number of records, it is advantageous to have the data item granularity
be one record. On the other hand, if a transaction typically accesses many
records in the same file, it may be better to have block or file granularity so
that the transaction will consider all those records as one (or a few) data
items.
2. Multiple Granularity
Level Locking
Since the best granularity size depends on the given transaction, it
seems appropriate that a database system should support multiple levels of
granularity, where the granularity level can be different for various mixes of
transactions. Figure 22.7 shows a simple granularity hierarchy with a database
containing two files, each file containing several disk pages, and each page
containing several records. This can be used to illustrate a multiple granularity level 2PL
protocol, where a lock can be requested at any level. However, additional types
of locks will be needed to support such a protocol efficiently.
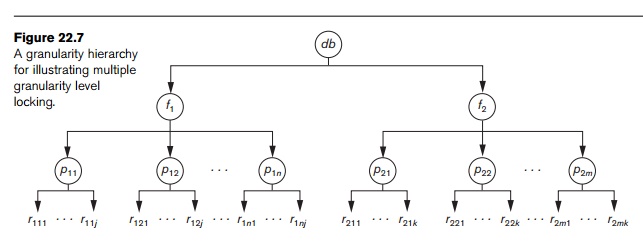
Consider
the following scenario, with only shared and exclusive lock types, that refers
to the example in Figure 22.7. Suppose transaction T1 wants to update all
the records in file f1,
and T1 requests and is
granted an exclusive lock for f1.
Then all of f1’s pages (p11 through p1n)—and the records contained on those pages—are locked in
exclusive mode. This is beneficial for T1
because setting a single file-level lock is more efficient than setting n page-level locks or having to lock
each individual record. Now suppose another transaction T2 only wants to read record r1nj from page
p1n of file f1;
then T2 would request a
shared record-level lock on r1nj. However, the database system
(that is, the transaction manager or more specifically the lock manager) must
verify the compatibility of the requested lock with already held locks. One way
to verify this is to traverse the tree from the leaf r1nj to p1n to f1
to db. If at any time a conflicting
lock is held on any of those items, then the lock request for r1nj is denied and T2 is blocked and must wait. This
traversal would be fairly efficient.
However,
what if transaction T2’s
request came before transaction T1’s request? In this case,
the shared record lock is granted to T2
for r1nj, but when T1’s
file-level lock is requested, it is quite difficult for the lock manager to
check all nodes (pages and records) that are descendants of node f1 for a lock conflict. This
would be very inefficient and would defeat the purpose of having multiple
granularity level locks.
To make
multiple granularity level locking practical, additional types of locks, called
intention locks, are needed. The
idea behind intention locks is for a transaction to indicate, along the path from the root to the desired node, what
type of lock (shared or exclusive) it will require from one of the node’s
descendants. There are three types of intention locks:
1. Intention-shared
(IS) indicates that one or more shared locks will be requested on some
descendant node(s).
2. Intention-exclusive
(IX) indicates that one or more exclusive locks will be requested on some
descendant node(s).
3. Shared-intention-exclusive
(SIX) indicates that the current node is locked in shared mode but that one or
more exclusive locks will be requested on some descendant node(s).
The
compatibility table of the three intention locks, and the shared and exclusive locks,
is shown in Figure 22.8. Besides the introduction of the three types of
intention locks, an appropriate locking protocol must be used. The multiple granularity locking (MGL) protocol consists of the
following rules:
1. The lock
compatibility (based on Figure 22.8) must be adhered to.
2. The root
of the tree must be locked first, in any mode.
3. A node N can be locked by a transaction T in S or IS mode only if the parent
node N is already locked by
transaction T in either IS or IX
mode.
4. A node N can be locked by a transaction T in X, IX, or SIX mode only if the
parent of node N is already locked by
transaction T in either IX or SIX
mode.
5. A
transaction T can lock a node only if
it has not unlocked any node (to enforce the 2PL protocol).

6. A
transaction T can unlock a node, N, only if none of the children of node N are currently locked by T.
Rule 1
simply states that conflicting locks cannot be granted. Rules 2, 3, and 4 state
the conditions when a transaction may lock a given node in any of the lock
modes. Rules 5 and 6 of the MGL protocol enforce 2PL rules to produce
serializable schedules. To illustrate the MGL protocol with the database
hierarchy in Figure 22.7, consider the following three transactions:
1.
T1 wants to update record r111 and record r211.
2.
T2 wants to update all records on
page p12.
3.
T3 wants to read record r11j and the entire f2 file.
Figure
22.9 shows a possible serializable schedule for these three transactions. Only
the lock and unlock operations are shown. The notation <lock_type>(<item>) is used to display the
locking operations in the schedule.
The
multiple granularity level protocol is especially suited when processing a mix
of transactions that include (1) short transactions that access only a few
items (records or fields) and (2) long transactions that access entire files.
In this environment, less transaction blocking and less locking overhead is
incurred by such a protocol when compared to a single level granularity locking
approach.
Related Topics