Chapter: Principles of Compiler Design : Lexical Analysis
Input Buffering
INPUT BUFFERING
The lexical analyzer
scans the characters of the source program one a t a time to discover tokens.
Often, however, many characters beyond the next token many have to be examined
before the next token itself can be determined. For this and other reasons, it
is desirable for the lexical analyzer to read its input from an input buffer.
Fig. 1.9 shows a buffer divided into two halves of, say 100 characters each.
One pointer marks the beginning of the token being discovered. A look ahead
pointer scans ahead of the beginning point, until the token is discovered .we
view the position of each pointer as being between the character last read and
the character next to be read. In practice each buffering scheme adopts one
convention either a pointer is at the symbol last read or the symbol it is
ready to read.
The distance which the
lookahead pointer may have to travel past the actual token may be large. For
example, in a PL/I program we may see:
DECLARE (ARG1, ARG2… ARG n)
Without knowing whether
DECLARE is a keyword or an array name until we see the character that follows
the right parenthesis. In either case, the token itself ends at the second E.
If the look ahead pointer travels beyond the buffer half in which it began, the
other half must be loaded with the next characters from the source file.
Since the buffer shown
in above figure is of limited size there is an implied constraint on how much
look ahead can be used before the next token is discovered. In the above
example, if the look ahead traveled to the left half and all the way through
the left half to the middle, we could not reload the right half, because we
would lose characters that had not yet been grouped into tokens. While we can
make the buffer larger if we chose or use another buffering scheme, we cannot
ignore the fact that overhead is limited.
BUFFER PAIRS
·
A buffer is divided into two N-character
halves, as shown below
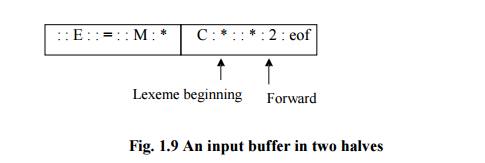
Fig.
1.9 An input buffer in two halves
Each buffer is of the same size N, and N is usually
the number of characters on one block. E.g., 1024 or 4096 bytes.
·
Using one system read command we can
read N characters into a buffer.
·
If fewer than N characters remain in the
input file, then a special character, represented by eof, marks the end
of the source file.
·
Two pointers to the input are
maintained:
1. Pointer
lexeme_beginning, marks the beginning of the current lexeme, whose
extent we are attempting to determine.
2.Pointer forward
scans ahead until a pattern match is found.
Once the next lexeme is determined, forward is set
to the character at its right end.
·
The string of characters between the two
pointers is the current lexeme.
After the lexeme is
recorded as an attribute value of a token returned to the parser,
lexeme_beginning is set to the character immediately after the lexeme just
found.
Advancing forward pointer:
Advancing forward
pointer requires that we first test whether we have reached the end of one of
the buffers, and if so, we must reload the other buffer from the input, and
move forward to the beginning of the newly loaded buffer. If the end of second
buffer is reached, we must again reload the first buffer with input and the
pointer wraps to the beginning of the buffer.
Code to advance forward pointer: if
forward at end
of first half then begin reload second
half;
forward := forward + 1 end
else if forward at end of second half
then begin reload second half;
move forward to beginning of first half
end
else
forward := forward + 1;
Sentinels
For each character
read, we make two tests: one for the end of the buffer, and one to determine
what character is read. We can combine the buffer-end test with the test for
the current character if we extend each buffer to hold a sentinel character at
the end.
The sentinel is a
special character that cannot be part of the source program, and a natural
choice is the character eof.
The
sentinel arrangement is as shown below:
:
: E : : = : : M : * : eof C : * : : * : 2 : eof : : : eof
Fig.
1.10 Sentinels at end of each buffer half
Note that eof retains
its use as a marker for the end of the entire input. Any eof that appears other
than at the end of a buffer means that the input is at an end.
Code to advance forward pointer: forward
: = forward + 1;
if
forward ↑ = eof then begin
if forward at end of first half then
begin reload second half; forward := forward +
1
end
else if forward at end of second half
then begin reload first half;
move forward to beginning of first half
end
else /* eof within a buffer signifying
end of input */ terminate lexical analysis
end
Related Topics