Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Scaling with Multicore Processors
Operating System Constraints to Scaling
Operating
System Constraints to Scaling
Most limitations to scaling are caused by either limitations of the
hardware or inefficien-cies in the implementation of the actual application.
However, as the number of cores increases, it is not uncommon to uncover
problems in the operating system or the libraries provided with it.
Oversubscription is when there are too many active threads on a system. This is not a
con-straint on the absolute number of threads on the system, only on the number
of active threads. If there are continuously more threads requesting CPU time
than there are vir-tual CPUs, then the system may be considered to be
oversubscribed.
Although quiescent threads take resources such as
memory, they do not tend to con-sume much processor time, so a system can
sustain a high count of idle threads. A system can sustain more active threads
than there are virtual CPUs, but each active thread will only get a share of
the available CPU resources. On a system where there are twice as many active
software threads as there are hardware threads to sustain them, each active
software thread will end up with 50% of the time of one of the virtual CPUs.
Having multiple threads share the same virtual CPU
will typically lead to a greater than linear reduction in performance because
of a number of factors such as overheads due to the cost of switching context
between the active threads, the eviction of useful data from the cache, and the
costs associated with the migration of threads between vir-tual CPUs. It is
also worth considering that each thread requires some memory foot-print, and a
proliferation of threads is one way of causing a shortage of memory.
A key point to observe is that having more active
threads than there are virtual CPUs can only decrease the rate at which each
thread completes work. There is one situation where there is likely to be a
benefit from having more threads than virtual CPUs. Threads that are sleeping
or blocked waiting for a resource do not consume CPU and should not impact the
performance of the active threads. An example of this is where there are many
threads waiting for disk or network activity to complete.
It may be useful to have many threads waiting for
the results of network requests or to have threads waiting for disk I/O to
complete. In fact, this is a critical way of improv-ing the performance of
applications that have significant I/O—the main thread can con-tinue
computation, while a child thread waits for the completion of an I/O request.
The code in Listing 9.29 can be used to demonstrate how the performance
of a sin-gle thread can suffer in the presence of other active threads. The
code measures how long it takes the main thread to complete its work. However,
before the main thread starts the timed section, it spawns multiple child
threads that spin on a lock until the main thread completes its work.
Listing 9.29 Code to Demonstrate the Costs Associated with Oversubscription
#include <stdio.h> #include <stdlib.h>
#include <pthread.h> #include <sys/time.h>
double now()
{
struct timeval time; gettimeofday( &time, 0 );
return (double)time.tv_sec + (double)time.tv_usec / 1000000.0;
}
#define COUNT 100000000 volatile int stop = 0;
void *spin( void *id )
{
while( !stop ) {}
}
int main( int argc, char* argv[] )
{
pthread_t threads[256]; int nthreads = 1;
if ( argc > 1 ) { nthreads = atoi( argv[1] ); } nthreads—-;
for( int i=0; i<nthreads; i++ )
{
pthread_create( &threads[i], 0, spin, (void*)0 );
}
double start=now(); int total = 0;
for( int h=0; h<COUNT; h++ )
total += ( total << 2 ) ^ (
total | 33556 ); if ( total == 0 ) { printf( "total==0\n" ); } double
end=now();
printf( "Time %f s\n", ( end – start ) ); stop = 1;
for(
int i=0; i<nthreads; i++ )
{
pthread_join( threads[i], 0 );
}
return 0;
}
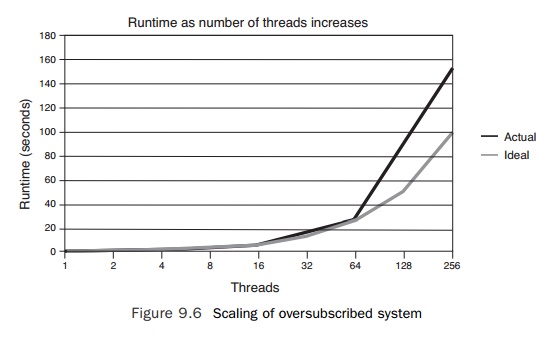
The chart in Figure 9.6 shows the runtime of the code on a system with
four virtual CPUs. The runtime of this code will depend on the number of
software threads per vir-tual CPU. If there are eight or more software threads,
then the runtime will be at least twice what it was for four or fewer threads.
There are two lines in the chart: a line indi-cating how long the code would
have taken to run if the runtime scaled linearly with the number of threads and
a line that shows the actual runtime of the code. After about 64 threads, it is
apparent that the oversubscription causes the runtime to be greater than might
be expected from linear scaling. In other words, after about 64 threads, the
per-formance of the system suffers because of oversubscription.
Using
Processor Binding to Improve Memory Locality
Thread migration is the situation where a thread starts running on one
virtual processor but ends up migrated to a different virtual processor. If the
new virtual processor shares the same core or if it shares cache with the
original virtual processor, then the cost of this migration is low. For a
multicore processor, the effect of thread migration tends to be minor since the
new location of the thread shares a close level of cache with the old location
of the thread. However, if the migration is from one physical chip to another,
the cost can be quite high.
One cost of thread migration is related to the fact that the data the
thread was using now resides in the cache of the old virtual processor. The
data will need to be fetched into the cache of the new process. It is important
to notice that this is likely to be a cache to cache transfer, rather like the
situation with false sharing. For some systems, fetching data from another
processor’s cache may be lower cost than fetching that data from memory.
However, on some systems the cost of fetching data from another cache may be
higher than fetching the data from memory. The typical reason for this is that
the data needs to be stored to memory before the new processor can fetch it.
However, there is an additional potential cost to
thread migration in a multiprocessor system. Modern operating systems typically
have some idea of the topology of the mem-ory subsystem. Hence, the operating
system can provide a thread with memory that has the lowest access latency.
Unfortunately, if a thread is migrated, it can be located on a different
processor with a much higher memory latency. This issue causes operating
sys-tems to attempt to keep threads, if not exactly where they were originally
running, at least within the group of virtual CPUs that share the same memory
access latencies.
This gives rise to the idea of locality groups,
groups of threads that share the same memory access latencies. If a thread is
moved within a locality group, there will be no change in memory latency costs;
the only migration cost is a small cost due to the thread moving to a
potentially cold cache.
Linux provides the tool numactl both to query the topology of the hardware and to allow the user to
specify the virtual processor where the application will be run. Listing 9.30 shows
the output from numactl that
indicates that the system has two nodes, phys-ical processors, and the amount
of memory associated with each node.
Listing 9.30 NUMA
Characteristics from Linux
$ numactl
--hardware available: 2 nodes (0-1) node 0 size: 2047 MB node 0 free: 88 MB
node 1 size: 1983 MB node 1 free: 136 MB
Solaris provides the tool lgrpinfo, which reports on the locality groups on the sys-tem. The output shown
in Listing 9.31 is from a system with two locality groups. Solaris provides the
separate tool pbind to
specify the binding of a process to virtual CPUs.
Listing 9.31 Locality
Group Information from Solaris
$ lgrpinfo
lgroup 0 (root):
Children: 1 2
CPUs: 0-3
Memory:
installed 18G, allocated 2.7G, free 15G
Lgroup resources: 1 2 (CPU); 1 2 (memory) Latency: 20
lgroup
1 (leaf):
Children: none, Parent: 0 CPUs: 0-1
Memory: installed 9.0G, allocated 1.0G, free 8.0G
Lgroup resources: 1 (CPU); 1 (memory)
Load: 0.139
Latency: 10 lgroup 2 (leaf):
Children: none, Parent: 0 CPUs: 2-3
Memory: installed 9.0G, allocated 1.7G, free 7.3G
Lgroup resources: 2 (CPU); 2 (memory)
Load: 0.0575
Latency:
10
In most instances, the developer should be able to
trust that the operating system per-forms the optimal placement of the threads
of the application. There are instances where this may not be optimal.
Memory is typically allocated with some policy that
attempts to place the memory used by the thread close to the processor where
the thread will be run. In many instances, this will be first-touch placement,
which locates memory close to the thread that first accesses the memory.
There is a subtle point to be made. The act of
allocating memory is often considered as the call that the application makes to
malloc().
Although this is the call that causes an address range of memory to be reserved
for the use of the process, physical memory is often only mapped into the
process when a thread touches the memory. First touch works well in situations
where the memory is used only by the thread that first touches it. If the
memory is initialized by one thread and then utilized by another, this is less
optimal, because the memory will be located close to the thread that
initialized it and not close to the thread that is using it.
To demonstrate the effect of memory placement on
performance, consider the code shown in Listing 9.32. This example estimates
memory latency by pointer chasing through memory. This setup allows us to
measure the impact of memory placement by allocating memory close to one chip
and then using it with a thread on a different chip. The routine setup() sets up a circular linked list of pointers that will be used in timing
memory latency. The code includes a call to the routine threadbind(), which will be defined shortly. This routine binds the particular
thread to virtual CPU 0.
The routine use() is
executed multiple times by the main thread. Each execution calls threadbind() to bind the thread to the desired virtual CPU. This enables the code to
measure the memory latency from the virtual CPU where the code is running to
the memory where the data is held. This routine uses two calls to the routine now() to calculate the elapsed time for the critical pointer chasing loop.
The routine now() will be
defined shortly. The end result of this activity is an estimate of the latency
of every memory access for the timed pointer chasing loop.
Listing 9.32 Code to Measure Memory Latency
#include <pthread.h> #include
<stdlib.h> #include <stdio.h> #include <sys/types.h> #include
<sys/time.h> #include <unistd.h>
#define SIZE 128*1024*1024 int** memory;
void setup()
{
int i, j; threadbind( 0 );
memory = (int**)calloc( sizeof(int*), SIZE+1 ); for( j=0; j<16; j++ )
{
for( i=16+j; i<=SIZE; i++)
{
memory[i] = (int*)&memory[ i-16 ];
}
memory[j] = (int*)&memory[ SIZE-16+j+1 ];
}
}
void *use( void* param )
{
if ( threadbind( (int)param ) == 0 )
{
int* next; int i;
double start = now(); next = memory[0];
for( i=0; i<SIZE; i++ )
{
next = (int*)*next;
}
if
( (int)next == 1 ) { printf( "a" ); } double end = now();
printf( "Time %14.2f ns Binding %i/s\n",
(end - start) * 1000000000.0 / ((double)SIZE),
(int)param ); } else { perror( "Error" ); }
}
int
main( int argc, char* argv[] )
{
pthread_t thread; int nthreads = 1; int i;
if ( argc > 1 ) { nthreads = atoi( argv[1] ); } setup();
for( i=0; i<nthreads; i++ )
{
pthread_create( &thread, 0, use, (void*)i ); pthread_join( thread, 0
);
}
return 0;
}
Before the code can be run, two critical routines
need to be provided. The easiest one to provide is the timing routine now(), which returns the current time in seconds as a double. The system
function call gettimeofday() provides
a very portable way on *NIX systems of getting seconds and microseconds since
the system was booted. Listing 9.33 shows the code for wrapping this as
returning a double.
Listing 9.33 Code
for Returning Current Time in Seconds
double
now()
{
struct timeval time; gettimeofday( &time, 0 );
return (double)time.tv_sec + (double)time.tv_usec / 1000000.0;
}
Controlling the location where the thread is run is
not portable. The code in Listing 9.34 shows how the Solaris call processor_bind() can be used to control the binding of a thread to a virtual processor.
The variables P_LWPID and P_MYID bind the calling thread to the particular virtual processor.
Listing 9.34 Controlling
Processor Binding on Solaris
#ifdef
__sun
#include
<sys/processor.h>
#include
<sys/procset.h>
int threadbind( int proc )
{
return processor_bind( P_LWPID, P_MYID, proc, 0 );
}
#endif
Linux provides the same functionality through the sched_setaffinity() call. This call sets the affinity of a thread so that it will run on
any of a group of virtual CPUs. The call requires a CPU set that indicates
which virtual CPUs the thread can run on. The macro CPU_ZERO() clears a CPU set, and the macro CPU_SET() adds a virtual CPU to a CPU set. However, there are a couple of
complexities. First, the macros CPU_ZERO() and CPU_SET() are
defined only if the #define _GNU_SOURCE is set.
To ensure the macros are available, this should be set as the first thing in
the source file or on the compile line. The second issue is that gettid(), which returns the ID of the calling thread, may not be defined in the
system header files. To rectify this, gettid() needs to be explicitly coded. Listing 9.35 shows the complete code to
bind a thread to a particular virtual CPU.
Listing 9.35 Binding
a Thread to a Virtual CPU on Linux
#ifdef linux #include <sched.h>
#include <sys/syscall.h>
pid_t gettid()
{
return syscall( __NR_gettid );
}
int threadbind( int proc )
{
cpu_set_t cpuset; CPU_ZERO( &cpuset ); CPU_SET(
proc, &cpuset );
return sched_setaffinity( gettid(), sizeof(cpu_set_t), &cpuset );
}
#endif
Listing 9.36 shows the equivalent Windows code for these two routines.
The call to GetTickCount() returns a
value in milliseconds rather than the microseconds returned
by gettimeofday().
However, the code runs for sufficiently long enough that this reduction in
accuracy does not cause a problem. The call to bind a thread to a virtual CPU
is SetThreadAffinityMask(), and this call takes a mask where a bit is set for every virtual CPU
where the thread is allowed to run.
Listing 9.36 Windows
Code for Getting Current Time and Binding to a Virtual CPU
#include <stdio.h> #include <windows.h>
#include <process.h>
double
now()
{
return GetTickCount() / 1000.0;
}
int
threadbind( int proc )
{
DWORD_PTR mask; mask = 1<<proc ;
return SetThreadAffinityMask( GetCurrentThread(), mask );
}
Listing 9.37 shows the remainder of the code
modified to compile and run on Windows.
Listing 9.37 Latency
Code for Windows
#include <stdio.h> #include <windows.h>
#include <process.h>
#define SIZE 128*1024*1024 int** memory;
void
setup()
{
int i, j; threadbind( 0 );
memory = (int**)calloc( sizeof(int*), SIZE+1 ); for( j=0; j<16; j++ )
{
for( i=16+j; i<=SIZE; i++ )
{
memory[i] = (int*)&memory[ i-16 ];
}
memory[j] = (int*)&memory[ SIZE-16+j+1 ];
}
}
unsigned
int __stdcall use( void* param )
{
if
( threadbind( (int)param ) != 0 )
{
int* next; int i;
double start = now(); next = memory[0]; for( i=0;
i<SIZE;i++ )
{
next = (int*)*next;
}
if ( (int)next == 1 ) { printf( "a" ); } double end = now();
printf( "Time %14.2f ns Binding
%i/s\n", (end-start)*1000000000.0 / ((double)SIZE), (int)param );
} else { printf( "Error" ); } return 0;
}
int _tmain( int argc, _TCHAR* argv[] )
{
HANDLE thread; int nthreads = 8; int i;
if ( argc > 1 ) { nthreads = _wtoi( argv[1] ); } setup();
for( i=0; i<nthreads; i++ )
{
thread = (HANDLE)_beginthreadex( 0, 0, &use, (void*)i, 0, 0 );
WaitForSingleObject( thread, INFINITE );
CloseHandle( thread );
}
getchar(); return 0;
}
Listing 9.38 shows the results of
running the latency test code on a Solaris system where there are two chips
each with associated local memory. In this instance, the remote memory latency
is 50% greater than the local memory latency.
Listing 9.38 Latency
on Solaris System with Two Memory Locality Groups
$ ./a.out 4
Time 98.24 ns Binding 0/s
Time 145.69 ns Binding 1/s
Although it is tempting to use processor binding to get the best
possible performance from an application, it is not a general-purpose solution.
On a shared system, it is relatively easy to end up with multiple applications
bound to the same group of virtual CPUs. This would result in reduced
performance for all the threads bound to shared vir-tual CPUs and an
inefficient use of the system’s resources. This is why it is usually best to
let the operating system manage resources. For situations where some kind of
static allo-cation of threads to virtual CPUs is desirable, it may be worth
investigating some of the virtualization or resource allocation facilities
provided by the operating system. There may be a way to divide the resources
between applications without running the risk that some of the resources might
be oversubscribed and some undersubscribed.
There is a potentially interesting situation when
binding threads to virtual CPUs on a processor. If threads work on the memory
regions with close proximity, then best per-formance will be obtained when
these threads are bound to cores with close proximity. This binding would
ensure that data that is shared between the threads ends up in caches that are
also shared. As an example, thread 0 and thread 1 might access a set of overlap-ping
array elements. If thread 0 happens to fetch all the elements into cache, then
thread 1 may be able to access them from there, rather than also having to
fetch them from memory.
However, consider the situation where work is
unevenly distributed between the threads. Suppose the amount of work done by
each thread diminishes such that thread 0 does the most work and thread 15 does
the least work. If threads 0 and 1 are bound to virtual CPUs on the same core,
then both threads will be competing for pipeline resources and will
consequently run slowly. On the other hand, if thread 0 were paired with thread
15, then thread 15 would rapidly complete its work leaving all the resources of
the core available for use by thread 0.
Processor binding is not something that should be
undertaken without some careful consideration of the situation. Although it has
the potential to improve performance, it also restricts the freedom of the
operating system to dynamically schedule for best per-formance, and this can
lead to the bound application taking many times longer than its unbound
runtime.
Priority
Inversion
All processes and threads can have some associated priority. The
operating system uses this to determine how much CPU time to assign to the
thread. So, a thread with a higher priority will get more CPU time than a
thread with a lower priority. This enables the developer to determine how time
is distributed between the threads that comprise an application.
For
example, the threads that handle the user interface of an application are often
assigned a high priority. It is important for these threads to accept user
input and refresh the screen. These activities make the application feel
responsive to the user. However, the application might also need to be doing
some background processing. This background processing could be quite compute
intensive. Run at a low priority, the background task gets scheduled into the
gaps where the interface does not need attention. If it were scheduled with a
high priority, then it would be competing with the user interface threads for
compute resources, and there would be a noticeable lag between the user
performing an action and the application responding.
One problem with priority is that of priority
inversion, where one thread is waiting for the resources held by another
thread. If the thread holding the resources is of lower priority, then the
priority is said to be inverted.
A potential issue in this
situation is when a low-priority thread holds a mutex. A thread with a higher
priority wakes up and causes the low-priority thread to be descheduled from the
CPU. The thread waiting for the mutex could be of an even higher priority, but
it will now have to wait for both the lower-priority threads to com-plete
before it can acquire the mutex.
A common solution for this
problem is for the thread holding the resources to tem-porarily acquire the max
priority of the waiting threads, ideally reducing the time that it holds the
resources. Once the thread releases the resources, it resumes its original
lower priority, and the higher-priority thread continues execution with its
original higher priority.
An alternative solution is to
boost the priority of any thread that acquires a particular resource so that
the thread is unlikely to be preempted while it is holding the resource.
Related Topics