Chapter: Fundamentals of Database Systems : Advanced Database Models, Systems, and Applications : Introduction to Information Retrieval and Web Search
Text Preprocessing
Text Preprocessing
In this section we review the commonly used text preprocessing
techniques that are part of the text processing task in Figure 27.1.
1. Stopword Removal
Stopwords are very commonly used words in a language that play a major role in the formation of a sentence but which
seldom contribute to the meaning of that sentence. Words that are expected to
occur in 80 percent or more of the documents in a collection are typically
referred to as stopwords, and they
are rendered potentially useless. Because of the commonness and function of
these words, they do not contribute much to the relevance of a document for a
query search. Examples include words such as the, of, to, a,
and, in, said, for, that,
was, on, he, is, with,
at, by, and it. These words
are presented here with decreasing frequency of occurrence from a large corpus
of documents called AP89. The fist six of these words
account for 20 percent of all words in the listing, and the most frequent 50
words account for 40 percent of all text.
Removal of stopwords from a document must be performed before indexing.
Articles, prepositions, conjunctions, and some pronouns are generally
classified as stopwords. Queries must also be preprocessed for stopword removal
before the actual retrieval process. Removal of stopwords results in
elimination of possible spurious indexes, thereby reducing the size of an index
structure by about 40 percent or more. However, doing so could impact the
recall if the stopword is an integral part of a query (for example, a search
for the phrase ‘To be or not to be,’ where removal of stopwords makes the query
inappropriate, as all the words in the phrase are stopwords). Many search
engines do not employ query stopword removal for this reason.
2. Stemming
A stem of a word is defined
as the word obtained after trimming the suffix and prefix of an original word.
For example, ‘comput’ is the stem word for computer,
computing, and computation.
These suffixes and prefixes are very common in the English language for supporting the notion of verbs, tenses, and
plural forms. Stemming reduces the
different forms of the word formed by inflection (due to plurals or tenses)
and derivation to a common stem.
A stemming algorithm can be applied to reduce any word to its stem. In
English, the most famous stemming algorithm is Martin Porter’s stemming
algorithm. The Porter stemmer is a simplified version of Lovin’s technique that uses a reduced set of
about 60 rules (from 260 suffix patterns in Lovin’s technique) and organizes
them into sets; conflicts within one subset of rules are resolved before going
on to the next. Using stemming for preprocessing data results in a decrease in
the size of the indexing structure and an increase in recall, possibly at the
cost of precision.
3. Utilizing a
Thesaurus
A thesaurus comprises a
precompiled list of important concepts and the main word that describes each
concept for a particular domain of knowledge. For each concept in this list, a
set of synonyms and related words is also compiled. Thus, a synonym can be converted
to its matching concept during preprocessing. This preprocessing step assists
in providing a standard vocabulary for indexing and searching. Usage of a
thesaurus, also known as a collection of
synonyms, has a substantial impact on the recall of information systems.
This process can be complicated because many words have different meanings in
different contexts.
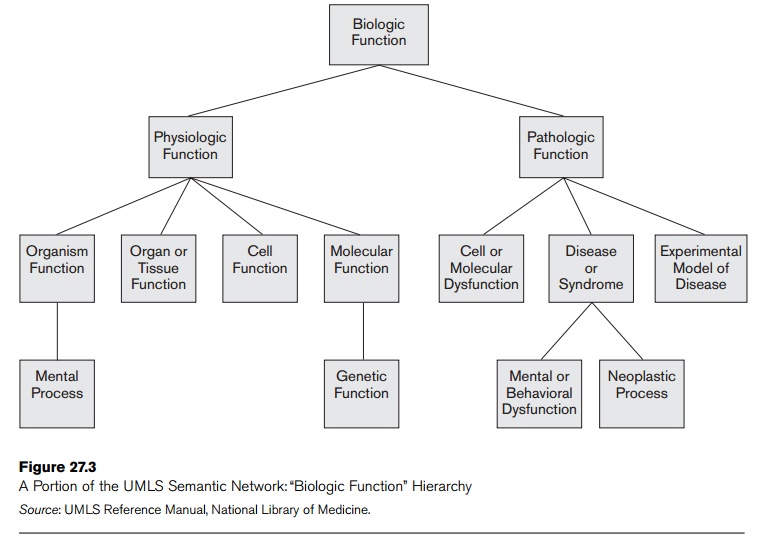
UMLS is a large biomedical thesaurus of millions of concepts (called the Metathesaurus)
and a semantic network of meta concepts and relationships that organize the Metathesaurus (see Figure
27.3). The concepts are assigned labels from the semantic network. This
thesaurus of concepts contains synonyms of medical terms, hierarchies of
broader and narrower terms, and other relationships among words and concepts
that make it a very extensive resource for information retrieval of documents
in the medical domain. Figure 27.3 illustrates part of the UMLS Semantic
Network.
WordNet is a manually constructed thesaurus that groups words into strict
synonym sets called synsets. These
synsets are divided into noun, verb, adjective, and adverb categories. Within
each category, these synsets are linked together by appropriate relationships
such as class/subclass or “is-a” relationships for nouns.
WordNet is based on the idea of using a controlled vocabulary for
indexing, thereby eliminating redundancies. It is also useful in providing
assistance to users with locating terms for proper query formulation.
4. Other Preprocessing Steps: Digits, Hyphens, Punctuation Marks, Cases
Digits, dates, phone numbers, e-mail addresses, URLs, and other standard
types of text may or may not be removed during preprocessing. Web search
engines, however, index them in order to to use this type of information in the
document metadata to improve precision and recall (see Section 27.6 for
detailed definitions of precision and
recall).
Hyphens and punctuation marks may be handled in different ways. Either
the entire phrase with the hyphens/punctuation marks may be used, or they may
be eliminated. In some systems, the character representing the
hyphen/punctuation mark may be removed, or may be replaced with a space.
Different information retrieval systems follow different rules of processing.
Handling hyphens automatically can be complex: it can either be done as a
classification problem, or more commonly by some heuristic rules.
Most information retrieval systems perform case-insensitive search,
converting all the letters of the text to uppercase or lowercase. It is also
worth noting that many of these text preprocessing steps are language specific,
such as involving accents and diacritics and the idiosyncrasies that are
associated with a particular language.
5. Information
Extraction
Related Topics