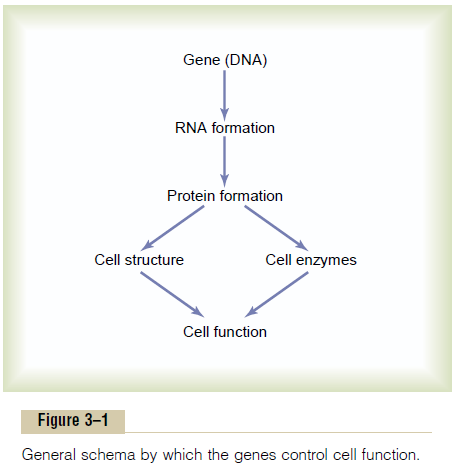
Chapter: Medical Physiology: Introduction to Physiology: Genetic Control of Protein Synthesis, Cell Function, and Cell Reproduction
Genes in the Cell Nucleus
Genes in the Cell Nucleus
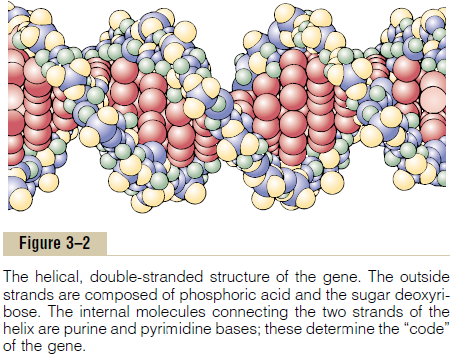
In the cell nucleus, large numbers of genes are attached end on end in extremely long double-stranded helical molecules of DNA having molecular weights measured in the billions. A very short segment of such a molecule is shown in Figure 3–2. This molecule is composed of several simple chemical compounds bound together in a regular pattern, details of which are explained in the next few paragraphs.
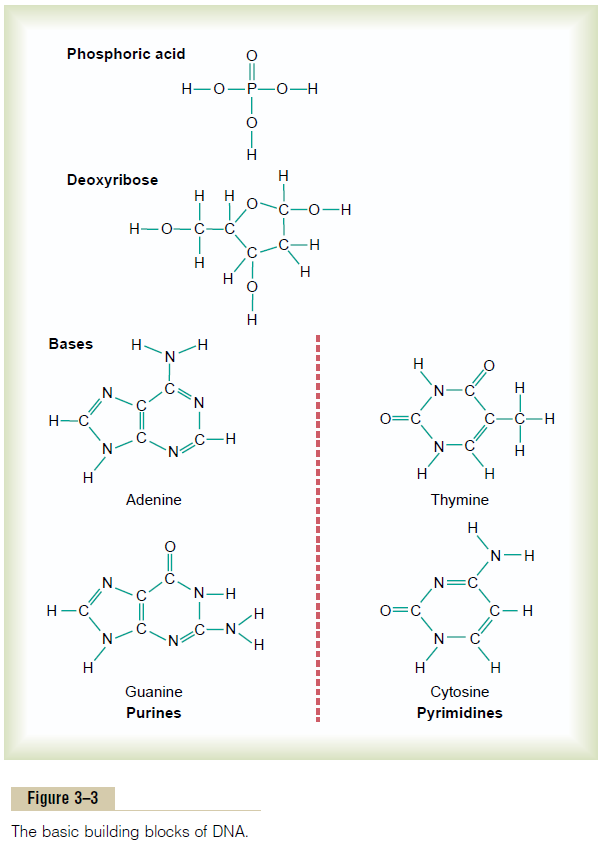
Basic Building Blocks of DNA. Figure 3–3 shows the basic chemical compoundsinvolved in the formation of DNA. These include (1)phosphoric acid, (2) a sugar called deoxyribose, and (3) four nitrogenous bases (two purines, adenine and guanine, and two pyrimidines, thymine and cytosine). The phosphoric acid and deoxyribose form the two helical strands that are the backbone of the DNA molecule, and the nitrogenous bases lie between the two strands and connect them, as illustrated in Figure 3–6.
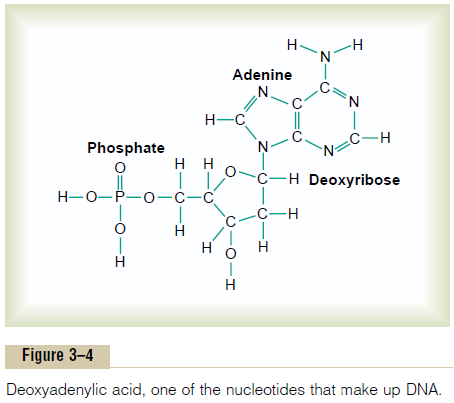
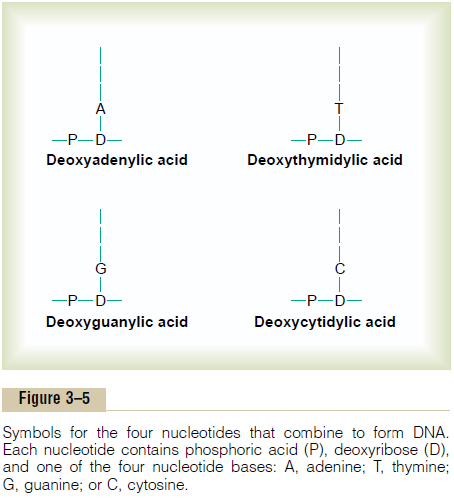
Nucleotides. The first stage in the formation of DNA is to combine one mole-cule of phosphoric acid, one molecule of deoxyribose, and one of the four bases to form an acidic nucleotide. Four separate nucleotides are thus formed, one for each of the four bases:deoxyadenylic, deoxythymidylic, deoxyguanylic, and deoxycytidylic acids. Figure 3–4 shows the chemical structure of deoxyadenylicacid, and Figure 3–5 shows simple symbols for the four nucleotides that form DNA.
Organization of the Nucleotides to Form Two Strands of DNA Loosely Bound to Each Other.
Figure 3–6 shows the manner in which multiple numbers of nucleotides are bound together to form two strands of DNA. The two strands are, in turn, loosely bonded with each other by weak cross-linkages, illustrated in Figure 3–6 by the central dashed lines. Note that the backbone of each DNA strand is comprised of alternating phosphoric acid and deoxyribose molecules. In turn, purine and pyrimidine bases are attached to the sides of the deoxyribose molecules. Then, by means of loose hydrogen bonds (dashed lines) between the purineand pyrimidine bases, the two respective DNA strands are held together. But note the following:
1. Each purine base adenine of one strand always bonds with a pyrimidine base thymine of the other strand, and
2. Each purine base guanine always bonds with a pyrimidine base cytosine.
Thus, in Figure 3–6, the sequence of complementary pairs of bases is CG, CG, GC,TA, CG,TA, GC,AT, and AT. Because of the looseness of the hydrogen bonds, the two strands can pull apart with ease, and they do so many times during the course of their function in the cell.
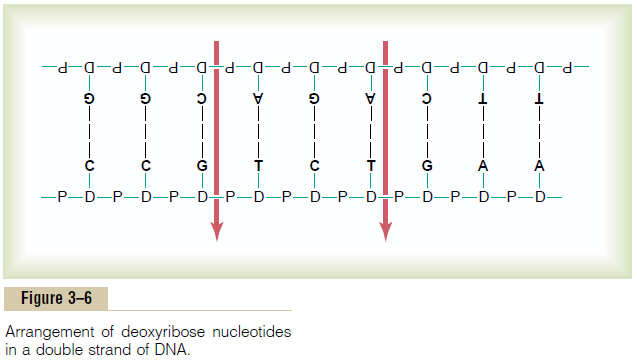
To put the DNA of Figure 3–6 into its proper phys-ical perspective, one could merely pick up the two ends and twist them into a helix. Ten pairs of nucleotides are present in each full turn of the helix in the DNA molecule, as shown in Figure 3–2.
Genetic Code
The importance of DNA lies in its ability to control the formation of proteins in the cell. It does this by means of the so-called genetic code. That is, when the two strands of a DNA molecule are split apart, this exposes the purine and pyrimidine bases projecting to the side of each DNA strand, as shown by the top strand in Figure 3–7. It is these projecting bases that form the genetic code.
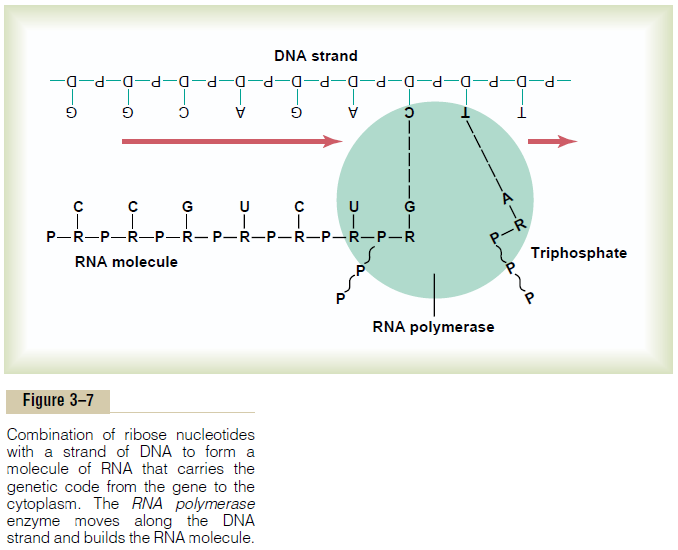
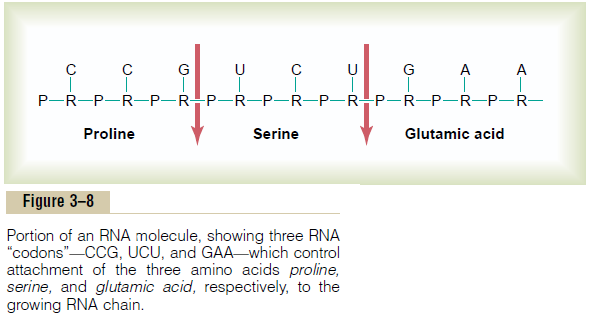
The genetic code consists of successive “triplets” of bases—that is, each three successive bases is a codeword. The successive triplets eventually control thesequence of amino acids in a protein molecule that is to be synthesized in the cell. Note in Figure 3–6 that the top strand of DNA, reading from left to right, has the genetic code GGC, AGA, CTT, the triplets being separated from one another by the arrows. As we follow this genetic code through Figures 3–7 and 3–8, we see that these three respective triplets are respon-sible for successive placement of the three amino acids, proline, serine, and glutamic acid, in a newly formed molecule of protein.
Related Topics