Chapter: An Introduction to Parallel Programming : Distributed-Memory Programming with MPI
Distributed-Memory Programming with MPI
Distributed-Memory Programming with MPI
Recall that the world of parallel multiple
instruction, multiple data, or MIMD, computers is, for the most part, divided
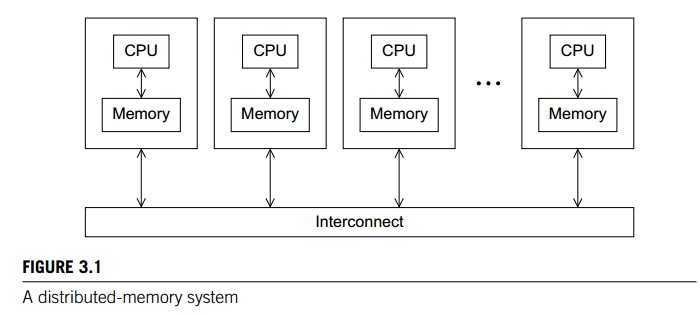
into distributed-memory and shared-memory systems. From a programmer’s point of view, a distributed-memory
system consists of a collection of core-memory pairs connected by a network,
and the memory asso-ciated with a core is directly accessible only to that
core. See Figure 3.1. On the other hand, from a programmer’s point of view, a
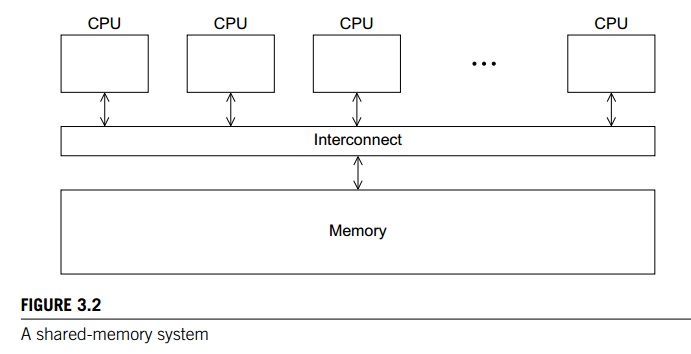
shared-memory system consists of a col-lection of cores connected to a globally
accessible memory, in which each core can have access to any memory location.
See Figure 3.2. In this chapter we’re going to start looking at how to program
distributed-memory systems using message-passing.
Recall that in message-passing programs, a
program running on one core-memory pair is usually called a process, and two processes can communicate by calling
func-tions: one process calls a send function and the other calls a receive function. The implementation of message-passing that we’ll be
using is called MPI, which is an abbreviation of Message-Passing Interface. MPI is not a new programming lan-guage. It
defines a library of functions that can be called from C, C++, and Fortran programs. We’ll learn about some
of MPI’s different send and receive functions. We’ll also learn about some
“global” communication functions that can involve more than two processes.
These functions are called collective communications. In the pro-cess of learning about all of these MPI
functions, we’ll also learn about some of the
fundamental issues involved in writing
message-passing programs–issues such as data partitioning and I/O in
distributed-memory systems. We’ll also revisit the issue of parallel program
performance.
GETTING STARTED
Perhaps the first program
that many of us saw was some variant of the “hello, world” program in Kernighan
and Ritchie’s classic text [29]:
#include <stdio.h>
int
main(void) {
printf("hello, worldnn");
return
0;
}
Let’s write a program similar
to “hello, world” that makes some use of MPI. Instead of having each process
simply print a message, we’ll designate one process to do the output, and the
other processes will send it messages, which it will print.
In parallel programming, it’s
common (one might say standard) for the processes to be identified by
nonnegative integer ranks. So if there are p processes, the pro-cesses
will have ranks 0, 1, 2, ...., p 1. For our parallel “hello,
world,” let’s make process 0 the designated process, and the other processes
will send it messages. See Program 3.1.
1.1 Compilation and execution
The details of compiling and running the
program depend on your system, so you may need to check with a local expert. However,
recall that when we need to be explicit, we’ll assume that we’re using a text
editor to write the program source, and the command line to compile and run.
Many systems use a command called mpicc for compilation.
$ mpicc -g -Wall -o mpi _hello mpi _hello.c
Typically, mpicc is a script that’s a wrapper for the C compiler. A wrapper
script is a script whose main purpose is to run some program. In this
case, the program is the C compiler. However, the wrapper simplifies the
running of the compiler by telling it where to find the necessary header files
and which libraries to link with the object file.
#include <stdio.h>
2 #include <string.h> /* For strlen */
3 #include <mpi.h> /* For
MPI functions, etc */
const int MAX STRING = 100;
int main(void) {
chargreeting[MAX_STRING];
9 int comm._sz; /* Number
of processes */
10 int my_rank; /* My
process rank */
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &comm._sz);
MPI_Comm_rank(MPI_COMM_WORLD,
&my_rank);
if (my rank != 0) {
sprintf(greeting, "Greetings
from process %d of %d!", my_rank,
comm._sz);
MPI_Send(greeting,
strlen(greeting)+1, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
g else {
printf("Greetings from process
%d of %d!nn", my_rank, comm._sz);
for (int q = 1; q < comm sz; q++)
{
MPI_Recv(greeting, MAX_STRING, MPI_CHAR,
q,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%s\n", greeting);
}
}
MPI_Finalize();
return 0;
}
/ main /
Program
3.1: MPI_program that prints greetings from the processes
Many systems also support
program startup with mpiexec:
$ mpiexec -n <number of processes> ./mpi_hello
So to run the program with
one process, we’d type
$ mpiexec -n 1 ./mpi_hello
and to run the program with
four processes, we’d type
$ mpiexec n 4 ./mpi_hello
With one process the program’s
output would be
Greetings from process 0 of 1!
and with four processes the
program’s output would be
Greetings from process 0 of 4!
Greetings from process 1 of 4!
Greetings from process 2 of 4!
Greetings from process 3 of 4!
How do we get from invoking mpiexec to one or more lines of greetings? The mpiexec command tells the system to start <number of processes> instances of our <mpi hello> program. It may also tell the system which
core should run each instance of the program. After the processes are running,
the MPI implementation takes care of making sure that the processes can
communicate with each other.
1.2 MPI programs
Let’s take a closer look at the program. The
first thing to observe is that this is a C program. For example, it includes the standard C header files stdio.h and string.h. It also has a main function just like any other C program.
However, there are many parts of the program which are new. Line 3 includes the
mpi.h header file. This contains prototypes of MPI functions, macro
definitions, type definitions, and so on; it contains all the definitions and
declarations needed for compiling an MPI program.
The second thing to observe is that all of the
identifiers defined by MPI start with the string MPI . The first letter following the underscore is
capitalized for function names and MPI-defined types. All of the letters in
MPI-defined macros and con-stants are capitalized, so there’s no question about
what is defined by MPI and what’s defined by the user program.
1.3 MPI_Init and MPI_Finalize
In Line 12 the call to MPI_Init tells the MPI system to do all of the necessary setup. For
example, it might allocate storage for message buffers, and it might decide
which process gets which rank. As a rule of thumb, no other MPI functions
should be called before the program calls MPI_Init. Its syntax is int MPI_Init(
Int* argc_p /*
in/out */,
Char*** argv_p /*
in/out */);
The arguments, argc_p and argv_p, are pointers to the arguments to main, argc, and argv. However, when our program doesn’t use these
arguments, we can just pass NULL for both. Like most MPI functions, MPI_Init returns an int error
code, and in most cases we’ll ignore these error codes.
In Line 30 the call to MPI_Finalize tells the MPI system that we’re done using MPI, and that any
resources allocated for MPI can be freed. The syntax is quite simple:
int MPI_Finalize(void);
In general, no MPI functions should be called
after the call to MPI Finalize.
Thus, a typical MPI program has the following
basic outline:
. . .
#include <mpi.h>
. . .
int
main(int argc, char* argv[]) {
. . .
/* No MPI calls before this */
MPI_Init(&argc, &argv);
. . .
MPI_Finalize();
/* No MPI calls after this */
. . .
return
0;
}
However, we’ve already seen
that it’s not necessary to pass pointers to argc and argv to MPI_Init. It’s also not necessary that the calls to MPI_Init and MPI_Finalize be in main.
1.4 Communicators, MPI_Comm_size and MPI_Comm rank
In MPI a communicator is a collection of processes
that can send messages to each other. One of the purposes of MPI_Init is to define a communicator that consists of
all of the processes started by the user when she started the program. This
commu-nicator is called MPI_COMM_WORLD. The function calls in Lines
13 and 14 are getting information about MPI_COMM_WORLD. Their syntax is
int MPI_Comm_size(
MPI_Comm comm /* in */,
int* comm._sz_p /* out */);
Int MPI_Com_ rank(
MPI_Comm comm /* in */,
int* my_rank_p /* out */);
For both functions, the first
argument is a communicator and has the special type defined by MPI for
communicators, MPI_Comm. MPI_Comm size returns in its second argument the number of
processes in the communicator, and MPI_Comm rank returns in its second argument the calling
process’ rank in the communicator. We’ll often use the variable comm sz for the number of processes in MPI_COMM_WORLD, and the variable my rank for the process rank.
1.5 SPMD programs
Notice that we compiled a
single program—we didn’t compile a different program for each process—and we
did this in spite of the fact that process 0 is doing something fundamentally
different from the other processes: it’s receiving a series of messages and
printing them, while each of the other processes is creating and sending a
mes-sage. This is quite common in parallel programming. In fact, most MPI programs are written in
this way. That is, a single program is written so that different processes
carry out different actions, and this is achieved by simply having the
processes branch on the basis of their process rank. Recall that this approach
to parallel programming is called single program, multiple data, or SPMD. The if
else statement in Lines 16 through 28 makes our program SPMD.
Also notice that our program
will, in principle, run with any number of processes. We saw a little while ago
that it can be run with one process or four processes, but if our system has
sufficient resources, we could also run it with 1000 or even 100,000 processes.
Although MPI doesn’t require that programs have this property, it’s almost
always the case that we try to write programs that will run with any number of
pro-cesses, because we usually don’t know in advance the exact resources
available to us. For example, we might have a 20-core system available today,
but tomorrow we might have access to a 500-core system.
1.6 Communication
In Lines 17 and 18, each
process, other than process 0, creates a message it will send to process 0.
(The function sprintf is very similar to printf, except that instead of writing to stdout, it writes to a string.) Lines 19–20 actually
send the message to process 0. Process 0, on the other hand, simply prints its
message using printf, and
then uses a for loop to receive and print the messages sent by
pro-cesses 1, 2, ...., comm sz 1. Lines 24–25 receive the message sent by
process q, for q D 1, 2, ...., comm sz 1.
1.7 MPI_Send
The sends executed by
processes 1, 2, ...., comm sz 1 are fairly complex, so let’s take a closer
look at them. Each of the sends is carried out by a call to MPI_Send, whose syntax is
int MPI_Send(
void msg_buf_p / * in */,
int msg_size / * in */,
MPI_Datatype msg_type /
* in */,
int dest / * in */,
int tag / * in */,
MPI_Comm communicator /* in */);
The first three arguments, msg_buf_p, msg size, and msg type, determine the con-tents of the message. The
remaining arguments, dest, tag, and communicator, determine the destination of the message.
The first argument, msg_buf_p, is a pointer to the block of memory
containing the contents of the message. In our program, this is just the string
containing the message, greeting. (Remember that in C an array, such as a string, is a pointer.)
The second and third arguments, msg_size and msg_type, determine the amount of data to be sent. In
our program, the msg size argument is the number of characters in the
message plus one character for the ‘\0’ character that terminates C strings. The msg type argument is MPI_CHAR. These two arguments together tell the system
that the message contains strlen(greeting)+1 chars.
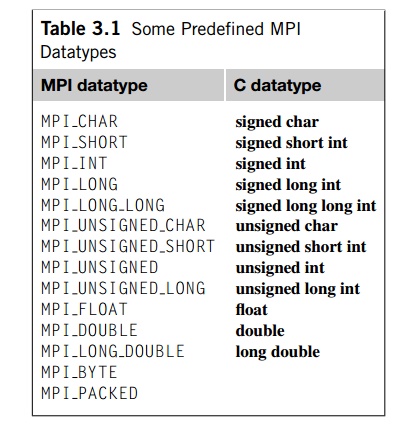
Since C types (int, char, and so on.) can’t be passed as arguments to functions, MPI
defines a special type, MPI_Datatype, that is used for the msg type argument. MPI also defines a number of constant values for this
type. The ones we’ll use (and a few others) are listed in Table 3.1.
Notice that the size of the string greeting is not the same as the size of the message specified by the
arguments msg_size and msg_type. For example, when we run the program with
four processes, the length of each of the messages is 31 characters,
while we’ve allocated storage for 100
characters in greetings. Of course, the size of the message sent should be less than or
equal to the amount of storage in the buffer—in our case the string greeting.
The fourth argument, dest, specifies the rank of the process that should
receive the message. The fifth argument, tag, is a nonnegative int. It can be used to dis-tinguish messages that are
otherwise identical. For example, suppose process 1 is sending floats to
process 0. Some of the floats should be printed, while others should be used in
a computation. Then the first four arguments to MPI_Send provide no information regarding which floats
should be printed and which should be used in a computation. So process 1 can
use, say, a tag of 0 for the messages that should be printed and a tag of 1 for
the messages that should be used in a computation.
The final argument to MPI_Send is a communicator. All MPI functions that involve communication
have a communicator argument. One of the most important purposes of
communicators is to specify communication universes; recall that a
communica-tor is a collection of processes that can send messages to each
other. Conversely, a message sent by a process using one communicator cannot be
received by a process that’s using a different communicator. Since MPI provides
functions for creating new communicators, this feature can be used in complex
programs to insure that messages aren’t “accidentally received” in the wrong place.
An example will clarify this. Suppose we’re
studying global climate change, and we’ve been lucky enough to find two
libraries of functions, one for modeling the Earth’s atmosphere and one for
modeling the Earth’s oceans. Of course, both libraries use MPI. These models
were built independently, so they don’t communicate with each other, but they
do communicate internally. It’s our job to write the interface code. One
problem we need to solve is to insure that the messages sent by one library
won’t be accidentally received by the other. We might be able to work out some
scheme with tags: the atmosphere library gets tags 0, 1, ...., n - 1 and the ocean library gets tags n, n + 1, ...., n + m. Then each library can use the given range to figure out which tag
it should use for which message. However, a much simpler solution is provided
by communicators: we simply pass one communicator to the atmosphere library
functions and a different communicator to the ocean library functions.
1.8 MPI_Recv
The first six arguments to MPI_Recv correspond to the first six
arguments of
MPI_Send:
int MPI_Recv(
void* msg buf p /* out */,
int buf size /* in */,
MPI_Datatype buf type /* in */,
int source /* in */,
int tag /* in */,
MPI_Comm communicator /* in */,
MPI_Status status p /* out */);
Thus, the first three arguments specify the memory available for receiving the message: points to the block of memory, determines the msg buf p message: points to the block of memory, determines the buf size number of objects that can be stored in the block, and buf_type indicates the type of the objects. The next three arguments identify the message. The source argument specifies the process from which the message should be received. The tag argument should match the tag argument of the message being sent, and the communicator argument must match the communicator used by the sending pro-cess. We’ll talk about the status p argument shortly. In many cases it won’t be used by the calling function, and, as in our “greetings” program, the special MPI_constant MPI_STATUS_IGNORE can be passed.
1.9 Message matching
Suppose process q calls MPI_Send with
MPI_Send(send_buf_p, send_buf_sz, send_type,
dest, send_tag, send_comm);
Also suppose that process r calls MPI_Recv with
MPI_Recv(recv_buf_p, recv_buf_sz, recv_type,
src, recv_tag, recv_comm, &status);
Then the message sent by q with the above call
to MPI_Send can be received by r with the call to MPI_Recv if
.. recv_comm = send_comm,
. recv_tag = send_tag,
. dest = r, and
src = q.
These conditions aren’t quite enough for the
message to be successfully received, however. The parameters specified by the first three
pairs of arguments, send_buf_p/recv_buf_p, send_buf_sz/recv_buf_sz, and send
type/recv type, must specify compatible buffers. For detailed rules, see the MPI-1
specification [39]. Most of the time, the following rule will suffice:
If
recv_type = send_type and recv_buf_sz>= send_buf_sz, then the message sent
by q can be successfully received by r.
Of course, it can happen that one process is
receiving messages from multiple processes, and the receiving process doesn’t know the order in which the other
pro-cesses will send the messages. For example, suppose, for example, process 0
is doling out work to processes 1, 2, ...., comm sz-1, and processes 1, 2, ...., comm sz-1, send their results back to process 0 when they finish the work.
If the work assigned to each process takes an unpredictable amount of time,
then 0 has no way of knowing the order in which the processes will finish. If
process 0 simply receives the results in process rank order—first the results
from process 1, then the results from process 2, and so on—and if, say, process
comm sz-1 finishes first, it could happen that pro-cess comm sz-1 could sit and wait for the other processes
to finish. In order to avoid this problem, MPI provides a special constant MPI_ANY_SOURCE that can be passed to MPI_Recv. Then, if process 0 executes the following
code, it can receive the results in the order in which the processes finish:
for (i = 1; i < comm._sz; i++) {
MPI_Recv(result, result_sz, result_type,
MPI_ANY_SOURCE, result_tag, comm, MPI_STATUS_IGNORE);
Process_result(result);
}
Similarly, it’s possible that one process can
be receiving multiple messages with different tags from another process, and the receiving process
doesn’t know the order in which the messages will be sent. For this
circumstance, MPI provides the special constant MPI_ANY_TAG that can be passed to the tag argument of MPI_Recv.
A couple of points should be
stressed in connection with these “wildcard” arguments:
Only a receiver can use a wildcard argument. Senders must specify a
process rank and a nonnegative tag. Thus, MPI uses a “push” communication
mechanism rather than a “pull” mechanism.
There is no wildcard for communicator arguments; both senders and
receivers must always specify communicators.
10 The status p argument
If you think about these
rules for a minute, you’ll notice that a receiver can receive a message without
knowing
the amount of data in the message,
the sender of the message, or
the tag of the message.
So how can the receiver find
out these values? Recall that the last argument to MPI_Recv has type MPI_Status*.
The MPI type MPI_Status is a struct with at least the three members MPI_SOURCE,
MPI_TAG, and MPI_ERROR. Suppose our program contains the definition
MPI_Status_status;
Then, after a call to MPI_Recv
in which &status is passed as the last argument, we can determine the
sender and tag by examining the two members
status.MPI_SOURCE
status.MPI_TAG
The amount of data that’s
been received isn’t stored in a field that’s directly accessible to the
application program. However, it can be retrieved with a call to MPI_Get_count.
For example, suppose that in our call to MPI_Recv, the type of the receive
buffer is recv_type and, once again, we passed in &status. Then the call
MPI_Get_count(&status,
recv_type, &count)
will return the number of
elements received in the count argument. In general, the syntax of MPI_Get_count
is
int MPI_Get_count(
MPI_Status* status_p /*
in */,
MPI_Datatype type /* in */,
Int* count_p /* out */);
Note that the count isn’t directly accessible as a member of the MPI_Status variable simply because it depends on the type of the received data, and, conse-quently, determining it would probably require a calculation (e.g. (number of bytes received)=(bytes per object)). If this information isn’t needed, we shouldn’t waste a calculation determining it.
1.11 Semantics of MPI_Send and MPI_Recv
What exactly happens when we send a message from one process to another? Many of the details depend on the particular system, but we can make a few generaliza-tions. The sending process will assemble the message. For example, it will add the “envelope” information to the actual data being transmitted—the destination process rank, the sending process rank, the tag, the communicator, and some information on the size of the message. Once the message has been assembled, recall from Chapter 2 that there are essentially two possibilities: the sending process can buffer the message or it can block. If it buffers the message, the MPI system will place the message (data and envelope) into its own internal storage, and the call to MPI_Send will return.
Alternatively, if the system blocks, it will
wait until it can begin transmitting the message, and the call to MPI_Send may not return immediately. Thus, if we use MPI_Send, when the function returns, we don’t actually know whether the
message has been transmitted. We only know that the storage we used for the
message, the send buffer, is available for reuse by our program. If we need to
know that the message has been transmitted, or if we need for our call to MPI_Send to return immediately—regardless of whether the message has been
sent—MPI provides alter-native functions for sending. We’ll learn about one of
these alternative functions later.
The exact behavior of MPI_Send is determined by the MPI implementation. How-ever, typical
implementations have a default “cutoff” message size. If the size of a message
is less than the cutoff, it will be buffered. If the size of the message is
greater than the cutoff, MPI_Send will block.
Unlike MPI_Send, MPI_Recv always blocks until a matching message has
been received. Thus, when a call to MPI_Recv returns, we know that there is a message
stored in the receive buffer (unless there’s been an error). There is an
alternate method for receiving a message, in which the system checks whether a
matching message is available and returns, regardless of whether there is one.
(For more details on the use of nonblocking communication, see Exercise 6.22.)
MPI requires that messages be nonovertaking. This means that if process q sends two messages to process r, then the first message sent by q must be available to r before the second message. However, there is no
restriction on the arrival of mes-sages sent from different processes. That is,
if q and t both send messages to r, then even if q sends its message before t sends its message, there is no require-ment that q’s message become available to r before t’s message. This is essentially because MPI can’t impose
performance on a network. For example, if q happens to be running on a machine on Mars, while r and t are both running on the same machine in San Francisco, and if q sends its message a nanosecond before t sends its message, it would be extremely
unreasonable to require that q’s message arrive before t’s.
1.12 Some potential pitfalls
Note that the semantics of MPI_Recv suggests a potential pitfall in MPI
programming: If a process tries to receive a message and there’s no matching
send, then the process will block forever. That is, the process will hang. When we design our
programs, we therefore need to be sure that every receive has a matching send.
Perhaps even more important, we need to be very careful when we’re coding that
there are no inadvertent mistakes in our calls to MPI_Send and MPI_Recv. For example, if the tags don’t match, or if
the rank of the destination process is the same as the rank of the source
process, the receive won’t match the send, and either a process will hang, or,
perhaps worse, the receive may match another send.
Similarly, if a call to MPI_Send
blocks and there’s no matching receive, then the sending process can hang. If,
on the other hand, a call to MPI_Send is buffered and there’s no matching
receive, then the message will be lost.
Related Topics