Chapter: XML and Web Services : Building XML-Based Applications : XML and Content Management
The Role of Metadata (RDF and PRISM) in Web Content Management
The Role of Metadata (RDF and PRISM) in Web Content Management
A problem that everyone experiences, whether on the job or in one’s
personal life, is information overload. Let’s just consider your daily mail. If
you are like me, each day that you go to the mailbox, you cannot believe the
amount of mail you receive. Usually I pick up the mail after a hard day at
work. I don’t have time to deal with each item that I have received right at
that time. So what do I do? I carefully place the mail on top of my dining room
table. By the weekend, I am suffering from information overload. There are
bills to pay, important items such as insurance policies to file, magazines
that I should read, and lots of junk mail to throw away. Fortunately, with just
a few file folders, I can divide my mail into these four categories and quickly
be able to find what I want.
Now imagine the problems facing those whose job it is to create content.
It might be a magazine publisher or it might be a bank, an insurance company,
or an electronics manu-facturer. Very quickly these organizations discover the
problems that information over-load can bring. So don’t they do what I do with
my mail? Simply divide the content into neat categories and store it?
Well, the answer is, of course, that most content is far more complex
than my mail. There may be several different schemes that people could use to
find the content they need. Each piece of content has characteristics that are
critical to its use and reuse. If I am storing images, for example, I need to
know not only the subject matter but also the format and whether I have rights
to use the images.
To effectively manage content, I need more than just a filing system. I
need a way to specify critical information about each item of content as well.
What I need is metadata!
What Is Metadata?
One of the formal definitions of metadata is data about data. In this context, we can con-sider metadata to be data about content. Consider an image.
Data about the image is what will enable me to discover and use the image. This
data—the subject matter, the photographer, the format, and the rights—is an
example of metadata. Metadata gives us a mechanism to associate lookup
information (images about the Internet) with the content we want to discover.
Another place where metadata will be most useful is the Web. The Web is
much like a giant library. Instead of being made up of books, it is made up of
resources such as e-mail messages, images, and Web pages. Today, if you know
the URL of what you want to find, you can find it. However, if we had metadata
about Web resources (much like the metadata in a card catalog in a library) we
could navigate the Web a lot more easily.
About the Resource Description Framework
The effective use of metadata among applications on the Web requires
common conven-tions about the semantics, syntax, and structure of metadata. In
other words, it requires a metadata specification standard. Such a standard
must also allow for individual commu-nities of use, to define their own
semantics, or meaning, of metadata to
address their par-ticular needs.
It’s only natural that such a metadata specification was developed under
the auspices of the World Wide Web Consortium. This specification is known as
the Resource Description Framework (RDF), which is the result of a number of
metadata commu-nities bringing together their needs to provide a robust and
flexible architecture for supporting metadata on the Web. RDF is very much a
collaborative work. It became a W3C Recommendation in February 1999. An RDF
Schema Model became a W3C Recommendation in March of 2000. RDF relies on XML
syntax as well as the W3C syntax for URI.
The Resource Description Framework, as its name implies, is a framework
for describing and interchanging metadata. In particular, RDF focuses on Web
resources. It should come as no surprise that the world’s librarians had a
great deal of input into the develop-ment of RDF.
RDF Basics
RDF was designed based on the following basic concepts:
Resource. All the world’s Web content is
a resource, and a resource must have a URI.
Therefore, all the world’s Web pages, as well as individual elements within
these Web pages, are resources. A resource is the W3C home page,
http://www.w3.org/, for
example.
Property type. Resources have names and can be
used as properties (for example, subject
or author). Typically, all we really care about is the name of the property
type, but a property type needs to be a resource so that it can have its own
proper-ties.
Property. A property is the resource along with its property type and a value
for that property. For the resource http://www.idealliance.org/xmlfiles/ issue32/book.htm, the property type is subject, and the value of the property type
is XML Book Review.
Description. A collection of properties that
describe the same resource as a description.
Taken together, the properties make up a metadata set that describes the
resource.
RDF provides a model for attaching metadata to Web resources. It also
provides a syntax so that it can be exchanged and used. That’s really all RDF
provides and all RDF is. It is simply a framework for defining metadata.
An RDF property can be represented as a directed labeled graph. Let’s
refer to the prop-erty “The subject of http://www.idealliance.org/xmlfiles/issue32/book.htm is XML Book Review.” In Figure 13.3, you can see how resources are
identified as nodes, property types are defined as directed label arcs, and
string values are quoted.

RDF does not come with any predefined property types or value sets of
its own. The metadata properties, property types, and values are left to the
user to define according to the function metadata is to serve. These sets of
RDF metadata are called RDF vocabular-ies.
An example of an RDF vocabulary is Dublin Core. This is an initiative of the
library community to develop a simple
resource description for discovery.

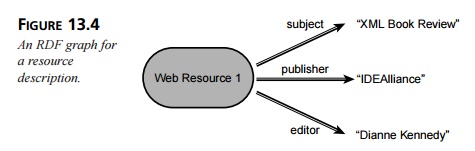
RDF is expressed in XML. Listing 13.2 represents “The subject of http://www.ideal-liance.org/xmlfiles/issue32/book.htm is XML Book Review. The editor of
http://www.idealliance.org/xmlfiles/issue32/book.htm is Dianne Kennedy.” In this
example, we use XML namespaces to indicate the RDF namespace. We use the
IDEAlliance namespace to identify the XML Files tags unambiguously. You can see
the graph for this listing in Figure 13.4.
LISTING 13.2 Example of RDF Syntax
<?xml:namespace ns = “http://www.w3.org/RDF/RDF/” prefix =”RDF” ?>
<?xml:namespace ns = “http://idealliance.org/XMLFiles/” prefix = “XMLFiles”
?> <RDF:RDF>
<RDF:Description RDF:HREF =
“http://uri-of-Document-1”> <XMLFiles:subject>XML Book
Review</XMLFiles:subject> <XMLFiles:publisher>IDEAlliance</
XMLFiles:publisher > <XMLFiles:editor>Dianne
Kennedy</XMLFiles:editor>
</RDF:Description>
</RDF:RDF>
Why RDF and Not XML for Metadata?
XML can be used to model almost anything. It seems
that we could just invent XML tags to code metadata. So why isn’t XML the W3C
recommended vehicle for metadata?
It turns out that the issue with using XML to
represent metadata has to do with scalabil-ity. Two problems exist when we try
to represent metadata directly with XML according to RDF specialists:
Element order in an XML document is meaningful. In a metadata
environment, where all metadata properties are equal, this doesn’t make much
sense. Who cares whether the subject or the editor of an XML Files article is
listed first or second. And why take on the overhead of maintaining the correct
order (XML modeling) when it is not meaningful. This can be expensive in
overhead and difficult to implement.
XML enables us to embed elements and entities within a description field
(mixed content). When you represent these mixed-content structures in computer
memory, you get data structures that mix hierarchical XML trees, graphs, and
character strings. These become difficult to handle when billions of metadata
fields are applied to Web resources.
Interestingly enough, even though XML by itself does not provide
metadata functionality that we require for the next generation of the Web, XML
remains a necessary ingredient for RDF interchange.
About XMP
XMP, Adobe’s eXtensible Metadata
Platform, is a framework for adding metadata to application files,
databases, and content-management systems. Adobe announced XMP as a “standard”
in September of 2001. XMP is built on W3C standards but is not, itself, a W3C
standard. It is, however, an Adobe standard. As such, XMP will be implemented across
the Adobe family of products and will be intimately integrated into the PDF
out-put of Adobe publishing tools.
According to Adobe, the lack of standardized metadata has been a problem
for the evolu-tion of the Web. A standardized metadata framework is required
for machines to be able to read and understand metadata associated with
content. Only when this happens can we move toward automated content handling
on the Web.
XMP is Adobe’s attempt to remedy the lack of a standardized metadata
framework. XMP relies on RDF to express metadata in XML. Within XMP, Adobe had
defined its own starter set of metadata tags called the XMP Schemas. This XMP set of metadata tags is not a standard set of
metadata tags; it is an Adobe set of metadata tags. Adobe is quick to point out
that the value of XMP is not in this XMP Schema but the fact that XMP sets up a
framework for applying metadata to content. According to Adobe, XMP can carry
any metadata vocabulary. For example, XMP can serve as a platform for PRISM
metadata in the publishing world. You can learn more about XMP at http://www.adobe.com/prod-ucts/xmp/main.html.
About PRISM
PRISM is the Publishing
Requirements for Industry Standard Metadata. It is an extensi-ble XML
metadata vocabulary designed to facilitate the multipurposing, aggregating, and
syndicating, personalizing, and postprocessing of any kind of content. PRISM is
a stan-dardized metadata vocabulary developed by publishers to describe all
kinds of published content. Examples of PRISM content types include
advertisements, articles, books, cata-logs, e-books, home pages, journals,
magazines, news, interviews, and even cartoons.
Who Developed PRISM?
PRISM is hosted by IDEAlliance and sponsored by a group of companies
such as Adobe Systems, Vignette, Time Inc., McGraw-Hill, CMP, Artesia
Technologies, Getty Images, Interwoven, Kinecta, Netscape, and Quark. These
companies all have a shared business interest in creating and using a common
metadata standard as a basic part of their content infrastructures. The group
consists of software developers as well as content suppliers and consumers who
are involved in content creation, consumption, manage-ment, aggregation, and
distribution, whether commercially or within intranet and extranet frameworks.
PRISM and Other Standards
When PRISM was developed, one of the goals was to build on existing
metadata frame-works and vocabularies. It is natural that PRISM recommends the
use of both XML and RDF as well as the Dublin Core metadata specification. It
also makes extensive use of XML namespaces as a mechanism to include these
related metadata standards. You can learn more about PRISM at http://www.prismstandard.org/.
PRISM metadata is expressed as an XML document, which begins with the
standard XML declaration:
<?xml version=”1.0”?>
A character encoding may be given if necessary. Because PRISM is an RDF
vocabulary, the next element in a PRISM document is just like the first
statement of an RDF docu-ment. The XML namespaces that you are using must be
indicated as an attribute of RDF. This is done by adding attributes beginning
with xmlns:. Note
that we define both the RDF namespace and the namespace for Dublin Core because
PRISM uses elements from each. This is shown in Listing 13.3.
LISTING 13.3 PRISM Uses XML, RDF, XML
Namespaces and Dublin Core as a Basis
<?xml version=”1.0” encoding=”UTF-8”?>
<rdf:RDF
xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:dc=”http://purl.org/dc/elements/1.1/”>
PRISM Elements
The goal of PRISM is to provide a framework for the interchange and
preservation of content and metadata. It therefore is made up of a collection
of elements to describe content and a set of controlled vocabularies listing
values for the elements. The working group has focused on defining metadata for
the following purposes:
To provide general-purpose
descriptions of the content resource
To specify the relationship of
one resource to another
To indicate rights and
permissions
To enable inline metadata within
the resource itself
PRISM elements can be categorized by functional group. As you know, some
PRISM elements have been specifically defined within the PRISM specifications.
Others have been borrowed from Dublin Core metadata, see http://dublincore.org/. PRISM ele-ments can be
categorized as follows:
General purpose. These elements, for the most
part, have been borrowed from Dublin
Core. They include dc:identifier, dc:author, dc:contributor,
dc:title,
dc:description, and dc:format.
• Provenance.
These elements include dc:publisher, prism:distributor, and dc:source.
• Timestamps.
A number of timestamps have been developed as PRISM elements. These include prism:creationtime, prism:pubicationtime, and prism:expire-time.
Subject descriptions. These elements describe the
subject of a resource. These include dc:subject, dc:description, prism:person, and prism:organization.
Resource relationships. PRISM
has added numerous metadata fields that enable us to express relationships between content resources. These include prism:isPartOf,
prism:isBasedOn, and prism:isReferencedBy.
Rights information. PRISM uses Dublin Core rights
and has developed its own set of
rights metadata. This includes prism:copyright, prism:rightsAgent, and
prism:expirationTime.
In addition to the PRISM namespace metadata elements, PRISM has defined
some spe-cialized elements that are in specialized namespaces. These include
the following:
• prl:. The prl: namespace stands for PRISM Rights Language. This set of meta-data elements is specific to a portion of the PRISM
specification known as the rights
language. Some examples of these tags are prl:industry and prl:usage.
• pim:. The pim: namespace stands for PRISM Inline Markup. These elements were specifically
designed to enable inline markup of organizations, locations, product names,
and personal names. Examples of these elements are pim:organization, pim:location, and pim:person.
• pcv:. The pcv: namespace stands for PRISM
Controlled Vocabulary. This name-space provides a
mechanism for describing and conveying all or a portion of a controlled
vocabulary or authority file. This may be used to define entire new
tax-onomies. Examples of these metadata elements include pcv:broaderTerm, pcv:narrowerTerm, and pcv:relatedTerm.
Using PRISM
PRISM descriptions are compliant with RDF, and they begin with the rdf:RDF element. PRISM requires that
resources have unique identifiers. In Listing 13.4, a photograph is identified
by a URI in the rdf:about attribute of the rdf:Description element. The dc:identifier element can be used for other identifiers, such as International
Standard Book
Numbers (ISBNs) or system-specific identifiers. In this example, the dc:identi-fier element contains an asset ID for Cameramaster’s asset management system. In this simple example of PRISM, only the
basic Dublin Core elements dc:description, dc:title, dc:creator, dc:contributor, and dc:format are used.
LISTING 13.4 Simple PRISM Description
<?xml version=”1.0” encoding=”UTF-8”?>
<rdf:RDF xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:dc=”http://purl.org/dc/elements/1.1/”>
<rdf:Description
rdf:about=”http://cameramasters.com/2001/08/IndianaDunes.jpg”>
<dc:identifier
rdf:resource=”http://cameramasters.com/content/042249X”/>
<dc:description>Photograph taken at 2:00 PM on
➥ the beach at Indiana Dunes State Park </dc:description>
<dc:title>Indiana Beach in Summer</dc:title>
<dc:creator>Darold Vredberg</dc:creator>
<dc:contributor>Michelle Leigh, lighting</dc:contributor>
<dc:format>image/tiff</dc:format>
</rdf:Description>
</rdf:RDF>
A PRISM description can either be simple or quite complex. Like
determining the level of XML tagging in content, one must ultimately consider
the business application of PRISM to decide how much metadata should be
attached to any information asset. If, for example, you have rights to all the
content you want to track and manage, then including complex rights metadata in
your PRISM description would be inappropriate. If, however, you routinely make
use of content that has varying rights and permissions, specifying this data in
your PRISM description is critical.
Listing 13.5 shows a more complex use of PRISM metadata. Here, we have
expanded beyond the Dublin Core metadata set and are using PRISM metadata
elements to indicate that the photo is part of an article as well as to
indicate the rights ownership and management.
LISTING 13.5 Simple PRISM Description
<?xml version=”1.0” encoding=”UTF-8”?>
<rdf:RDF xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:dc=”http://purl.org/dc/elements/1.1/”>
<rdf:Description
rdf:about=”http://cameramasters.com/2001/08/IndianaDunes.jpg”
➥ xmlns:pcv=”http://prismstandard.org/namespaces/pcv/1.0/”>
<dc:identifier
rdf:resource=”http://cameramasters.com/content/042249X”/>
<dc:description>Photograph taken at 2:00 PM
➥ on the beach at Indiana Dunes
State Park
</dc:description>
<prism:isPartOf rdf:resource=
➥
”http://IndianaHome.com/2000/08/IndianaArticle.xml”/>
<dc:title>Indiana Beach in
Summer</dc:title>
<dc:creator>Darold
Vredberg</dc:creator>
<dc:contributor>Michelle
Leigh, lighting</dc:contributor>
<dc:format>image/tiff</dc:format>
<prism:copyright>Copyright 2001, Indiana Home Publications. All
rights reserved.</prism:copyright>
<prism:rightsAgent>PhotoRights,
Munster, IN</prism:rightsAgent>
</rdf:Description>
</rdf:RDF>
Related Topics